Octoparseをはじめとする「Webスクレイピングツール」の登場により、多くの分野でWebスクレイピングの活用が進んでいます。スクレイピング自体は違法ではありませんが、一部のWebサイトでは、利用規約によってスクレイピング行為を明確に禁止している場合があります。
Webスクレイピングは便利な一方で、実行時に検出されるとアクセス制限やブロックの対象となることがあります。そこで本記事では、スクレイピングをバレないようにするための5つの対策を解説します。
また、Webスクレイピングの利用に不安を感じる方は以下の記事もあわせてご参照ください。
スクレイピングは違法?Webスクレイピングに関する10のよくある誤解!
スクレイピングとは
スクレイピングとは、Webサイト上のデータを自動的に抽出する技術です。この技術を活用することで、手作業では取得が困難な大量の情報を、短時間で効率的に収集できます。例えば、商品の価格情報やレビュー、競合他社の動向など、さまざまなデータを効率よく取得し、マーケティングやリサーチに活用可能です。
一方で、スクレイピングを行う際には注意も必要です。過剰なアクセスにより対象サーバーへ過度な負荷がかかると、最悪の場合はサーバーダウンを招くおそれがあります。
こうした背景から、Webサイトの所有者側も対策を強化しており、多くのサイトではスクレイピング防止技術が導入されています。その結果として、Webスクレイピングはより困難になっています。また、Webサイト所有者がスクレイピングを悪質であると判断した場合には、損害賠償責任や偽計業務妨害罪に問われるリスクもあります。
スクレイピングのメリット
ルールを守ってスクレイピングを行えば、業務の効率化や意思決定の精度向上につながります。
ここでは、ビジネスやリサーチの現場で注目されている、スクレイピングのメリットをご紹介します。
データ収集効率化
スクレイピングの最大のメリットは、データ収集の効率化です。手作業で行う場合、多くの時間と労力を要するデータ収集も、スクレイピングツールを使えば自動的に短時間で完了します。
例えば、数百件の商品価格を手作業で調査するのは非効率であり、業務委託やアルバイトを使う場合は人件費の負担が発生します。スクレイピングを活用すれば、必要なデータを短時間で一括取得でき、コストを抑えつつ作業の自動化が実現できます。業務の効率化によって、戦略立案や意思決定のスピードも向上します。
APIが共有していないデータを取得できる
多くのウェブサービスはAPIを提供していますが、全てのデータがAPI経由で取得できるわけではありません。スクレイピングを利用すれば、画面上に表示されている情報を直接取得できるため、APIが提供していないデータも取得可能です。
例えば、特定の商品の詳細なレビューや、ユーザーコメントなど、APIでは取得できない情報もスクレイピングであれば収集することができます。これにより、より豊富なデータセットを活用して、精緻な分析やインサイトの獲得が可能となります。
ビジネスや研究で広範に利用できる
スクレイピングは、ビジネスや研究の現場で幅広く活用されています。たとえば、競合分析、市場調査、SEO対策などの分野では、公開されているWebデータをもとに状況を把握し、施策の検討や動向の把握に利用されています。
