インターネット上には、さまざまなWebサイトやSNSで公開されている画像が数多く存在します。例えば、食べ物の写真、美しい風景の写真、お気に入りの芸能タレントの写真など、ジャンルも多岐にわたります。
また、フリー素材サイトを利用すれば、無料で高品質な画像をダウンロードすることも可能です。
しかし、これらの画像を一括で保存しようとすると、一つひとつ手作業でファイルに保存しなければなりません。
そこで本記事では、Webサイトの画像を効率的にダウンロードする5つの方法を紹介します。
ブラウザの拡張機能で画像を一括ダウンロードする方法
単一のWebページから画像をダウンロードしたい場合は、Webブラウザの拡張機能を使うのが最も手軽な方法です。拡張機能を利用することで、画像の取得を自動化し、効率的にダウンロードできます。
ここでは、代表的な2つのブラウザ(FirefoxとChrome)で画像を一括ダウンロードする方法を紹介します。
Firefoxで画像を保存する方法
Firefox(ファイアフォックス)は、Mozilla Foundationが開発・提供している、オープンソースのWebブラウザです。カスタマイズ性が高く、「アドオン」と呼ばれる拡張機能を追加することで、機能を拡張できます。
<手順>
- Firefoxのインストール
Firefoxをダウンロードしていない場合、こちらからダウンロードしてください。 - 拡張機能「DownThemAll!」を追加
Firefoxでブラウザを開き、ADD-ONS(アドオンストアページ)から「DownThemAll!」をダウンロードします。 DownThemAll!のダウンロードはこちら
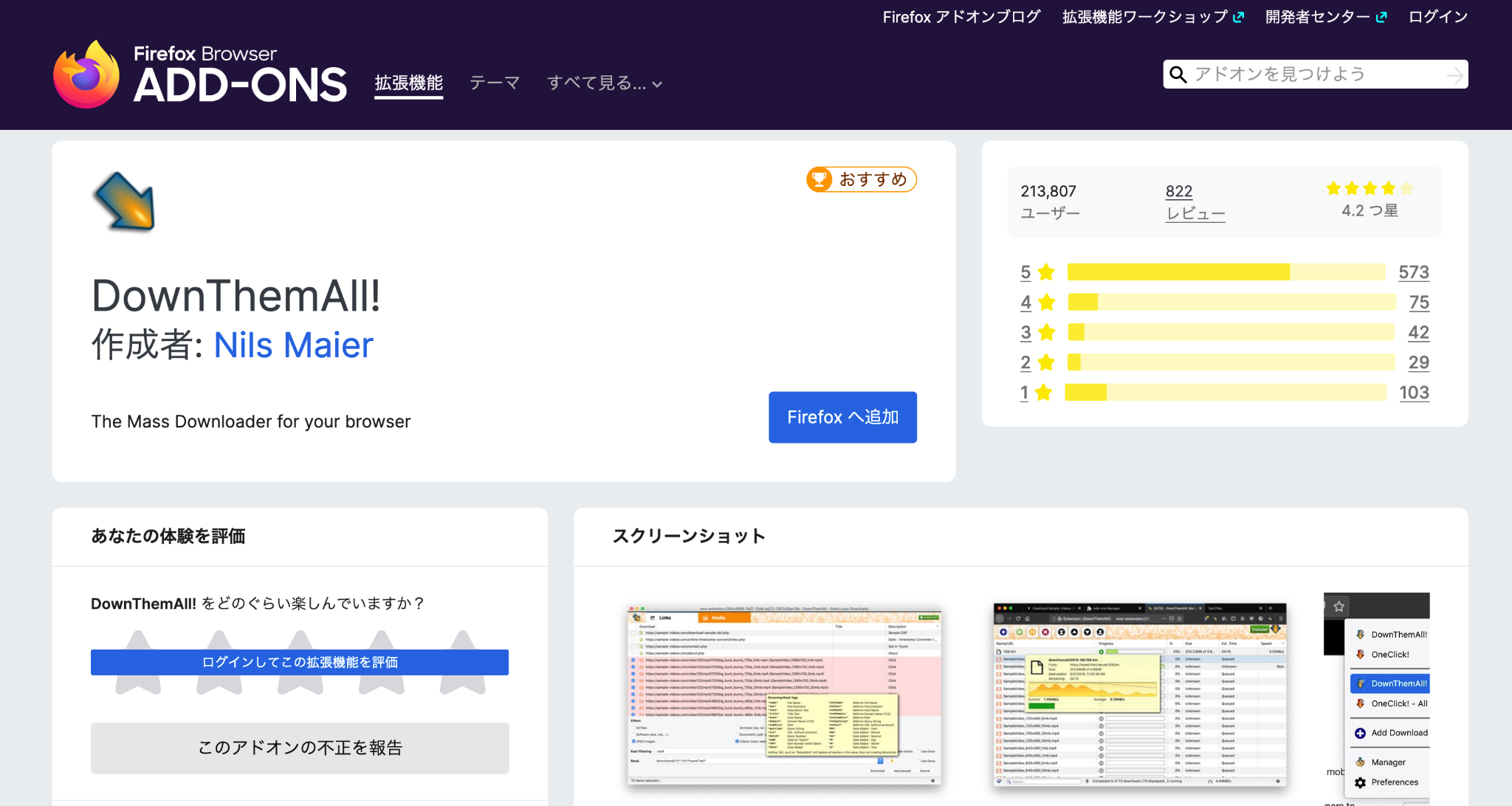
- 画像をダウンロードしたいページを開く
- DownThemAll!のインストールが完了後、画像を一括ダウンロードしたいサイトを開きます。例えば、Pinterestのような画像共有サイトを開いてみましょう。
- DownThemAll!を起動
- ページ上で右クリックし、メニューから「DownThemAll!」を選択します。
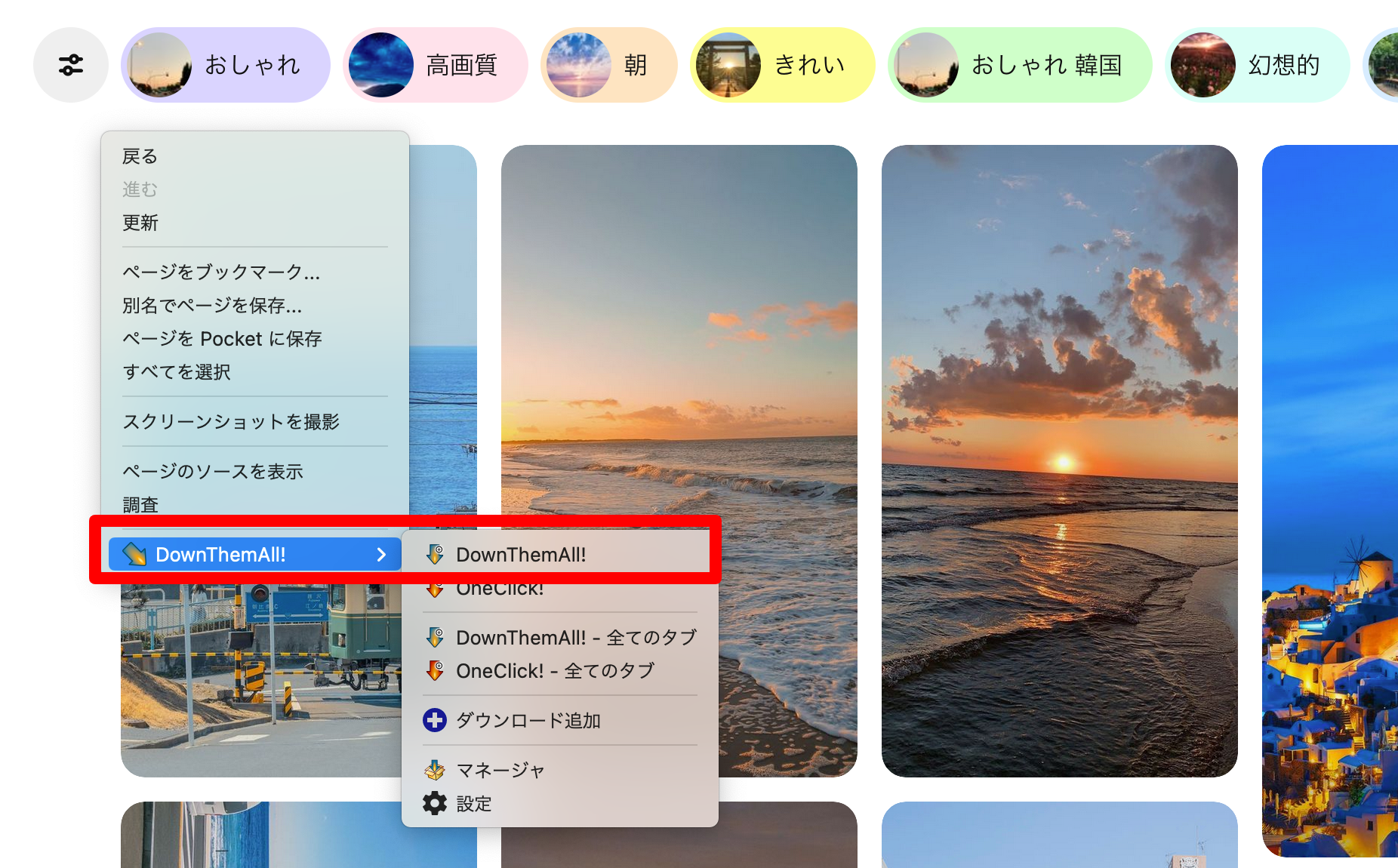
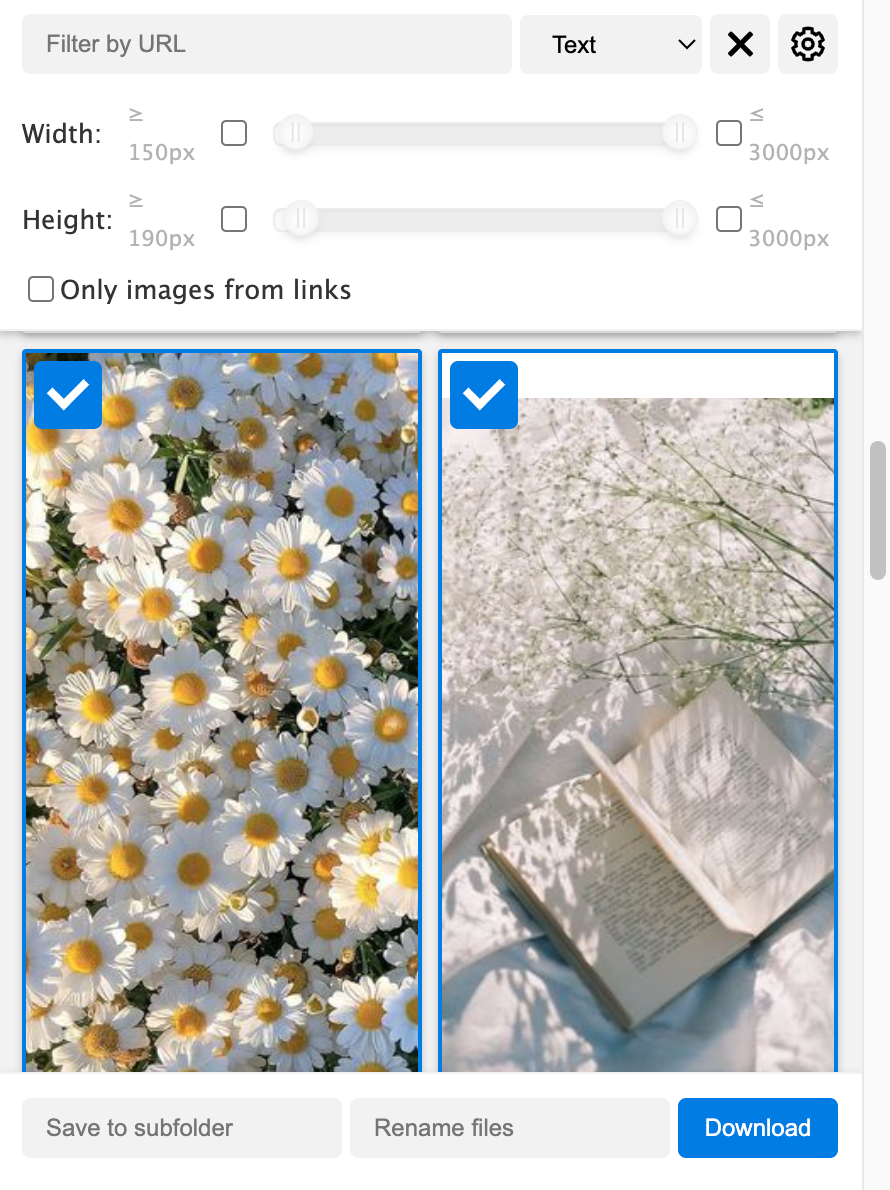
- ダウンロードする画像を選択
- 「マスク」タブを開き、リストに表示される画像ファイルのチェックボックスをオンにするか、フィルタを使用して全選択します。
