情報が爆発的に増加している今日、ニュースレコメンドエンジンは、多くのニュースサイトやアプリにとって重要な技術となっています。ニュース推薦技術の適用は、情報過多の問題を改善するだけでなく、使用体験を向上させ、ユーザーの粘着性と定着性も向上させます。
しかし、ニュースメディアのプラットフォームには、ニュースデータを効率的に獲得し整理するだけではなく、ニュースコンテンツを体系的に分類したり、高度なコンテンツ推薦アルゴリズムの整備と膨大なユーザーデータを活用することによって、ユーザーが興味を持っているコンテンツをユーザーのホームページに推薦します。
レコメンデーション領域で代表となる企業はByteDanceです。この会社は近年Tiktokの流行に伴って、世界で多くの人に知られています。実は、Tiktokの他に、この会社が開発した「BuzzVideo」「VigoVideo」なども近年急激な成長を遂げています。これらの製品は一つの強力なアルゴリズム、すなわちレコメンデーションという技術を利用しています。ただ、利用場面によって、コンテンツやモデル・アーキテクチャは異なっています。
では、レコメントエンジンというシステムは何でしょうか?
レコメントエンジンとは
ウィキペディアによると、レコメンダシステムは情報フィルタリング技法の一種で、特定ユーザーが興味を持つと思われる情報をていじするものです。
簡単に言うと、ユーザーの好みに応じてコンテンツを推薦するシステムです。
Tiktokを例としてあげましょう!Tiktokを開いて「おすすめ」フィードにアクセスすると、各ユーザーのおすすめフィードはそれぞれ異なっています。レコメントエンジンというシステムで、最初にTikTokは動画を推薦し、ユーザーがその推薦された動画に対する反応とか、「いいね!」「コメント」、そして戻って再生するリプレイなどに基づいて、徐々にシステムがユーザーのコンテンツの好みをより深く理解して行きます。このことによって、ユーザーに興味に合わせて、精度が高い動画を推薦することができます。
レコメンデーションを行う前に非常に重要なステップとしてはコンテンツ(情報・データ)分類です。
従来のコンテンツ分類は主にニュース業界で展開してきました。最初のニュース分類はほとんど手作業で行われていました。しかし、インターネットとIT技術の発展に伴い、手作業のニュース分類は今日の膨大な情報の背景で限界がありました:
- 膨大なデータ量:誰でも情報を発信できる今日では、ニュースソースは数多くて、1分間にも何千万の新しい情報が発信される可能性があります。
