膨大な数の求人情報が掲載されているタウンワーク。目的の求人情報を効率的にリスト化できる方法をご存知でしょうか?
その方法を「Webスクレイピング」と呼びます。Webスクレイピングを実行するやり方は2通りあります。
1つ目は、「Python(パイソン)」というプログラミング言語を用いてプログラムを作るやり方。そして2つ目は、「Octoparse(オクトパス)」というWebスクレイピングを作るやり方。
今回は、PythonとOctoparseはどちらが初心者向けのやり方なのか?を知っていただくために、両者のWebスクレイピングを比較します。
Webスクレイピングに興味がある方はぜひ参考にしてみてください。
PythonでタウンワークをWebスクレイピングするやり方
PythonはWebスクレイピングを実行するためのライブラリ(既存のプログラム)が豊富なプログラミング言語であり、ほとんどの場合、WebスクレイピングはPythonを使って実行されています。
それでは、Pythonを使ってタウンワークをWebスクレイピングするやり方をご紹介します。
ちなみに今回はMacを使用しますが、Windowsでもほとんど同じ手順でPythonが使えるので、Windowsユーザーは「Pythonを使ったWebスクレイピングはこういう作業が必要なんだな」と参考にしていただければと思います。
1. Pythonの環境を整える
Macのターミナルを開いたら以下のコマンドを実行して、パッケージのインストールや管理が可能な「Homebrew(ホームブリュー)」をインストールします。
| $ /bin/bash -c “$(curl -fsSLhttps://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)” |