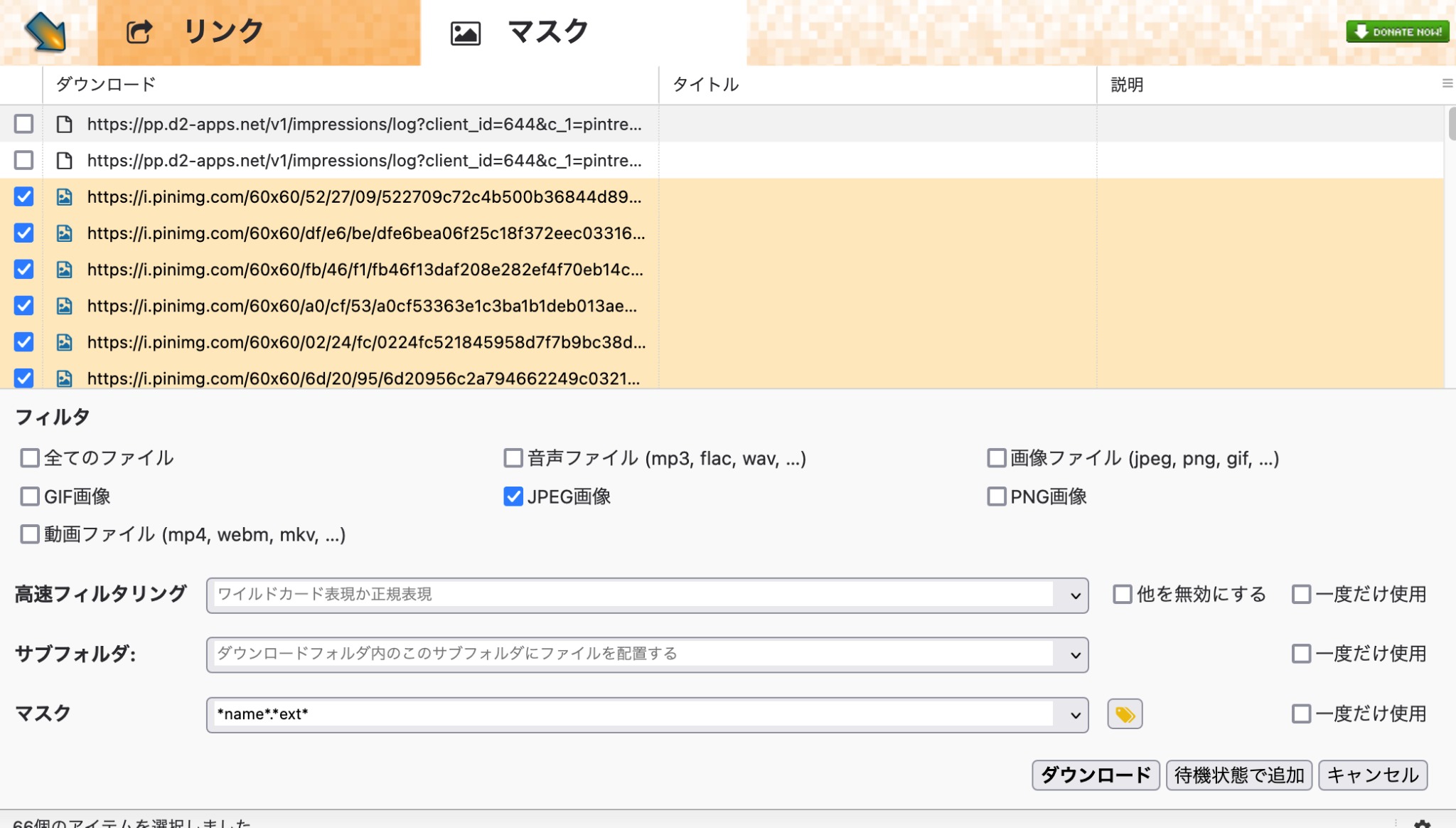
- ダウンロードの実行
- 画面右下の「ダウンロード」ボタンをクリックすると、選択した画像がまとめて保存されます。

Chromeで画像を保存する方法
Chromeは、Googleが開発・提供する人気のWebブラウザです。拡張機能を追加することで、必要な機能を自由に追加できます。
今回は、Chromeの拡張機能「Image downloader」を使用して画像を一括ダウンロードする方法を紹介します。その他のChrome拡張機能は、こちらの記事でも紹介していますので参考にしてください。
<手順>
- 拡張機能「Image downloader」を追加
- Chromeウェブストアから「Image downloader」を追加します。
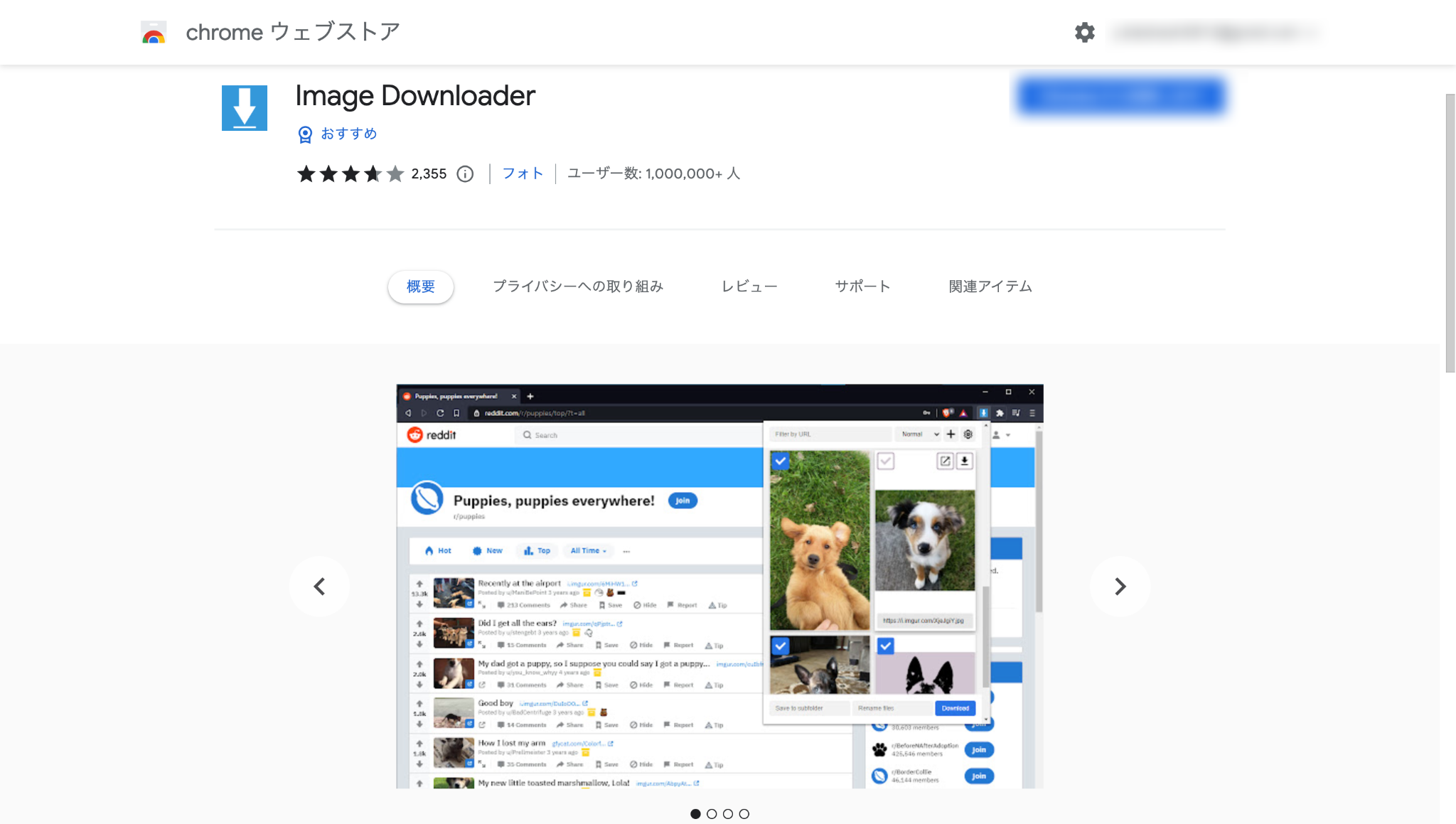
- 画像をダウンロードしたいWebサイトを開く
- Chromeブラウザで画像を取得したいWebサイトを開きます。今回もDownThemAll!と同様に、Pinterestの画像を開きます。