また、スクレイピングはAI分野においても重要な手段の一つです。自然言語処理や画像認識などのモデルを訓練する際、大量の教師データを収集する必要があり、Web上のデータを効率的に取得する方法として活用されています。
スクレイピングのデメリット
スクレイピングには多くのメリットがある一方で、デメリットも存在します。ここでは、スクレイピングのデメリットをご紹介します。
技術の習得に時間がかかる
スクレイピングを行うためには、ITの知識が必要不可欠です。具体的には、サーバーやプログラミングの理解や、Webページの構造を示すHTMLやCSSの内容を読み解く力が求められます。
また、Webサイトごとに異なるページ構成に対応したスクリプトの作成や、アクセス制限への対策も必要です。これらの作業を実務で活用できるレベルまで習得するには、時間と労力が必要です。そのため、限られた期間で導入し、実用的な成果を上げることは困難と言えるでしょう。
継続的なメンテナンスが必要
スクレイピングは初期構築を行えば終わりというものではなく、継続的なメンテナンスが必要です。多くのWebサイトは、定期的にHTML構造やクラス名、ページ構成を変更しており、それに伴ってスクレイピングスクリプトが正常に動作しなくなる可能性があります。
そのため、スクレイピングを安定的に運用するには、定期的な動作確認やコードの修正が不可欠です。
リソースによる制限
スクレイピングツールを安定して運用するには、利用するPCの処理能力やインターネット環境も重要です。スペックが不足している場合、処理が途中終了する場合やデータが上手く保存されない場合があります。また、動作中はPCを停止できないため、業務に支障が出ることもあります。
他にも、社内LANを利用している場合は、他の業務システムに影響を及ぼす可能性もあるため、スクレイピングを実行する時間帯や頻度には配慮が必要です。安定した運用のためには、ツールの仕様だけでなく、実行環境にも目を向ける必要があります。
スクレイピングがバレる原因とは
スクレイピングがWebサイト側に検知される主な理由は、その挙動に特有の「不自然さ」があるためです。例えば、以下のような行動パターンは人間のブラウジングとは異なるため、Botによるアクセスと判断されやすくなります。
- 過剰なリクエスト頻度
短時間に大量のリクエストを送信すると、不審なトラフィックとして検知されやすくなります。人間であればページ間の閲覧に数秒~数十秒の間が空くのが自然ですが、Botは数ミリ秒~数秒間隔で次々とアクセスすることが多く、不自然な速度と判断されます。
- 一定パターンのアクセス
決まったURL構造を順番通りに巡回する、毎回同じ時間にアクセスしてくるなど、機械的な挙動も検出の対象となります。
- ヘッダー情報の不備
User-Agentが設定されていない、あるいは初期設定のままの場合、Webサイト側にプログラムによるアクセスだと見抜かれる可能性があります。
User-Agentとは、アクセスしている端末やブラウザの種類をWebサイトに伝えるための情報です。通常のブラウザからのアクセスでは、ChromeやSafariなどの情報が自動的に送られますが、初期状態のままの場合、「これは人間ではなく、プログラムからのアクセスである」と判断され、ブロックの対象になる場合となります。
スクレイピングがバレるとどうなる