- 高い人件費:データ量の急増により、より多くの人件費が必要となります。
- 低い効率:ニュースデータには高い適時性が求められるため、手作業で処理すれば効率が低いです。
一方、コンピュータ処理はこれらの問題をうまく解決でき、膨大なデータ量であっても、効率的な処理・運用が可能です。人件費も大幅に節約することもできます。これから、コンピュータ技術を使って自動化でニュースデータの分類する方法について説明していきます。
✅ニュースデータの分類は、今までどのような段階を経ったのでしょうか。
✅どのように、コンピュータで大量のテキストを分類するのでしょうか。
✅自動化のニュース分類はどのように実現されるのでしょうか。
ニュース分類の進化
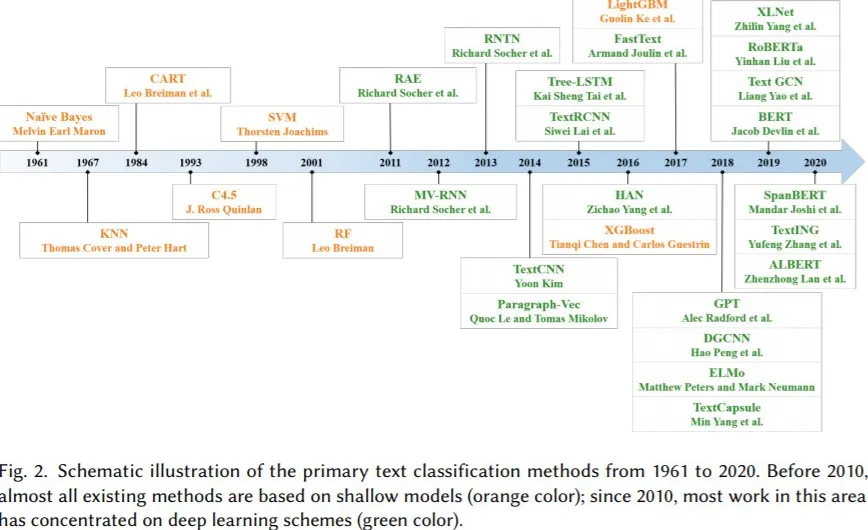
上記の画像は、専門の学者によるテキスト分類技術の開発をまとめたもので、少し難しいと見えますが、簡単に言うと4つの段階に分けられます。
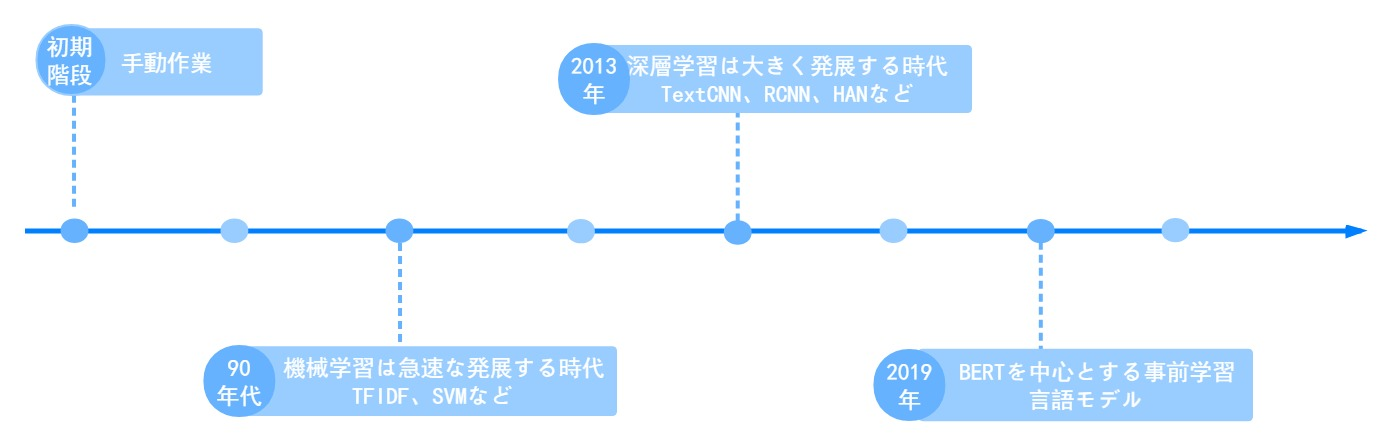
初期階段:ニュースのデータが少なく、コンピュータも普及していなかった時に、ニュース分類は手動で分類しています。
1990年代以降、インターネットの発達に伴い、データ量が急速に蓄積される一方で、ニュースの獲得が易くなることとコンピュータの性能が急速に向上したことにより、機械学習は急速な発展の時代を迎えました。 この時の自然言語処理は言語学の分野から徐々に学際的な科目になっていた。その中で統計数学はますます重要になり、初期のTF-IDFなどアルゴリズムの価値を徐々に認識されました。
最近の10年、GPUコンピューティングがもたらした並列計算能力の向上により、深層学習は大きく発展し、1990年代に提案されたLSTMのような多くのネットワーク構造が広く採用され、多くの分野で成果をあげました。 この時、CNNやRNNをベースにしたニューラルネットワークモデルが多数提案され、LSTM、TextCNN、RCNN、HANなど、さまざまなシーンでの深層学習の応用が急速に発展しています。
この2年間で、BERTを中心としたTransformerをベースとする事前学習言語モデルが、徐々に自然言語処理の主流を占め始めました。その動きの目的は、最大限に言語の基本法則を学習し、少量のラベル付きデータを使用して、最優な結果を得ることによって、各場面に活用していくことです。
まとめ:深層学習は、自然言語処理の分野に飛躍的な進歩をもたらしましたが、コストは高いです。それで、最適な技術を探すのが必要です。
ニュース分類をどのように実現するか?
