「スクレイピングとはどういう仕組みで動いているの?」「Pythonを使ってスクレイピングを行うにはどうしたらいい?」このような疑問をお持ちではありませんか。スクレイピングを実装する方法はいくつかありますが、その中でも特に便利なのが「Scrapy(スクレイピー)」です。
本記事では、Scrapyとはどんなものなのか、基本から使い方まで解説します。Scrapyを扱えるようになることで、Pythonでスクレイピングも実装できるようになりますので、ぜひ参考にしてください。
Scrapyとは
Scrapyは、Pythonで開発されたウェブスクレイピング用のフレームワークです。フレームワークとは、アプリケーション開発において必要な機能をあらかじめ備えた枠組みのことを指します。したがって、Scrapyを使うことで、ある程度のプログラミングの知識がある方であれば、簡単にスクレイピングを実装できます。
例えば、どのサイトからどういったデータを取得するかなど、必要最小限のコーディングだけでスクレイピングを実装することが可能です。さらに、Scrapyはオープンソースのソフトウェアなので、誰でも無料で利用できます。高速で動作し、複雑なデータ抽出のニーズにも柔軟に対応できるので、多くの開発者に利用されています。
Scrapyの内部構造と機能詳細
Scrapyのアーキテクチャは、複数のコンポーネントとその間のデータフローで構成されています。ここでは、それぞれのコンポーネントと8つの主要なフローを詳しく見ていきましょう。
コンポーネント
コンポーネントとは、ソフトウェアやシステムを構成する個々の部品や要素のことを指します。Scrapyにおけるコンポーネントは、特定の機能や役割を持ち、システム全体の動作や機能を支えるために相互に連携して動作します。
- Scrapy Engine(エンジン): システムの中心で、各コンポーネント間の通信を担当します。
- Scheduler(スケジューラ): リクエストを受け取り、順序を決めてキューに入れ、エンジンが要求するときに提供します。
- Downloader(ダウンローダー): エンジンからのリクエストに基づき、ウェブページをダウンロードし、レスポンスをエンジンに返します。
- Spider(スパイダー): ダウンロードされたページからデータを抽出し、アイテムを生成または新しいリクエストをエンジンに送り返します。
- Item Pipeline(アイテムパイプライン): スパイダーから受け取ったアイテムを処理し、例えばデータベースに保存します。
- Downloader Middlewares(ダウンローダーミドルウェア): リクエストとレスポンスの処理をカスタマイズします。
- Spider Middlewares(スパイダーミドルウェア): スパイダーの入出力をカスタマイズします。
データフロー
Scrapyの全体の流れは以下の画像のとおりです。「⑥Engine」は、全体を制御するシステムのコアです。Scrapyにおいては、Engineを中心にデータ制御が行われます。
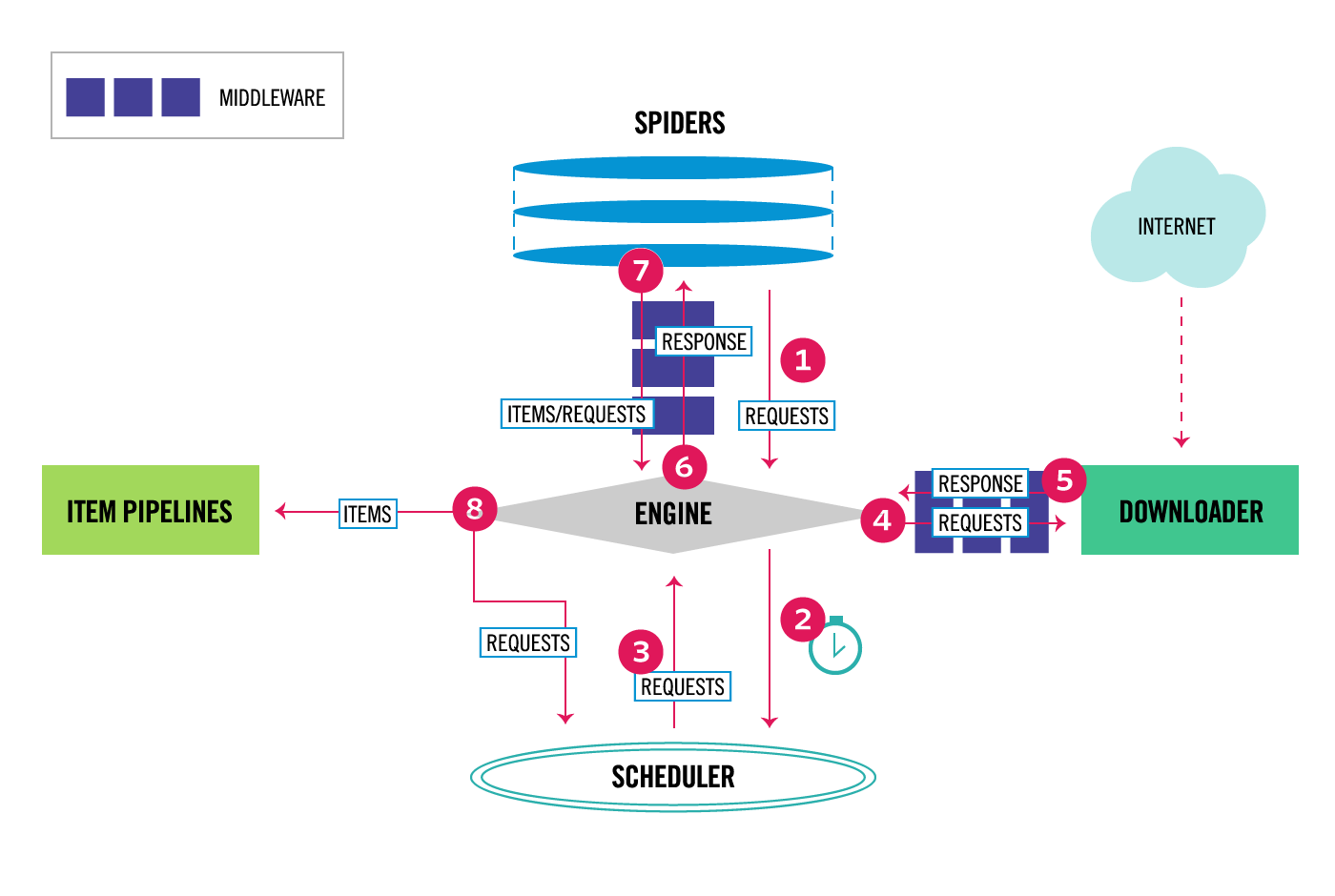
最初のリクエスト:スパイダーからエンジンへ、クロールを開始するための最初のリクエストが送られます。
スケジューリング: エンジンはこのリクエストをスケジューラに送り、スケジューラはリクエストをキューに入れます。
ダウンロードの要求: エンジンはスケジューラから次のリクエストを受け取り、ダウンローダーに送信します。
ウェブページのダウンロード: ダウンローダーはリクエストされたページをダウンロードし、レスポンスをエンジンに返します。