- Image downloaderを起動
- ブラウザのツールバーにある拡張機能のアイコンから「Image downloader」をクリックします。
- ダウンロードする画像を選択
- 表示されたウィンドウ内にて、ダウンロードしたい画像にチェックを入れます。
- ダウンロードの実行
- 「Download」ボタンをクリックすると、選択した画像が一括ダウンロードされます。
オンラインサービスで画像を一括ダウンロードする方法
ブラウザ拡張機能を使わずに、Webサイトの画像を一括ダウンロードしたい場合は、オンラインサービスがおすすめです。オンラインサービスであれば、ブラウザの種類を問わず利用でき、無料で使えるものも数多くあります。
Image CyborgでWebページの画像を保存する方法
ブラウザの拡張機能を使う方法は、単一のWebページの画像を保存する際には便利ですが、複数のWebページから大量の画像を一括ダウンロードする場合には不向きです。
そのような場合に役立つのが「Image Cyborg」というオンラインサービスです。
Image Cyborgは、指定したWebページ内に含まれる画像を自動で取得し、ZIP形式でまとめてダウンロードできるサービスです。
<手順>
- Image Cyborgにアクセスする
- 入力フォームに一括ダウンロードしたいWebページを貼り付ける
- Download Imageをクリックする
- zip形式で画像が一括ダウンロードされる
スクレイピングで画像を一括ダウンロードする方法
Webスクレイピングツールは、Webページ上のあらゆるデータを自動で収集するツールです。Webスクレイピングツールを使えば、Pythonなどのプログラミングなしで誰でも簡単に利用できます。
Octoparseを使って画像を保存する方法
Octoparse(オクトパス)は、プログラミング不要でWebサイトの情報を自動取得できるスクレイピングツールです。Octoparseを活用することで、Web上の画像を効率的に取得できます。
今回は、画像取得に役立つOctoparseの活用方法をご紹介します。
<Octoparseの利用シーン>
- 複数ページにまたがる画像の取得
- Webサイトによってはページネーションがあり、画像を取得するには1ページずつ移動する必要があります。Octoparseは、自動でページを切り替えながら画像URLを収集できるため、手作業を省略できます。
