近年、ビッグデータ解析や競合分析、市場調査の分野においてデータの収集・活用が重要になっています。しかし、膨大なWebサイトの中から手作業でデータを収集するのは非効率です。
このような課題を解決する手段として、Webスクレイピングツールがあります。
Webスクレイピングツールは、インターネットの情報を収集・保存・分析に役立ちます。そのWebスクレイピングツールで、重要な役目を持つのが「Webクローラー」です。
本記事ではプログラミング初心者の方向けに、簡単なWebクローラーの構築方法とその仕組みについて解説します。実際に構築をしなくても、Webクローラーの仕組みを理解することで、データ活用の幅が広がり、ITリテラシーの向上にもつながります。ぜひ参考にしてみてください。
Webクローラーとは?
Webクローラーとは、インターネット上のWebサイトを自動的に巡回し、ページのデータを取得するプログラムです。Webクローラーを使うことで、Webサイトを巡回してページの構成や内容を把握し、必要な情報を効率的に取得できます。
Webクローラーは、次のような手順で動作します。
- 開始URLを設定
クローラーが最初に訪問するページのURLを指定します。
- ページのURLを取得
指定したURLに対してHTTPリクエストを送信し、WebページのHTMLデータを取得します。
- リンクを解析して新しいURLを取得
取得したHTMLの中から、他のページへのリンクを抽出し、新たなURLリストを作成します。
- 新しいページに移動し、同じ処理を繰り返す
取得したリンクをもとに、次のページに移動してHTMLを取得し、さらに新しいリンクを発見する作業を繰り返します。
- データの保存
収集したデータを、データベースやファイル(CSV、JSON、SQLなど)に保存します。
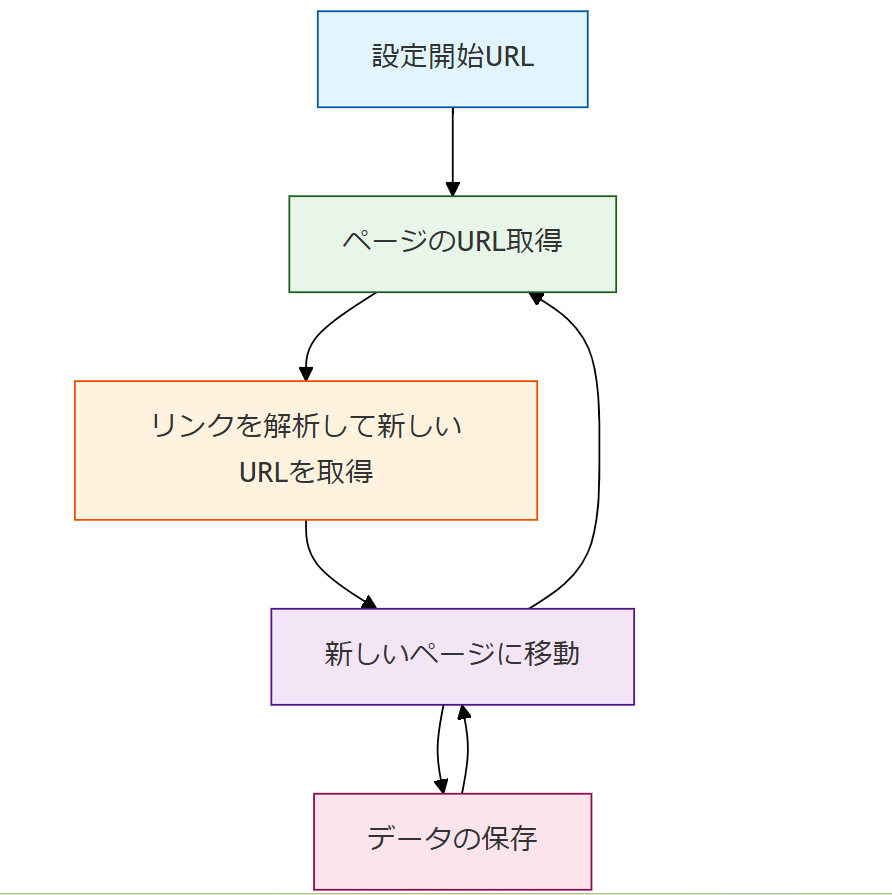
このプロセスを繰り返すことで、Webクローラーはインターネット上の膨大な記事やページを巡回し、必要なデータを効率的に取得します。クローラーの設計次第では、特定のテーマに関連する記事のみを収集したり、特定のWebサイトに絞って情報を取得したりすることも可能です。
なぜWebクローラーが必要なのか?
インターネット上には無数のWebページが存在し、日々膨大な量の情報が更新されています。しかし、その情報を手作業で収集し、整理するのは現実的ではありません。Webクローラーは、この問題を解決するために使われます。
例えば、企業が競合サイトの価格情報を定期的に取得したり、研究者が特定の分野のニュース記事を収集したりする際に、Webクローラーが役立ちます。大量のWebページを手作業で確認するのは非現実的ですが、クローラーを使えば、短時間で自動的に情報を収集できます。
さらに、Webサイトの更新頻度が高い場合は、情報を一度取得するだけではすぐに情報が古くなってしまいます。Webクローラーを活用すれば、新しい記事や価格変動、製品情報の更新を自動で取得し、データを常に最新の状態に保つことが可能です。
Webクローラーで何が実現できるのか?