パスワードの入力を求められた場合は、入力後にEnterキーを押下してください。
次に、Homebrewの機能を使ってPythonの実行環境をインストールするために、以下のコマンドを実行してください。
| $ brew install python |
これでPythonの最新バージョンがインストールされます。以下のコマンドを実行して、Pythonがインストールされているか確認してみましょう。
| $ python ―version |
バージョン情報が表示されれば、Pythonは正常にインストールされています。また、pipと呼ばれるライブラリ管理ツールもインストールされているか、以下のコマンドを実行して確認してみてください。
| $ pip ―version |
バージョン情報が表示されればpipも正常にインストールされています。
2. 必要なライブラリをインストールする
Webスクレイピングを実行するにあたって必要なライブラリが3つあります。
| ライブラリ | 役割 |
| Requests | Webスクレイピングに必要なHTMLやXMLといった情報をWebページから取得する |
| Beautiful Soup4(bs4) | Requestsで取得したHTMLやXMLから必要な情報を抽出する |
| Pandas | Beautiful Soup4で抽出した情報を見やすい形に加工する |
pipコマンドを使って各ライブラリをインストールします。
Requestsをインストールするコマンド
| $ pip install requests Beautiful Soup4(bs4) $ pip install beautifulsoup4 Pandas $ pip install pandas |