スパイダーへの送信: エンジンはレスポンスをスパイダーに送り、スパイダーはページを解析してデータを抽出します。
アイテムの処理: スパイダーから抽出されたアイテムはエンジンを通じてアイテムパイプラインに送られ、処理されます。
追加リクエストの処理: スパイダーが新しいリクエストを生成した場合、それらは再びエンジンに送られ、スケジューラによってキューに入れられます。
繰り返し: このプロセスは、スケジューラのキューにリクエストがなくなるまで繰り返されます。
Scrapyの特徴とは
Scrapyは、Pythonが開発したオープンソースのウェブスクレイピングフレームワークであり、その設計と機能には特徴があります。これらの特徴を理解することで、Scrapyがいかにウェブスクレイピングやデータ抽出のためのツールとして優れているかが理解いただけるでしょう。
非同期処理
ScrapyはTwistedという非同期ネットワーキングライブラリを使用しています。これにより、Scrapyはウェブページのダウンロードやデータの抽出など、複数のタスクを同時に非同期に処理できます。この非同期処理により、ウェブスクレイピングの速度と効率が大幅に向上します。
拡張可能なアーキテクチャ
Scrapyのアーキテクチャは非常に柔軟で、ユーザーが独自の機能を追加しやすいように設計されています。ミドルウェア、拡張機能、パイプラインなど、必要に応じてカスタマイズや拡張が可能です。これにより、特定のプロジェクト要件に合わせてScrapyを調整することができます。
ログとデバッグ
Scrapyは実行中のプロセスに関する詳細なログ情報を提供し、問題の診断と解決を容易にします。また、Scrapyシェルやスパイダーのデバッグ機能を利用することで、開発者はスクレイピングのロジックをステップバイステップでテストし、問題を効率的に特定できます。
ロボット対策回避
Scrapyはrobots.txtのルールを尊重し、ウェブサイトのクロール禁止ルールに従います。これにより、ウェブサイトの利用規約に違反することなく、倫理的なスクレイピングを行うことができます。また、ユーザーエージェントのカスタマイズやダウンロード遅延の設定を通じて、サーバーへの負荷を軽減し、アクセスを制御することも可能です。
Scrapyを活用する際の注意点
Scrapyを使用してウェブスクレイピングを行う際は、効率的にデータを収集するために、いくつかのポイントを押さえる必要があります。ここでは、Scrapyを使ってスクレイピングを成功させるための注意点をいくつか紹介します。
適切なクローラの設計
ウェブサイトごとに異なる構造を持っているため、スパイダーの設計はプロジェクトの成功に直結します。まず、対象となるウェブサイトのHTML構造を分析し、必要なデータがどのように配置されているかを理解することが重要です。
この情報をもとに、効率的にデータを抽出できるスパイダーを設計します。また、サイトがJavaScriptで動的にコンテンツを生成している場合は、ScrapyとSeleniumなどのブラウザ自動化ツールを組み合わせることも検討しましょう。
頻繁なデータバックアップ
スクレイピング中には予期せぬエラーが発生することがあります。例えば、ウェブサイトの構造が変更されたり、一時的にアクセスできなくなることがあります。
これらの問題によりデータが失われるリスクを避けるために、定期的にデータのバックアップを取ることが重要です。バックアップは、データの安全性を確保し、何か問題が発生した場合に迅速に対応できるようにするための基本的なステップです。
フェアプレイとエシカルスクレイピング