ニュースデータを取得した後、ニュースを分類を実現するプロセスは以下のようになります。
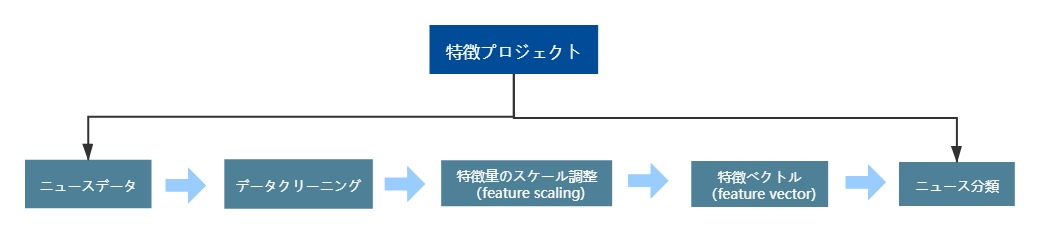
①データクリーニング:ニュースに関係のない記号や特殊なフィールドを選別し、重複するコンテンツを削除し、文章の質を向上させ、システムの負荷を軽減する。
②特徴量のスケーリング:ニーズに応じて、必要となっているキーワード、ニュースタイトル、ニュースの最初の段落と最後の段落などのテキストを抽出します。
③特徴量のベクトル化:各ニュース記事の特徴量を、分類アルゴリズムが演算を行うための固定長のベクトルに集約する。
④ニュースの分類:スポーツ、金融、技術、エンターテインメントなどのカテゴリーでニュースを分類します。
ニュース分類の利用場面
ニュース分類の利用場面は、スポーツ、金融、技術、エンターテインメントなど、従来のニュース領域の分類によく用いられます。例えば、このようになります。
ニュース分類は、機械学習で実現されたので、モデルの学習にラベル付きデータを使用する必要があります。 しかし、分類したいカテゴリーが前述の従来のニュース領域区分であれば、手動でアノテーションを追加することなく、主流メディアの関連セクションから直接ニュースを収集して学習データとすることができます。
特徴量エンジニアリング
分類する前には、最終的な結果に直接に影響を与える作業があります。これが特徴量エンジニアリングです。特徴量エンジニアリングはデータのクリーニング、特徴量のスケール調整、特徴量のベクトル化という3つの部分が含めています。
ニュースは長いテキストの場合であれば、文章の全体をタスクとして入力すると、いい分類結果を得ることが難しいです。 自然言語処理タスクでは、データクリーニングと特徴量のスケール調整が一般的にデータを処理する前に欠けてはいけないプロセスです。現在、自然言語処理の活用場面とアルゴリズムの選択肢は比較的に限られています。しかし、このようなデータの前処理がビジネスを成功させるための重要な一環となっています。
1)データクリーニング
データクリーニングは、主にテキストの品質を向上させ、各データ項目のテキストを統一なフォーマットで揃えています。具体的に以下のことを含めています。
🔹htmlタグや絵文字などの特殊記号を削除したり、置き換えたりすることができます。
🔹ニュースに関係のないテキスト(例えば、Webサイト名など)を削除します。
🔹演算量を減らすために重複したテキストを削除します。膨大な長さのテキストがある場合はSimHashアルゴリズムを参照し利用することができます。
2)特徴量のスケーリング
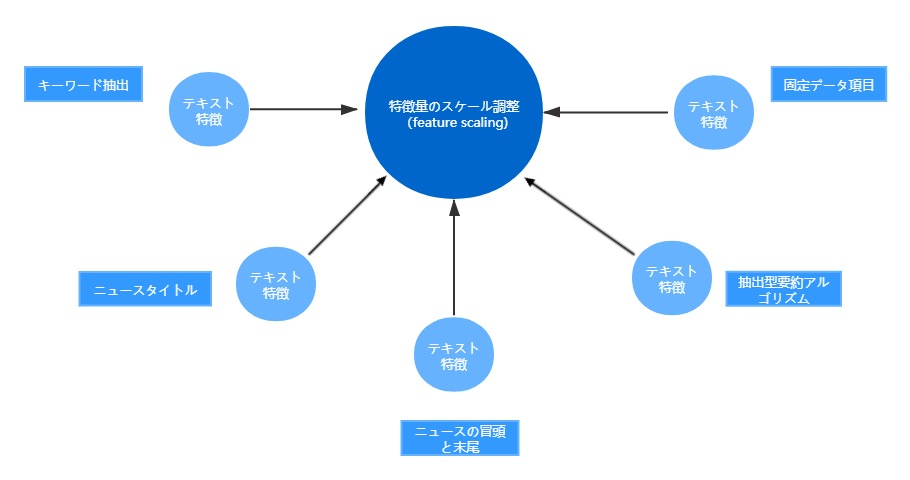
一方、特徴量のスケール調整とは、ビジネスニーズに応じて特定のコンテンツの抽出ことによって、モデルやアルゴリズムが注目して関心を持つ特徴を得るためのもので、ニュースデータの場合、通常は以下のように分類されます。