ここまでの作業でWebスクレイピングを実行するための環境が整いました。
3. Webスクレイピングを実行するプログラムを作成する
さて、ここからが問題です。Webスクレイピングの実行環境を整える作業は、多少の躓きはあっても初心者でも完了できます。
しかし、Webスクレイピングを実行するためには以下のようなプログラムを作成しなければいけません。
| import requests from bs4 import BeautifulSoup import pandas def get_items(url, df, columns): res = requests.get(url) res_text = res.text soup = BeautifulSoup(res_text, “html.parser”) ret = soup.find_all(“div”, class_=”job-lst-main-cassette-wrap”) ret.pop(0) # 最初と最後の要素は広告なので削除 ret.pop(-1) for item in ret: rid = item.find(“a”, class_=”job-lst-main-box-inner”).get(“href”) company = item.find(“h3″, class_=”job-lst-main-ttl-txt”).text.strip() title = item.find(“p”, class_=”job-lst-main-txt-lnk”).text.strip() trs = item.select(“tr.job-main-tbl-inner > td > p”) salary = trs[0].text access = trs[1].text term = trs[2].text try: timelimit = item.select_one(“p.job-lst-main-period-limit > span”).text except AttributeError: timelimit = “不明” print(“{0}番目の情報({1}):{2}をDataFrameに追加します…”.format(len(df)+1, rid, title)) print(“会社名:{0} タイトル:{1} 給与:{2} 交通:{3} 勤務時間:{4} 掲載終了日時:{5}” \ .format(company, title, salary, access, term, timelimit)) se = pandas.Series([rid, company, title, salary, access, term, timelimit], columns) df = df.append(se, ignore_index=True) return df def main(): url = “https://townwork.net/joSrchRsltList/?fw=プログラミング” columns = [“rid”, “company”, “title”, “salary”, “access”, “term”, “timelimit”] df = pandas.DataFrame(columns=columns) results = get_items(url, df, columns) print(results) if __name__ == ‘__main__’: main() |