フェアプレイとエシカルスクレイピングは、ウェブサイトの利用規約を尊重し、サーバーに過度な負荷をかけないように配慮しながらデータを収集することを意味します。具体的には、robots.txtのルールを遵守し、アクセス頻度や速度を調整してサーバーへの負荷を最小限に抑えることが含まれます。
また、収集したデータを責任を持って扱い、プライバシーを尊重することも大切です。エシカルなスクレイピングを行うことで、ウェブコミュニティの健全な発展に貢献し、法的な問題を避けることができます。
セキュリティの確保
スクレイピングプロジェクトでは、収集したデータのセキュリティを確保することが非常に重要です。データの暗号化、安全な認証方法の使用、セキュリティパッチの適用など、適切なセキュリティ対策を講じることで、悪意のある攻撃からデータを守ります。
また、スクレイピングによって収集したデータが個人情報を含む場合は、データ保護法規に準拠して適切に管理することが求められます。
Scrapyのインストール手順
Scrapyは、Pythonで書かれた強力なウェブスクレイピングフレームワークです。Windows、Ubuntu、macOSなど、さまざまなオペレーティングシステムでインストールが可能です。ここでは、各OSにおけるScrapyのインストール手順を解説します。
Windowsのインストール手順
1. pipバージョンのアップグレード:
最初に、Pythonのパッケージ管理システムであるpipを最新バージョンにアップグレードします。
| pip install –upgrade pip |
2. Scrapyのインストール:
pipを使用してScrapyをインストールします。
| pip install Scrapy |
Ubuntuのインストール手順
1. Python以外の依存関係のインストール
Scrapyをインストールする前に、必要な依存関係をインストールします。
| sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev |
2. Scrapyのインストール
依存関係のインストール後、pipを使用してScrapyをインストールします。
| sudo pip install scrapy |
macOSのインストール手順
macOSでScrapyをインストールする場合も、pipを使用しますが、まずはHomebrewを使っていくつかの依存関係をインストールする必要があります。
1. Homebrewのインストール
macOSでは、パッケージマネージャとしてHomebrewを使用します。まだインストールしていない場合は、Homebrewの公式サイトからインストール手順に従ってください。
2. 依存関係のインストール
Homebrewを使用して、Scrapyのインストールに必要な依存関係をインストールします。
| brew install python libxml2 libxslt libffi openssl |
3. pipバージョンのアップグレード
pipを最新バージョンにアップグレードします。
| pip install –upgrade pip |
4. Scrapyのインストール
依存関係のインストール後、pipを使用してScrapyをインストールします。
| pip install Scrapy |
Scrapyスパイダーの実践例
ここからは、Scrapyを使用してウェブスクレイピングを行う際の基本的な手順を解説します。今回は例として、「Octoparseブログ」から記事のタイトル、著者、投稿日を抽出するスパイダーの作成方法をステップバイステップで見ていきましょう。
1. 新しいプロジェクトの作成
ターミナルまたはコマンドプロンプトを開き、以下のコマンドを実行してScrapyプロジェクトを作成します。