- 無限スクロールのページからの画像取得
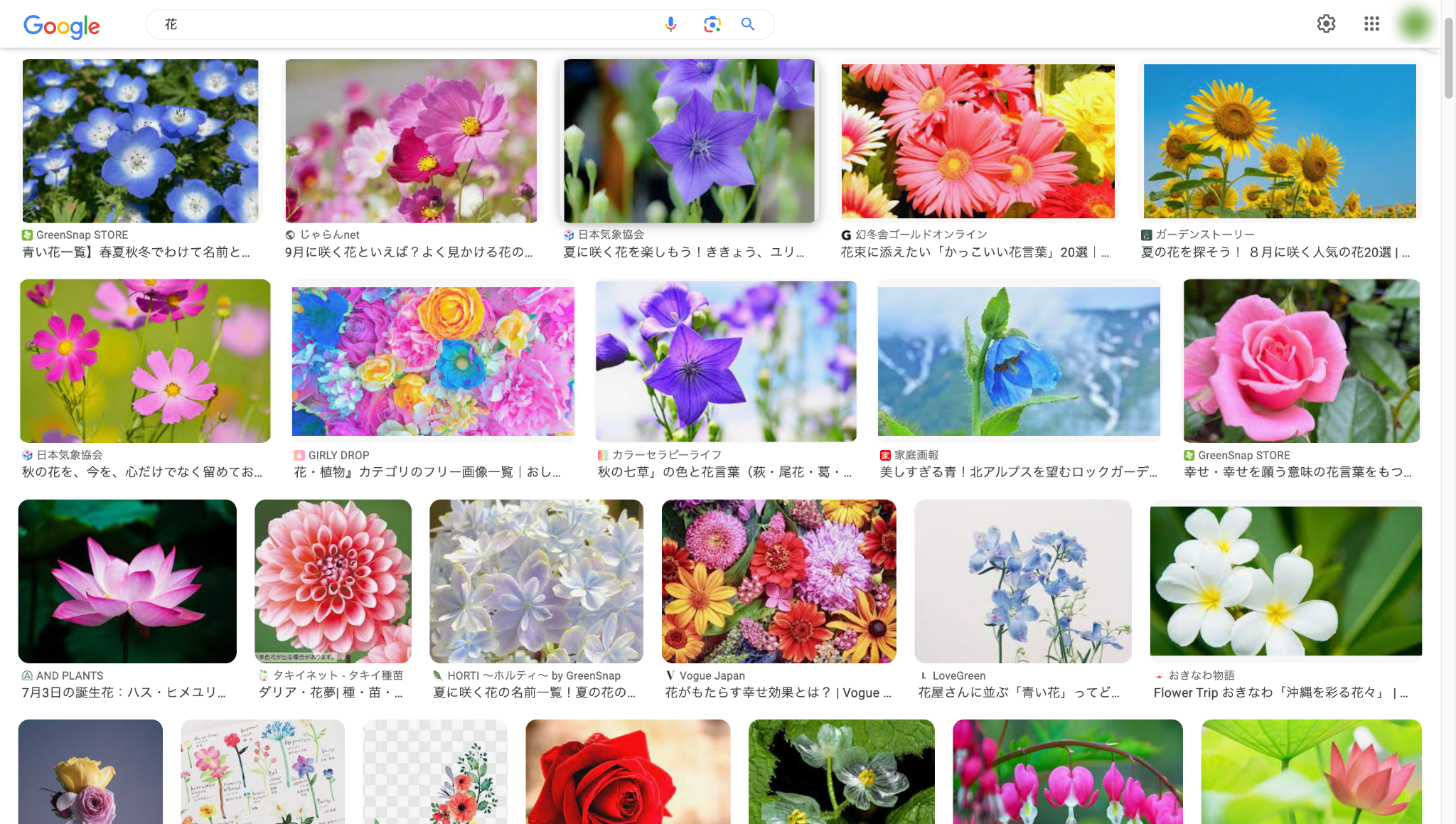
- Google画像検索やSNSなどのように、スクロール操作をしないと新しい画像が表示されないサイトにも対応可能です。Octoparseは人間のスクロール操作をシミュレートできるため、すべての画像を一括取得できます。
- 画像と関連情報をセットで収集
- 商品画像や求人サイトのバナー画像など、Webサイトにはさまざまな画像が含まれています。Octoparseなら、画像だけでなく、商品名・価格・レビュー数などの関連情報も同時に取得できます。ECサイトの競合調査やマーケティング分析にも役立ちます。
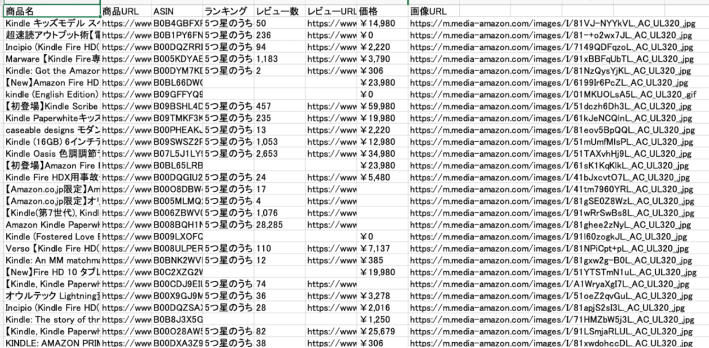
- その他にも、求人サイトであれば、募集職種、給与、待遇などの情報を一括で取得することが可能です。抽出したデータは市場分析、競合分析、営業リストの作成などに活用できます。
以下の記事では、Octoparseを使って楽天市場から画像を一括保存する方法を解説しています。プログラミング不要で、数回のクリックと簡単な操作だけでスクレイピングができるので、ぜひ参考にしてください。