スクレイピングは多くの場面で活用されていますが、実行時にWebサイト側に検知されると、技術的な制限だけでなく、法的・社会的なリスクが生じる可能性があります。ここでは、スクレイピングがバレた際の影響について解説します。
- アクセスの制限やブロック
スクレイピングが検知されると、対象のWebサイトからのアクセスが制限される可能性があります。多くのサイトでは、ボットによるアクセスを防ぐため、IPアドレスのブロックやCAPTCHAの導入といった自動遮断の仕組みを備えています。これにより、スクレイピングの途中で処理が中断され、継続的なデータ取得が困難になるケースがあります。
- 法的リスク
スクレイピング自体は違法ではありませんが、Webサイトの利用規約に違反している場合、法的措置の対象となることがあります。例えば、許可なく個人情報や著作権で保護されたコンテンツを取得した場合には、警告や訴訟などに発展するリスクがあります。実際に、ビジネスSNS「LinkedIn」では、外部企業によるスクレイピング行為が訴訟に発展し、最終的に和解が成立した事例もあります。技術的に取得可能であっても、対象サイトの規約や関連法令の確認は必須です。
- ブランドイメージの損失
スクレイピングが外部に知られた場合、たとえ違法性がなくても、倫理的な観点から信頼を損なう可能性があります。特に、個人情報を含むデータの無断取得や、競合他社の情報を収集していた場合などは、ビジネス上の信用や対外的な評価に影響を及ぼすおそれがあります。
スクレイピングをバレないようにする方法・対策5選
スクレイピングを実施するには、Webサイト側に検出されないよう工夫することが重要です。ここからは、検知を回避するための代表的な対策を5つご紹介します。これらの対策を実施することで、ブロックのリスクを抑え、より安定したデータ取得が可能となります。
また、スクレイピングツールであるOctoparseには、こうした検出リスクを軽減するための機能が複数搭載されています。各対策ごとに、Octoparse上で活用できる機能もあわせて解説しますので、スクレイピング業務の効率化を検討されている方は、ツール活用の参考としてください。
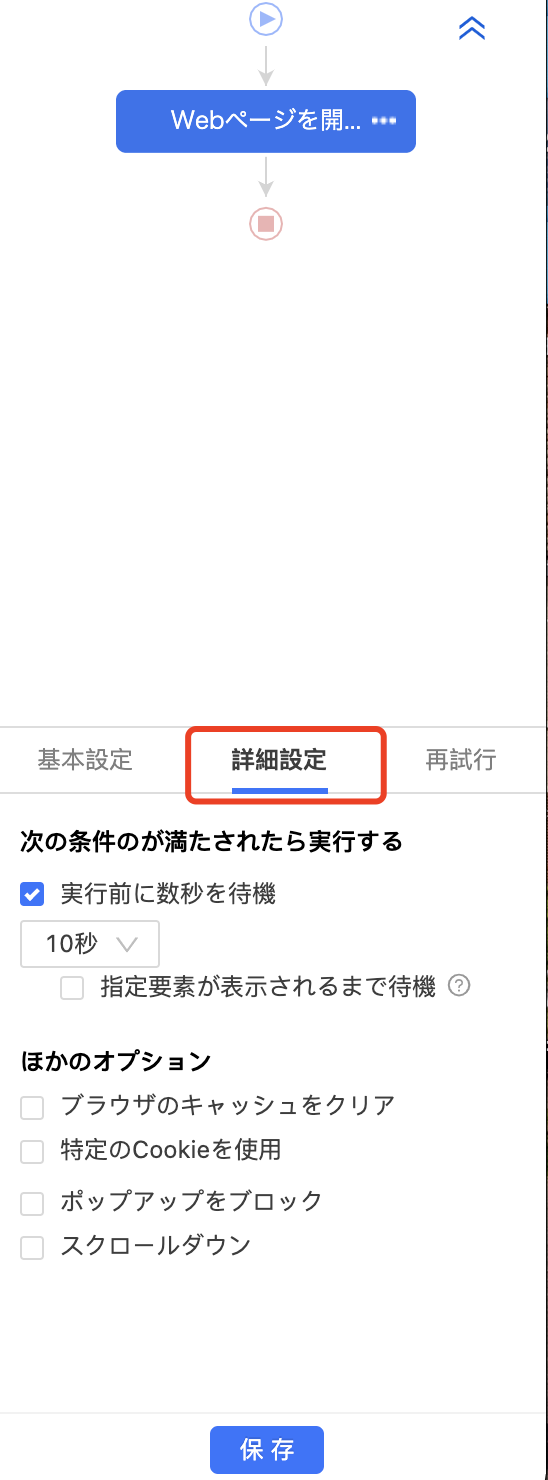
1. スクレイピングの速度を調整する
スクレイピングは、効率的なデータ取得を目的としているため、高速に実行されるケースが多く見られます。しかし、アクセスの頻度が高すぎる場合、Webサイト側からBotによる自動アクセスと判断されるおそれがあります。
例えば、F5社のBIG-IP ASMでは、「30秒間に最大120回のページリフレッシュ」または「30秒間に30ページ以上の異なるページ読み込み」を、Bot検出のデフォルト値として設定されています。これらの基準を超えるアクセスは、不正な自動取得として制限の対象となることがあります。
このような検知を避けるためには、リクエストの間隔を適切に調整し、Webサイトに過度な負担を与えないことが重要です。
Octoparseでは、各ステップの実行間隔に待機時間を設定できます。また、「ランダム待機時間」を有効にすることで、人間に近いアクセスパターンを再現し、検出リスクの軽減が可能です。
2. プロキシサーバーを使う
スクレイピングにおいて、すべてのリクエストを同一のIPアドレスから送信すると、Webサイト側に不自然なアクセスと判断され、ブロックの対象となる可能性があります。