✅テキスト特徴
🔹キーワード抽出:統計のルールに従って情報量の多い若干キーワードを抽出します。例え:
– TextRankに基づくキーワードの抽出
– TF-IDFに基づくキーワードの抽出
🔹ニュースタイトル:ニュースタイトルは最も情報量の多いテキストです。多くのニュース分類はこの情報を利用しています。
🔹ニュース記事の冒頭と末尾:ニュースはより標準的な方法で書かれるために、よく冒頭と末尾にはニュースの最も重要な内容が含まれています。ただ、時々冒頭と末尾に広告とか、関連記事、記者名などのいくつかの不要な情報が含まれています。データクリーニングの前に、これをチェックする必要があります。
🔹抽出型の要約アルゴリズム: 抽出型の要約アルゴリズムは、ニュースコンテンツに対して、その重要性をステートメントの重要度ランキングとして理解することができます。ニュース記事の中でいくつかの重要なセンテンスを抽出することで、記事全体のメインコンテンツを判断します。その重要度ランキングを判断する基準は、主にキーワードの抽出、ニュースのタイトル、ニュースの最初と最後の段落から実現したのです。
- sumy: いくつかの記事要約生成アルゴリズム、ストラテジーが提供されています。
✅構造化された機能(非テキストの場合)
🔹投稿日時:投稿日時もニュースはどのカテゴリーに帰属するのに重要な基準となります。
🔹出版メディア、チャネルなど
3)特徴量のベクトル化
データクリーニングと特徴選別を経て、各ニュース記事が最も代表的なテキスト特徴と構造化特徴が得られました。 これらの特徴が原稿の内容に合っているかどうかを手動で判断することができます。人力でチェックしなくても、これらの特徴からニュース記事を分類することもできます。
テキストデータを計算する過程で、2つの問題があります。
① システムは、数値データで計算を行います。テキストは数値データではありません。
② 計算をする際には構造化されたデータが必要です。テキストは非構造化データです。
この二つの問題を解決するために、固定長の数値ベクトルを用いて、ニューステキストを構造化データに変換する必要があります。
簡単に言うと、特徴ベクトル化は各ニュース記事の特徴を、分類アルゴリズムが動作するための固定長のベクトルに集約することとして理解できます。 このベクトルが配置されている空間を特徴量空間(feature space)といいます。 このベクトルを機械学習の場合は特徴ベクトル(feature vector)と呼びます。この変換処理のプロセスは特徴埋め込み(embedding)あるいはフィーチャー・プロジェクション(feature projection)とも呼ばれています。