Pythonスクリプトで画像を一括ダウンロードする方法
Pythonスクリプトで画像を一括ダウンロードする方法
Pythonスクリプトを使うと、ウェブページから画像を自動的に一括ダウンロードすることができます。
<手順>
- ライブラリのインストール
はじめに、スクレイピング用のライブラリをインストールします。
- スクリプトの実行
次に、以下のコードを貼り付けて実行します。今回は、本記事の画像を取得してみます。
- 取得画像の確認
- スクリプトの実行後、保存された画像を確認します。
- 今回は、手軽にPythonのコードを試せる Google Colab を使用しました。
- 左側の”downloaded_images” フォルダに一覧が表示されます。各画像は、フォルダを開くことで個別に確認可能です。
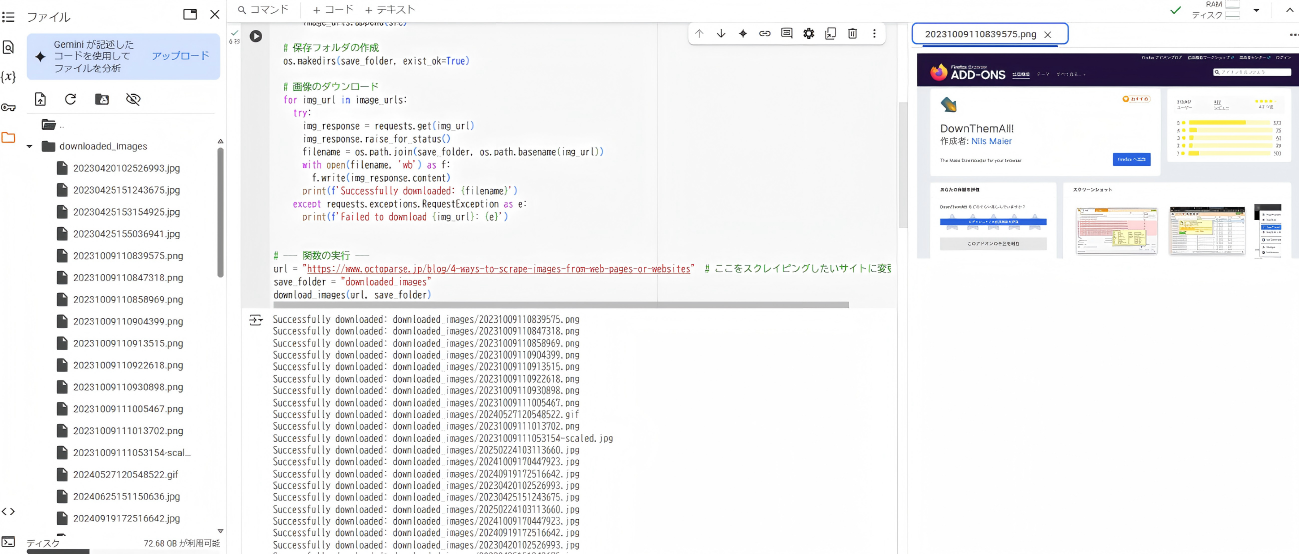
このスクリプトは、Webページ上の画像を自動で検出し、指定したローカルフォルダに保存する基本的な機能を備えています。また、ダウンロード時のエラー処理を行い、処理の進行状況をリアルタイムで確認できるため、効率的に画像を取得できます。
さらに、用途や環境に応じて上記コードに調整を加えることで、柔軟な運用が可能になります。例えば、短時間に大量のリクエストを送ることを避けるために、一定の間隔を空けて処理を実行することで、サーバー負荷を軽減できます。さらに、対象サイトの robots.txt を確認し、ルールに沿った運用を行うことで、より適切なデータ取得が可能になります。
まとめ
今回は、Webページ上の画像を一括保存する5つの方法を紹介しました。シンプルに画像を取得するならブラウザ拡張機能やオンラインツール、より柔軟なカスタマイズが必要ならPythonスクリプトが有効です。
また、画像データと関連情報を同時に収集する場合は、Octoparse のようなスクレイピングツールが適しています。目的に応じて最適な手法を選び、効率的なデータ取得を実現しましょう。

ウェブサイトのデータを、Excel、CSV、Google Sheets、お好みのデータベースに直接変換。
自動検出機能搭載で、プログラミング不要の簡単データ抽出。
人気サイト向けテンプレート完備。クリック数回でデータ取得可能。
IPプロキシと高度なAPIで、ブロック対策も万全。
クラウドサービスで、いつでも好きな時にスクレイピングをスケジュール。