| scrapy startproject mySpider |
このコマンドはmySpiderという名前のプロジェクトを作成し、プロジェクトに必要なファイルとディレクトリ構造を生成します。
2. 目標の定義
プロジェクトの’items.py’ファイルを編集して、抽出したいデータの構造を定義します。続いて、Octoparseブログの記事タイトル、著者、投稿日を抽出するためのItemを以下のように定義します。
| import scrapy class OctoparseBlogPost(scrapy.Item): title = scrapy.Field() author = scrapy.Field() date = scrapy.Field() |
3. Spiderの作成
‘spiders’ディレクトリ内に’octoparse_blog_spider.py’という名前で新しいスパイダーファイルを作成し、以下のコードを記述します
| import scrapy class OctoparseBlogSpider(scrapy.Spider): name = “octoparse_blog” start_urls = [‘https://www.octoparse.jp/blog’] def parse(self, response): for post in response.css(‘div.blog-list-item’): yield { ‘title’: post.css(‘div.blog-list-item-title a::text’).get(), ‘link’: post.css(‘div.blog-list-item-title a::attr(href)’).get(), } |
このスパイダーは、’start_urls’で指定されたOctoparseブログのページから、各記事のタイトル、著者、投稿日を抽出します。
4. データの抽出
‘parse’メソッドでは、指定したURLのページから必要な情報を抽出するロジックを記述します。上記のコード例では、CSSセレクタを使用して記事のタイトル、著者、投稿日を抽出しています。
5. コンテンツの保存
データの後処理と保存のために、’pipelines.py’ファイルでパイプラインを設計します。これには、データのクリーニング、重複の削除、データベースへの保存などが含まれます。具体的なパイプラインの設計はプロジェクトの要件に応じて異なります。
6. スパイダーの実行
スパイダーを実行するには、プロジェクトディレクトリ内で以下のコマンドを使用します。このコマンドは、name属性に指定した’octoparse_blog’という名前のスパイダーを実行し、指定したデータを抽出します。
| scrapy crawl octoparse_blog |
これらの手順に従うことで、Scrapyを使用してOctoparseブログから記事のタイトル、著者、投稿日を抽出するスパイダーを作成し、実行することができます。
まとめ
今回は、Scrapyの基本的な使用方法、プロジェクトの立ち上げからデータの抽出、保存までのプロセスを初学者向けに解説しました。Scrapyは、Pythonが開発したウェブスクレイピングフレームワークで、使い方を覚えることで、さまざまなデータ抽出を行うことが可能です。
もし、さらにかんたんにスクレイピングを行いたい場合は、スクレイピングツールのOctoparse(オクトパス)がおすすめです。Octoparseを使えば、プログラミング不要で簡単なマウス操作だけでデータ抽出が可能です。無料で使えるので、ぜひOctoparseも使ってみてください。