このプログラムを作成するにはプログラミングを行うための「コードエディタ」をインストールする必要があり、さらにコードごとの役割を理解しなければいけません。
上記のプログラムをコピペして利用することも可能ですが、それではタウンワークでしかWebスクレイピングを実行できないため、実用性に乏しくなってしまいますね。
Webスクレイピングを実行するにはPythonでプログラムを作る必要があり、それがなかなか大変な作業だということをご理解いただけたのではないでしょうか。
注:コードのソースはみゃふのPythonプログラミング解説の公開記事を参考にさせていただきました。
OctoparseでタウンワークをWebスクレイピングするやり方
続いて、WebスクレイピングツールのOctoparseを使ってタウンワークをWebスクレイピングするやり方をご紹介します。
Octoparseは無料で使い始められるWebスクレイピングツールであり、初心者でも簡単にWebスクレイピングが実行できるのでぜひ挑戦してみてください。
1. Octoparseに登録する
まずは、Octoparseの無料アカウントを取得してみましょう。Octoparseの新規登録ページに移動し、メールアドレス、パスワードを入力し、「続き」をクリックしてください。
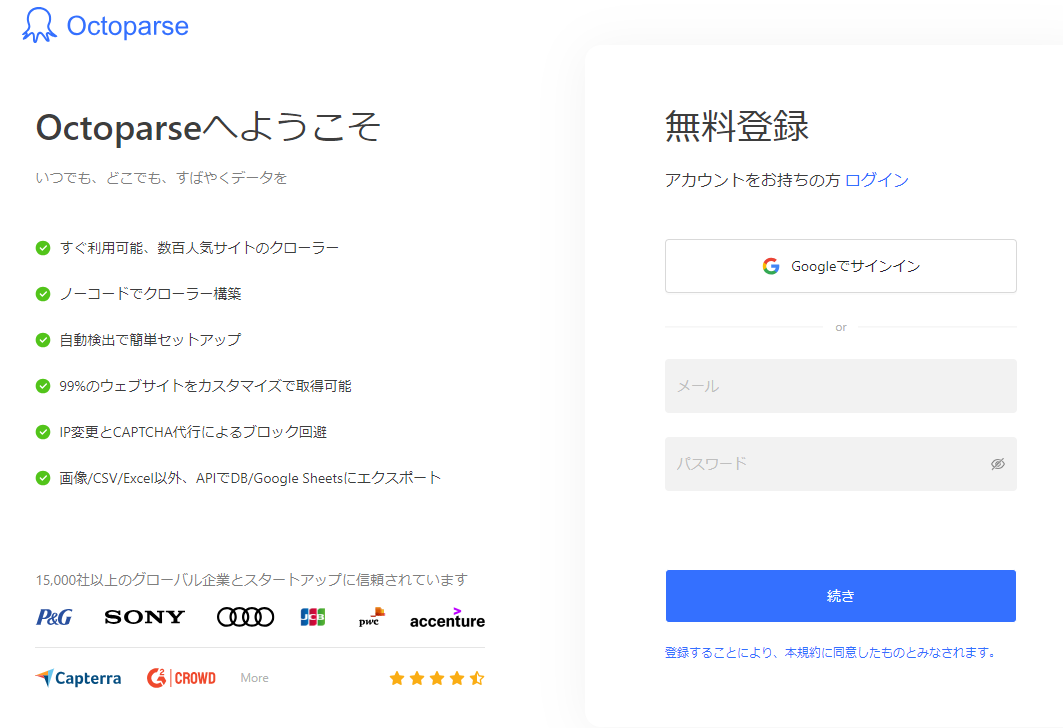
設定したメールアドレスにOctoparseからメールが届くので開封し、「メールアドレスを認証する」をクリックしてください。
以上でOctoparseへの登録は完了です。
2. Octoparseをインストール&起動する
次にお使いのPCにOctoparseをインストールしていただき、起動しましょう。