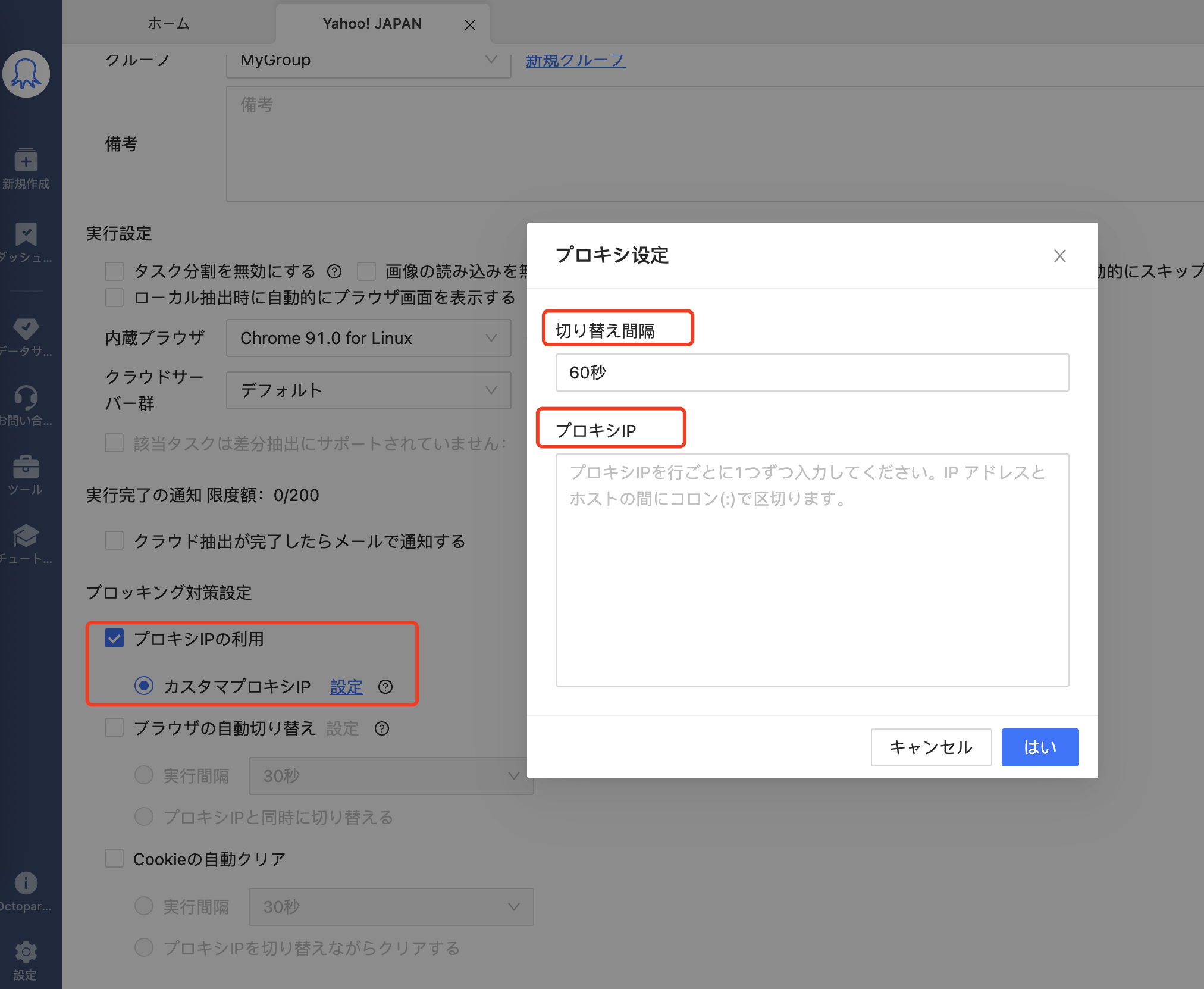
このような検知を回避する有効な手段の一つが、プロキシサーバーの活用です。プロキシサーバーとは、ユーザーの代わりに通信を中継するサーバーであり、実際のIPアドレスを隠し、代替のIPアドレスを使ってWebサイトにリクエストを送信します。これにより、単一のIPに対するリクエスト集中を回避することができます。
ただし、プロキシサーバーに設定されている単一のIPアドレスだけを使用しても、同じIPアドレスを繰り返し使用する限りブロックのリスクは残ります。そこで有効となるのがIPローテーションです。これは、複数のIPアドレスを用意し、それらをランダムまたは一定のルールで切り替えながらリクエストを送る方法です。
Octoparseでは、このIPローテーションの仕組みがクラウド実行環境に標準で組み込まれています。数百台のクラウドサーバーによって、各リクエストが異なるIPアドレスから送信され、Bot検出されるリスクを大幅に低減できます。また、ローカル実行時でも、手動でプロキシを設定することで、同様の回避策を講じることが可能です。
3.異なるスクレイピングパターンを適用する
私たちがWebサイトを閲覧する際は、クリックや閲覧時間が不規則になります。しかし、Webスクレイピングは、あらかじめプログラムされた特定のクローリングパターンに従うため、機械的・規則的な挙動となります。
Webサイト側は、このような規則的なパターンの連続を検出することで、自動化ツールによるアクセスを識別し、ブロックの判断材料とします。そのため、アクセスのパターンを都度変化させ、人間に近いランダム性を持たせることが検出回避の鍵となります。
具体的には、リクエストの間隔を変える、クリックの順序に変化を加える、さらにマウス操作を模倣するといった工夫が求められます。加えて、動作の各所に待機時間や遅延処理を挟むことで、人間らしい自然な挙動に近づけることが可能です。
Octoparseでは、このような多様なスクレイピングパターンの構築がGUI上で簡単に行えます。ドラッグ&ポイント操作により、クリックやマウスの動きを自在に設定でき、必要に応じてワークフロー全体の再構築も数ステップで実施可能です。
4. ユーザーエージェントを切り替える
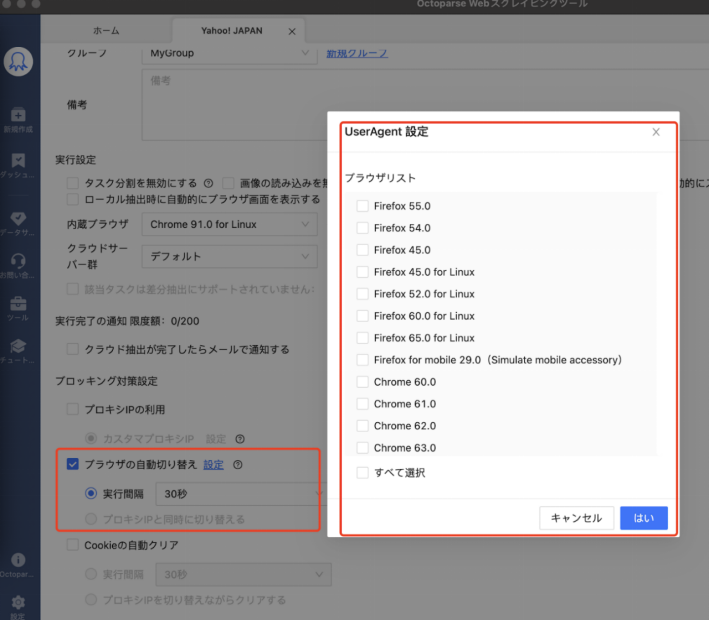
同一のユーザーエージェントを用いて大量のリクエストを継続的に送信すると、Webサイト側に自動化ツールと判断され、アクセスを制限される可能性が高まります。識別情報が固定されている場合、不自然な挙動として検出されやすくなります。
このようなブロックを回避するためには、ユーザーエージェントを定期的に切り替え、アクセス元の情報に変化を持たせることが有効です。たとえば、以下のような実在ブラウザのUser-Agentを組み合わせて使用することで、多様な環境からのアクセスを再現できます。
- Chrome 63.0
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
- Firefox 55.0
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0
- Edge 89.0
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.45