以上のプロセスをうまく実装されていれば、2つの特徴ベクトルの座標が特徴空間内で近ければ近いほど、2つの特徴ベクトルの内容が似ていて、同じ分類に属する可能性が高いと判断できます。
✅テキスト特徴
🔹単語ベクトル:単語ベクトルは,自然言語処理の基本的なタスクであり、類似した用法(文脈)を持つ単語が類似したベクトルに対応するように単純なニューラルネットワークを学習させることで得られるものである。 このアプローチは、「言葉の意味はその文脈と密接に関係している」という言語学の「文脈理論」に基づいています。 一般的に使用されているワードベクターの種類は、Word2Vec、GloVeなどで、タスクによって性能が若干異なります。
- テキストの符号化:単語ベクトルは、テキストを計算可能な意味的特徴ベクトルに統一するもので、これをさらに拡張して、2つの方法でテキストの段落を得ることができます。
- 文字と単語ベクトルの和算符号化:短い文(ニュースのタイトル)やキーワードの特徴の場合、単語と単語ベクトルを直接和算に使用し、複数の単語やフレーズの特徴ベクトルを統合することができます。
🔹モデルの符号化:長文の場合は、単語ごとに(word-by-word)単語ベクトルをモデル(Bi-LSTM、TextCNNなど)に入力し、入力された単語を判断し、できるだけに長文のテキストの特徴を残っています。
✅ 非テキスト的な特徴
🔹テキスト以外の特徴量のベクトル化は比較的簡単で、計算のモデルを入力する必要がある場合は、数値的に表現された特徴量を直接テキスト特徴量のベクトルにつなぎ合わせることができます。そうではない場合は、テキスト特徴量のベクトルに統合せず、時間によるグループ化など、後続のロジックで処理することもできます。
4)ニュースの分類
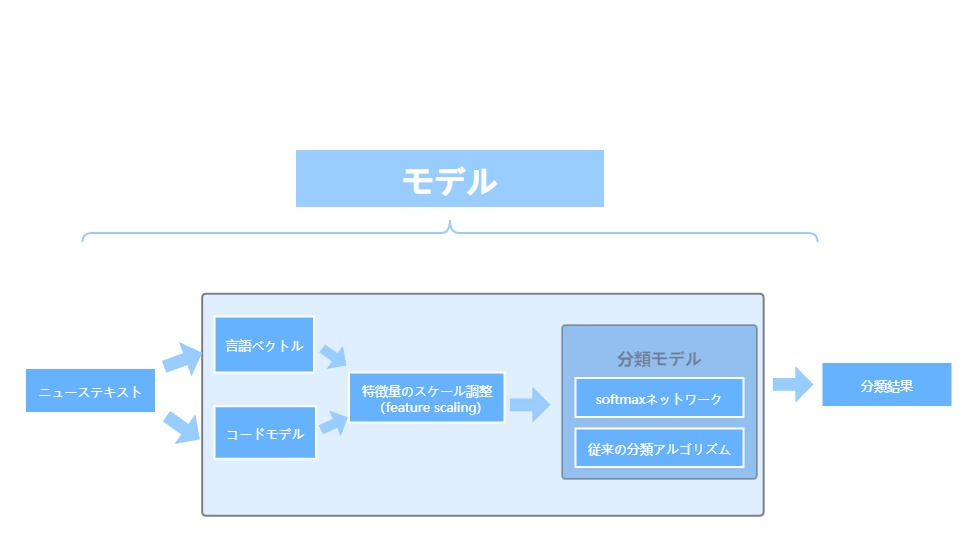
テキストの特徴が構築された後に、分類作業は非常に簡単になります。特徴ベクトルをsoftmaxネットワークに渡すとか、ベクターマシン(SVM)などの従来の分類アルゴリズムを使用するとか、ニュース分類を簡単に実現できます。 一般的に、softmaxソフトマックスネットワークベースの分類モデルの場合は、 エンドツーエンドモデルとしてコーディングモデルと統合されることが多い。BERT などの一部のコーディングモデルの場合は消耗を考慮すると、よりよいデバイス上で一般的な機能のコーディングモデルを実行することも可能であり、複数のプロジェクトでコーディングモデルのセットを再利用することができます。
特徴ベクトルに基づいて、これまでの分類タスクだけではなく、類似性メトリックによってニュースの類似性をさらに定量化して比較することができます。 自然言語処理でよくコサイン類似度を使用します。
分類が完了すると、コンテンツ推薦アルゴリズムとユーザープロファイリングを使って、個人の好みに応じてニュースを推薦することができます。