お手持ちのPCがMACの場合、【MAC用ダウンロード】をクリックしてください。Octoparseをダウンロードできたらファイルを実行し、Octoparseを起動しましょう。するとログイン画面が表示されるので、先ほど登録したメールアドレスとパスワードを入力し、「ログイン」をクリックしてください。
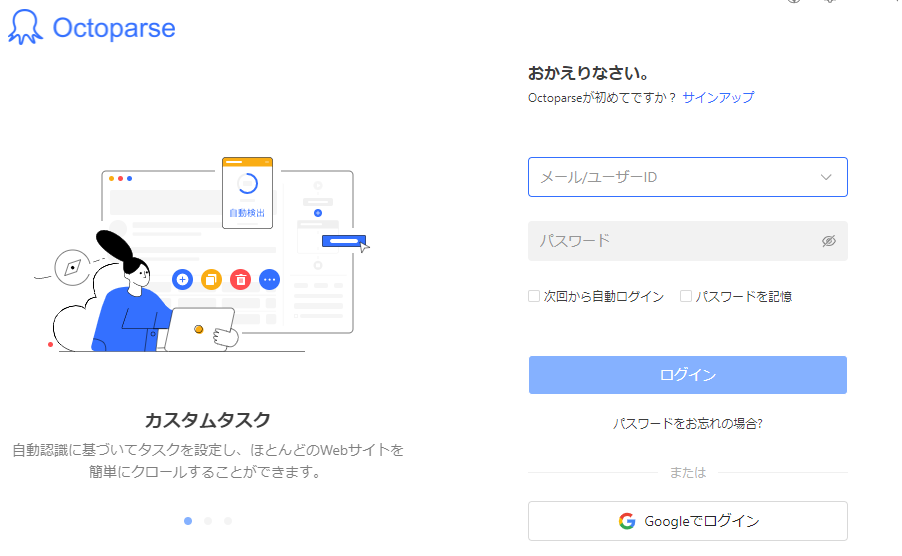
以上で、Octoparseを使ったWebスクレイピングの準備が整いました。
3. タウンワークのテンプレートタスクを使う
ここからがOctoparseのすごいところです。Octoparseでは、タウンワークから求人情報を収集するためのテンプレートタスクを用意しています。
https://www.octoparse.jp/template/townwork-job-scraper
Octoparseを起動したら検索欄に「タウンワーク」と入力し、表示されたテンプレートタスクをクリックしてください。
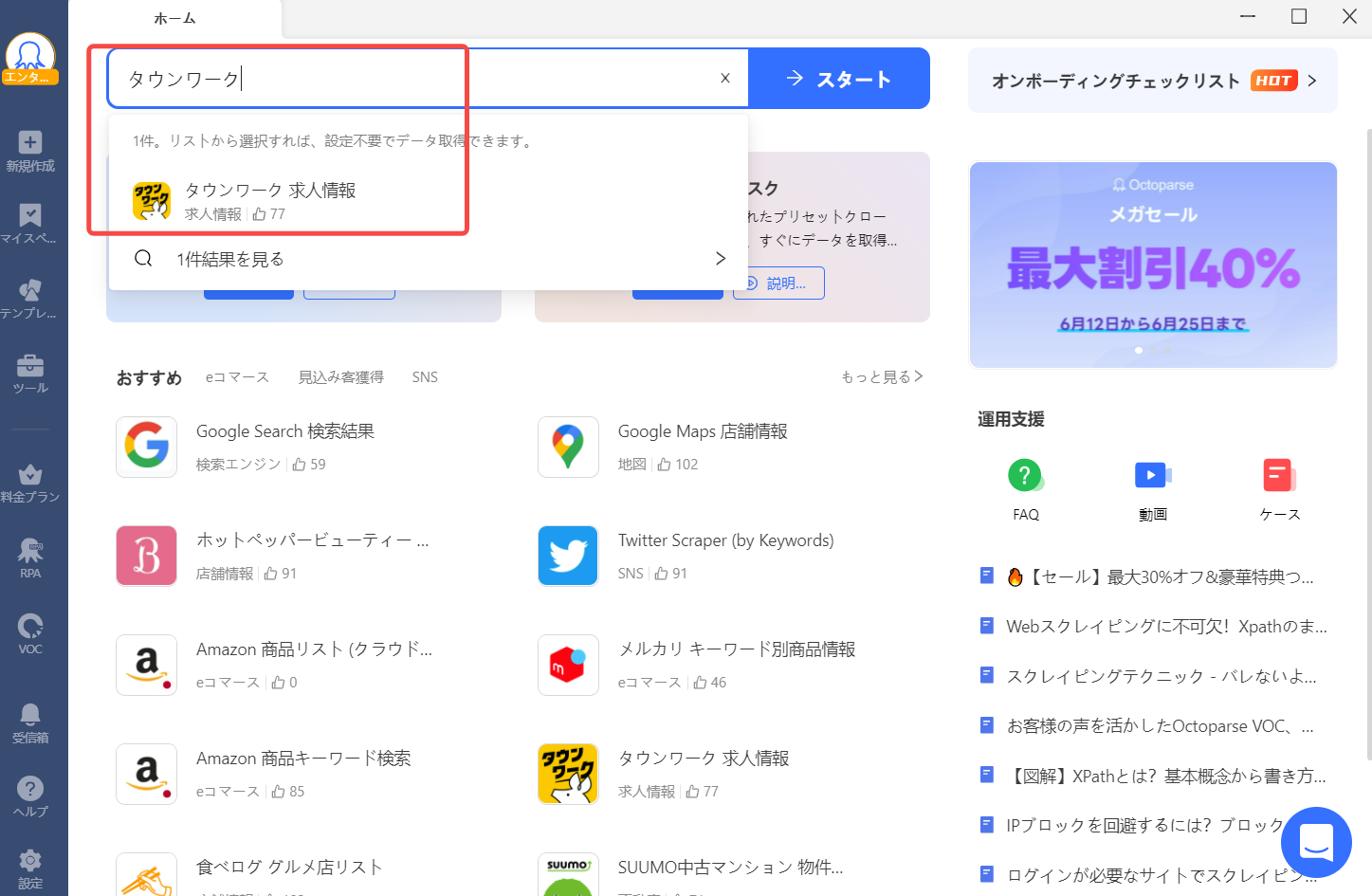
続けて「今すぐ使う」をクリックしてください。
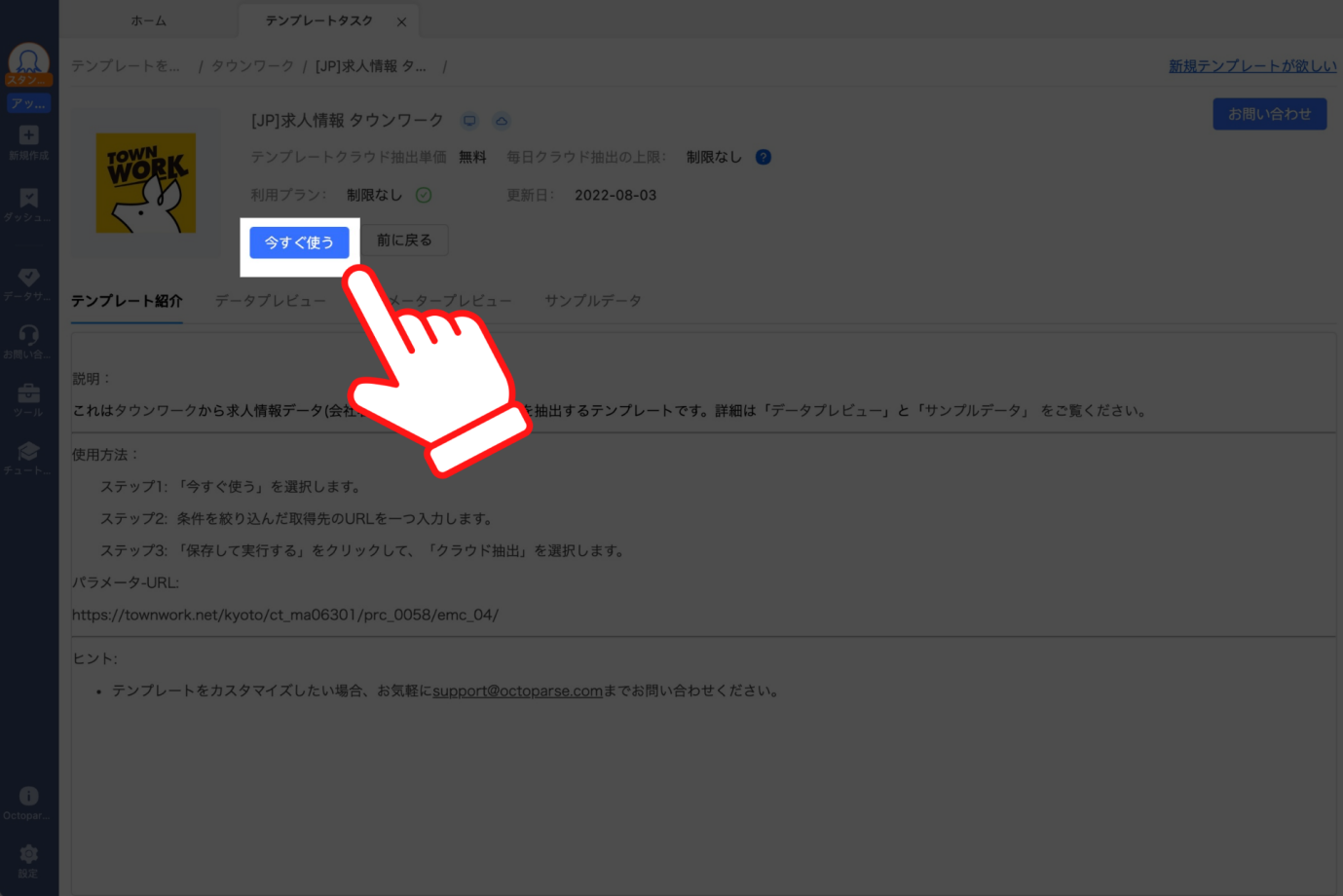
パラメーターを設定するページが表示されるので、URL入力欄にタウンワークからコピーした検索結果ページのURLを入力し、「保存して実行」をクリックしてください。
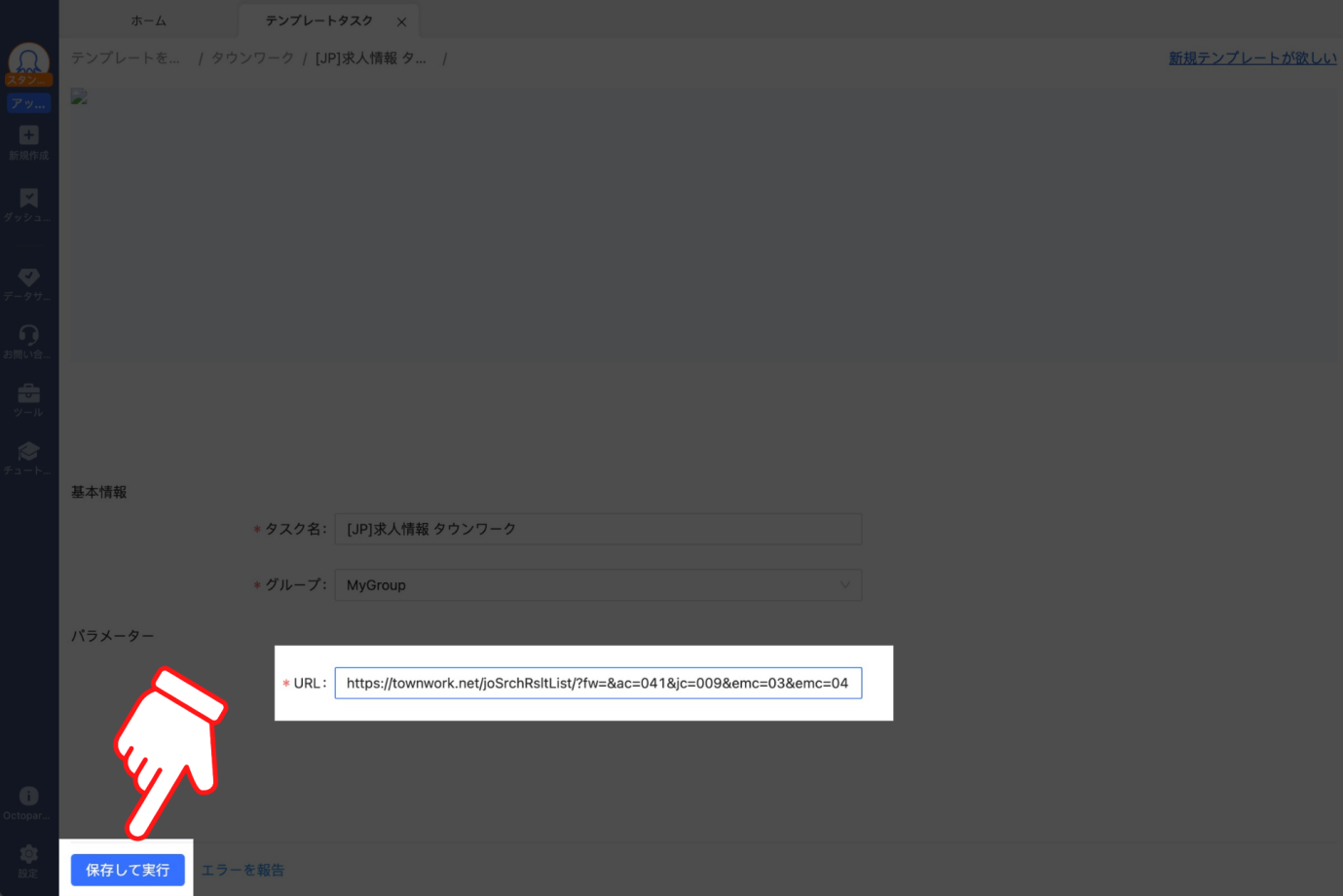
最後にタスクの実行方法を選択する画面が表示されるので、ローカル抽出の「通常モード」をクリックしてください。
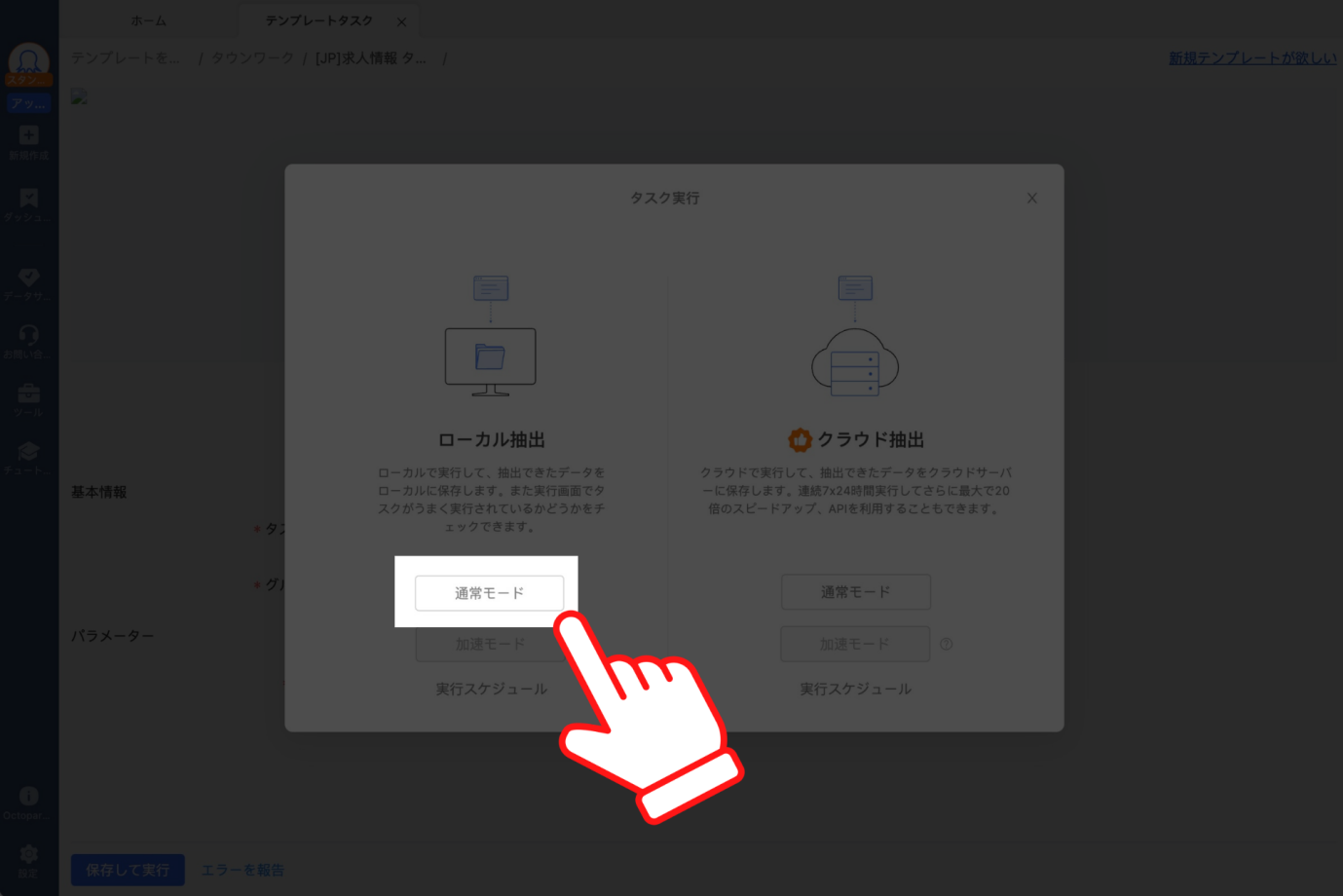
以上でWebスクレイピングの実行は完了です!