このような文字列を複数用意し、リクエストごとに切り替えることで、単一環境からのアクセスと見なされるリスクを低減できます。
一般的なスクレイピングでは、開発者がヘッダー情報を手動で編集し、ユーザーエージェントの切り替え処理をスクリプトに実装することが求められます。しかし、この手法には一定の技術的負担が伴います。
一方、Octoparseではユーザーエージェントの自動切り替え機能が標準で搭載されており、リクエストごとに異なるUAを適用することが可能です。これにより、ブロックのリスクを最小限に抑えつつ、安定したデータ取得を実現できます。
5.ハニーポットトラップに注意する
ハニーポットとは、本来はサイバー攻撃者の行動を監視・分析するために設置される「おとり」の仕組みを指します。スクレイピング対策としても応用されており、通常のユーザーには見えないリンクや要素をWebページ内に意図的に配置することで、Botの存在を検出する手法として利用されています。
このようなリンクは、私たち人間は目に見えないためクリックすることはありません。しかし、スクレイピング側はコードとして見つけてしまい隠されたリンクをクリックしてしまうのです。それにより、Webサイト側にBotによるアクセスであると判断され、リクエスト全体がブロックされる可能性があります。
このリスクを避けるためには、HTML構造を事前に確認し、不要なリンクや非表示要素に誤ってアクセスしないような制御が重要です。プログラミングする際には、ブラウザによる目視確認をして実装を行います。
一方Octoparseでは、要素の抽出やクリック操作にXPathを使用することができます。XPathを用いることで、表示状態や属性を条件に指定し、意図しないリンクやトラップ要素を除外することが可能です。これにより、誤ってハニーポットにアクセスするリスクを抑えつつ、正確なデータ抽出を実現できます。
詳しくは、XPathを使用して要素を見つける方法の記事をご覧ください。
スクレイピングがバレた時の対処法
スクレイピングが発覚した場合、単に法的リスクに備えるだけでなく、技術的な対応や運用方針の見直しも求められます。アクセス遮断や警告を受けた際にどのように対応すべきか、再発を防ぐには何を見直すべきかなど、実践的な対処法について解説します。
法的・規約違反した際の対応
スクレイピングが発覚した際、利用規約違反や著作権・個人情報保護法への抵触が確認された場合には、技術的な対応よりも先に、法的観点からの対応が求められます。
まず、対象サイトの利用規約に明示された禁止事項と、自身の行為の整合性を確認しましょう。また、取得したデータに著作権のある文章・画像、または個人情報が含まれていた場合は、速やかに該当データを削除し、第三者への提供や再利用を一切行わないようにします。これは、将来的な損害賠償請求や訴訟リスクを最小限に抑えるための基本的な対処です。
さらに、サイト側からの正式な通告や問い合わせがあった場合には、誠実な対応を徹底することが不可欠です。謝罪や対応内容の報告、再発防止の意思を明確に伝えることで、悪意のない行為であることを理解してもらえる可能性が高まります。
技術的なブロック・検出への対応
技術的な部分に対しても対応が必要です。最初に取るべき対応は、すべてのスクレイピング処理を即時停止することです。
バレてしまった後も継続的にスクレイピングを実施している場合、運営側の検知が強化され、恒久的なIPブロックや法的措置に発展するリスクが高まります。アクセス遮断が確認された時点で、必ず処理を中断し、設定を見直しましょう。
今後の運用と体制整備
スクレイピングが一度検出された場合、同様の事態を繰り返さないための体制整備が重要です。特に業務や組織で運用する場合は、再発防止の視点から運用方針を明確にしましょう。
まず、対象サイトの選定基準を定め、利用規約やAPIの有無を事前に確認するプロセスを整備します。禁止事項が明示されている場合には対象から除外し、取得範囲や目的も文書化しておくことが望ましいです。
個人で運用する場合でも、公式APIやオープンデータの利用を優先し、必要に応じて非公開データの取得を見送る判断も重要です。継続的な運用を目指すのであれば、リスクを最小限に抑えるための体制とルールの整備が不可欠です。
他のよくある質問
質問1:Seleniumでのスクレイピングはバレるの?
答え:Seleniumを使用したスクレイピングは、ブラウザを自動操作するため人間の挙動に近い点が特徴ですが、JavaScriptの動作やヘッダー情報などから自動操作であることを検出される可能性があります。
例えば、Seleniumが起動したChromeブラウザには通常とは異なるプロパティ(navigator.webdriver = true など)が含まれており、これを監視しているサイトではBotと判断されることがあります。
このような検出を回避するためには、「puppeteer-stealth」や「undetected-chromedriver」などを利用すると良いでしょう。
質問2:スクレイピングすると、サイトのサーバーに負荷をかけるの?
答え:はい。スクレイピングは、Webサイトのサーバーに一定の負荷を与える行為です。大量のリクエストを短時間で送信すると、サーバーが過負荷となり、応答速度の遅延やサーバーダウンに繋がる可能性があります。
このような事態を避けるためには、リクエストの間隔をあける、同時アクセス数を制限するなどの対策が重要です。
まとめ
本記事では、WebスクレイピングがWebサイト側に検出されないようにするための代表的な対策を5つご紹介しました。スクレイピング自体は違法行為ではありませんが、対象サイトの利用規約や法的制約に反する方法で実行すると、リスクを伴う可能性があります。
今回ご紹介した対策を講じることで、検出リスクを大幅に低減し、安定的かつ継続的なデータ取得が可能になります。
特に、Octoparseはプロキシ機能をはじめとする検出回避のための設定が充実しており、ユーザーごとの目的や負荷状況に応じた細かな調整が可能です。
プロキシの詳細な設定手順や活用方法については、以下の記事もあわせてご参照ください。
参考:Octoparseヘルプ|どのような場合に追加のプロキシサーバーを使用する必要がありますか?

ウェブサイトのデータを、Excel、CSV、Google Sheets、お好みのデータベースに直接変換。
自動検出機能搭載で、プログラミング不要の簡単データ抽出。
人気サイト向けテンプレート完備。クリック数回でデータ取得可能。
IPプロキシと高度なAPIで、ブロック対策も万全。
クラウドサービスで、いつでも好きな時にスクレイピングをスケジュール。