たったこれだけの作業でタウンワークから求人情報を取得し、自動的にリスト化することができます。あとはOctoparseのWebスクレイピングが終了するのを待つだけです。
4. 実行結果をダウンロードする
OctoparseのWebスクレイピングが終了すると、実行結果をダウンロードできる画面が表示され流ので「データをエクスポート」をクリックしてください。
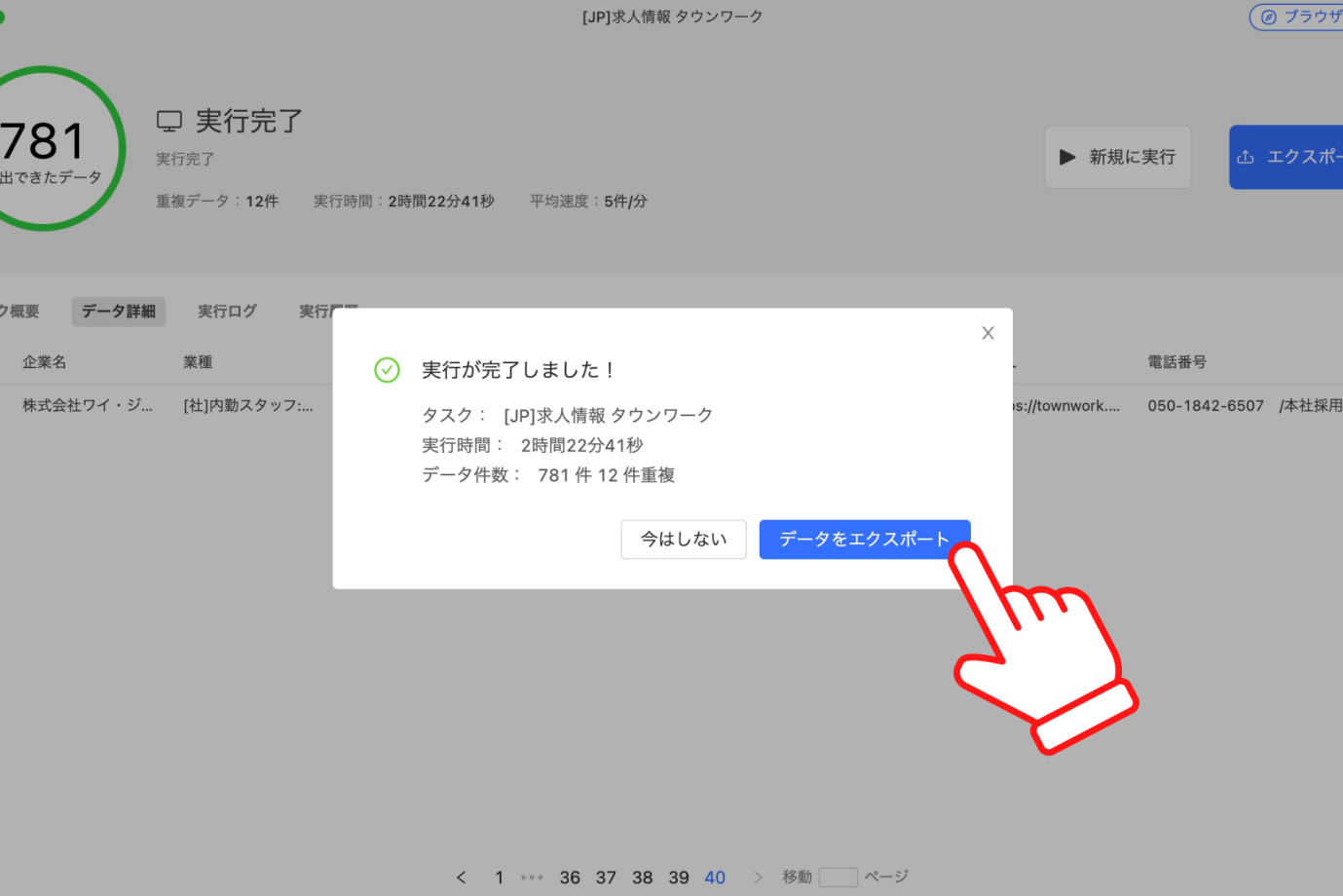
「唯一データ」をクリックしてください。
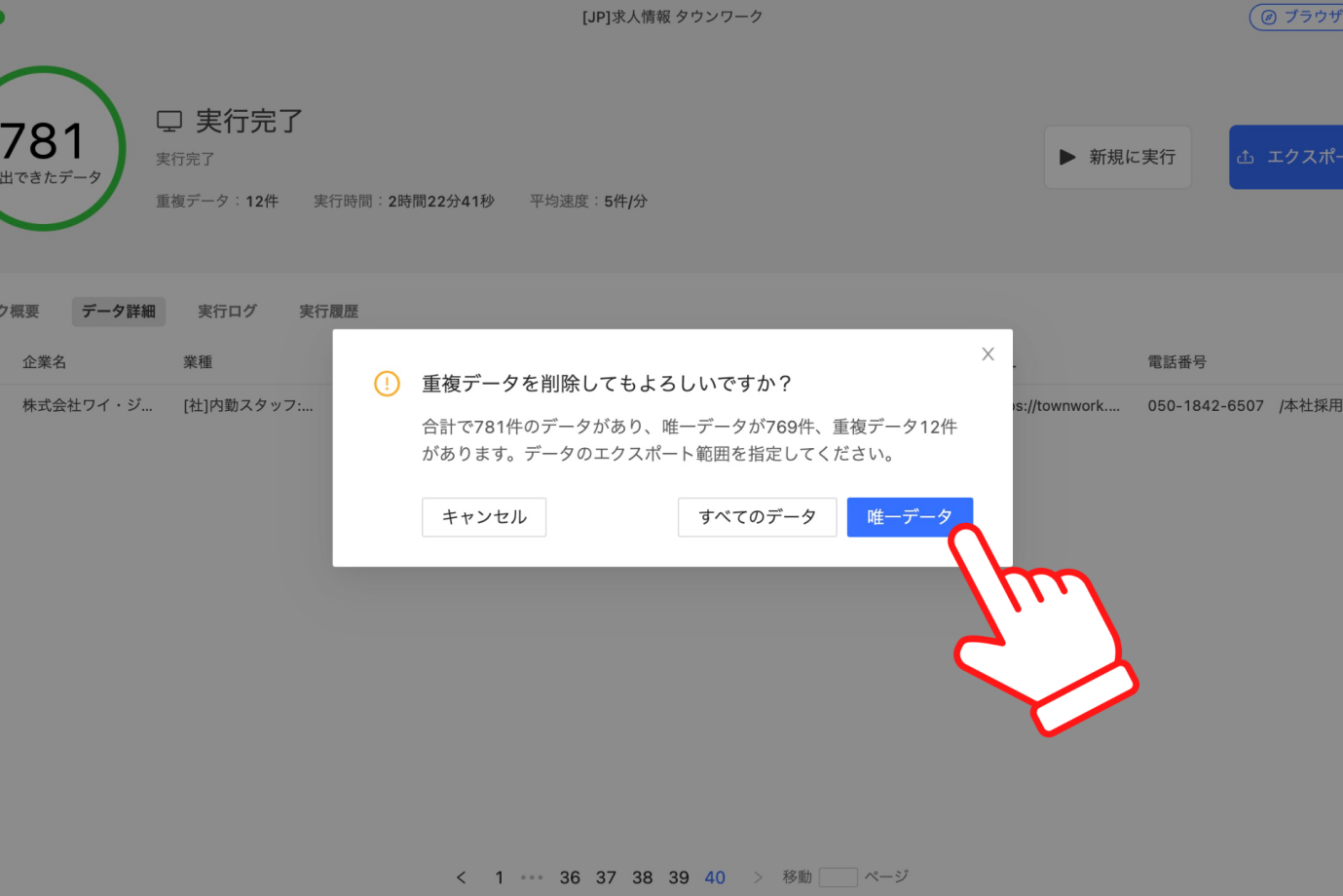
任意のダウンロード形式を選択し、「はい」をクリックして実行結果をダウンロードしましょう。
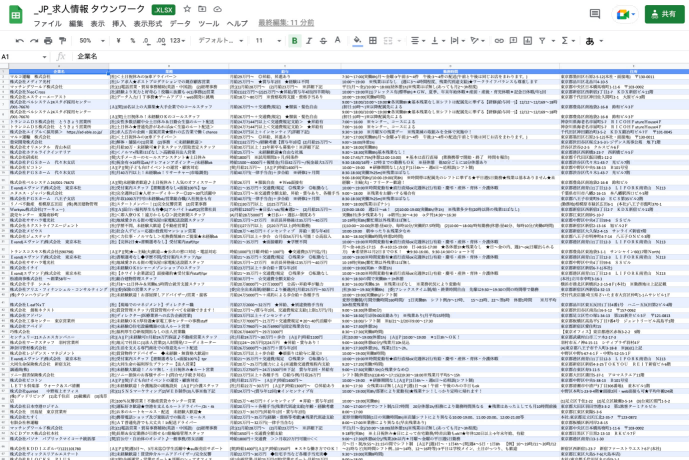
ちなみにこちらがExcel形式でダウンロードした実行結果です。
Webスクレイピング初心者ならOctoparseが断然おすすめ
いかがでしょうか?Pythonを使ったWebスクレイピングと比較してみると、Octoparseは圧倒的に短時間でWebスクレイピングを実行できますね。
今回はタウンワークの求人情報をリスト化する方法をご紹介しましたら、Octoparseは他にもさまざまなテンプレートタスクをご用意しています。
また、URLを入力するだけでOctoparseがWebページを自動識別し、必要な情報をリスト化できるカスタマイズタスクの利用もおすすめです。
Octoparseが1つあれば情報収集の可能性が大きく広がるので、まだご利用されたことがない方は、この機会にOctoparseをぜひ使ってみてください。