Webクローラーを活用することで、どのようなことが実現できるのでしょうか。主な用途を3つ解説します。
1. コンテンツ集約(コンテンツアグリゲーション)
コンテンツアグリゲーションは、Webメディアやブログメディアなど、さまざまなメディアのコンテンツを1つのプラットフォームに集約します。
例えば、情報配信サイト「SmartNews」は、複数のニュースメディアから記事をクローリングし、コンテンツ毎に記事を分類・配信しています。
参考:誰でも掴めるビジネスチャンスは?コンテンツ集約が答える
2.感情分析(センチメント分析)
感情分析とは、製品とサービスに対するユーザーの態度や感情を分析することです。感情分析を行うためには、対象製品のレビューやコメントを収集し、データとして抽出する必要があります。
参考:YouTubeコメントをスクレイピングで自動取得する方法
3.見込み客の獲得
これまで見込み客を獲得するには、積極的に展示会やセミナーなどへの参加や、訪問営業などで名刺交換を行う必要がありました。入手した名刺に書かれた顧客情報はExcelなどに整理し、その後は一社一社アプローチを繰り返し、商談化へとつなげていきます。
しかし、こうしたアナログなやり方をしなくとも、Webクローラーであれば、人気のWebサイト(リクナビ・食べログ)や、iタウンページなどから企業情報を自動で収集できます。
Webクローラーをゼロから構築する方法とは?
Webクローラーをゼロから構築する方法は、大きく分けてプログラミング言語を使用する方法と、Webスクレイピングツールを活用する方法の2つがあります。それぞれの手法にはメリット・デメリットがあるため、目的やスキルレベルに応じて適切な方法を選びましょう。
どちらも知っておけば、状況に合わせて使い分けができるようになりますので、ぜひご覧ください。
1.プログラミング言語を使う(Python)
一般的な方法としては、プログラミングを使ってWebクローラーを自作する方法です。PHP、Java、C / C ++などを使えばWebクローラーをゼロから作成できます。しかし、非プログラマーからすればイチからプログラミングを学ぶことは容易ではありません。
数あるプログラミング言語の中で、比較的簡単なプログラミング言語として人気なのが、「Python」です。Pythonの文法は、簡単な英語がわかる方であれば、理解しやすいのが特徴です。
以下はPythonで記述したWebクローラーのコード例です。
指定したURLのHTMLを取得し、他ページのリンクを抽出します。
Pythonは比較的扱いやすい言語といわれていますが、プログラミング経験がない初心者が自力でゼロからWebクローラーを構築できるようになるには、少なくとも数ヶ月間のプログラミング学習が必要です。初心者のPython学習は「Progate」「ドットインストール」などがおすすめです。
2.Webスクレイピングツールを活用する
プログラミング学習に掛ける時間がない場合や、プログラミングを使わずに手っ取り早くWebクローラーを構築したい方であれば、Webスクレイピングツールの活用が最適です。
Webスクレイピングツールの「Octoparse(オクトパス)」はコード記述を一切行わないノーコードツールです。独自のエディタ画面から、ドラッグ&ドロップでの直感的な操作だけで、クロールやスクレイピングが可能です。
例えば、Google検索結果をクロールして、特定のキーワードに関連するページを収集することも可能です。さらに、取得したWebページからタイトルや価格、レビューなどの特定のデータを抽出するスクレイピング機能も備えており、クローリングとスクレイピングを組み合わせたデータ収集ができます。
特に、食べログ、リクナビ、Amazon、Indeed、Google Maps、X(旧Twitter)、YouTubeなど、よく利用されるサイト向けのテンプレートも充実しています。
最後に、Octoparseを使ってX(旧Twitter)から特定のポストをスクレイピングする手順を紹介します。
Octoparseを使ってX(旧Twitter)から特定のツイートをスクレイピングをする
ステップ1:Octoparseをパソコンにダウンロードします。ダウンロードが完了したら、Octoparseを起動し管理画面にアクセスしましょう。
ステップ2:テンプレート選択画面>カテゴリー「SNS」>Twitter Scraperを選択しクリックします。Twitterテンプレートは6種類あるので(2025年2月時点)、目的・用途に合ったものを選びましょう。ここでは、「Twitter Scraper (by Account URL)」を選択します。
※各テンプレートの違いは以下を参照
| Twitter Scraper (by Keywords) | キーワードを入力し、ポストの内容、リプライ数、リツイート数、いいね数、閲覧数などをスクレイピングする。 |
| Get Twitter Cookies | クッキーの取得。 |
| Twitter Scraper (by Account URL) | Twitterのアカウントページから、各ポストの投稿内容、投稿日時などの情報を抽出します。 |
| Twitter Scraper (by hashtag) | キーワード/ハッシュタグを使って最新のポスト内容、返信数、リポスト数、いいね数、閲覧数などをスクレイピングすします。t URL_Twitter |
| Tweets & Comments Scraper (by Search Result URL) | ポスト内容、投稿者、ツイートの投稿時間、返信内容、返信送信者、返信時間などをスクレイピングします。 |
| Twitter Follower List Scraper | アカウントからフォロワーおよびフォロー情報を取得します。 |
ステップ3:テンプレートを起動したら、パラメーター入力欄に次の情報を入力します。
- スクレイピングしたいXアカウント名 (最大10 個まで/ 1 行に 1 つ入力)
- ページ サイズ (スクレイピングしたいページの数)
- 入力後、「保存して実行」をクリックします。
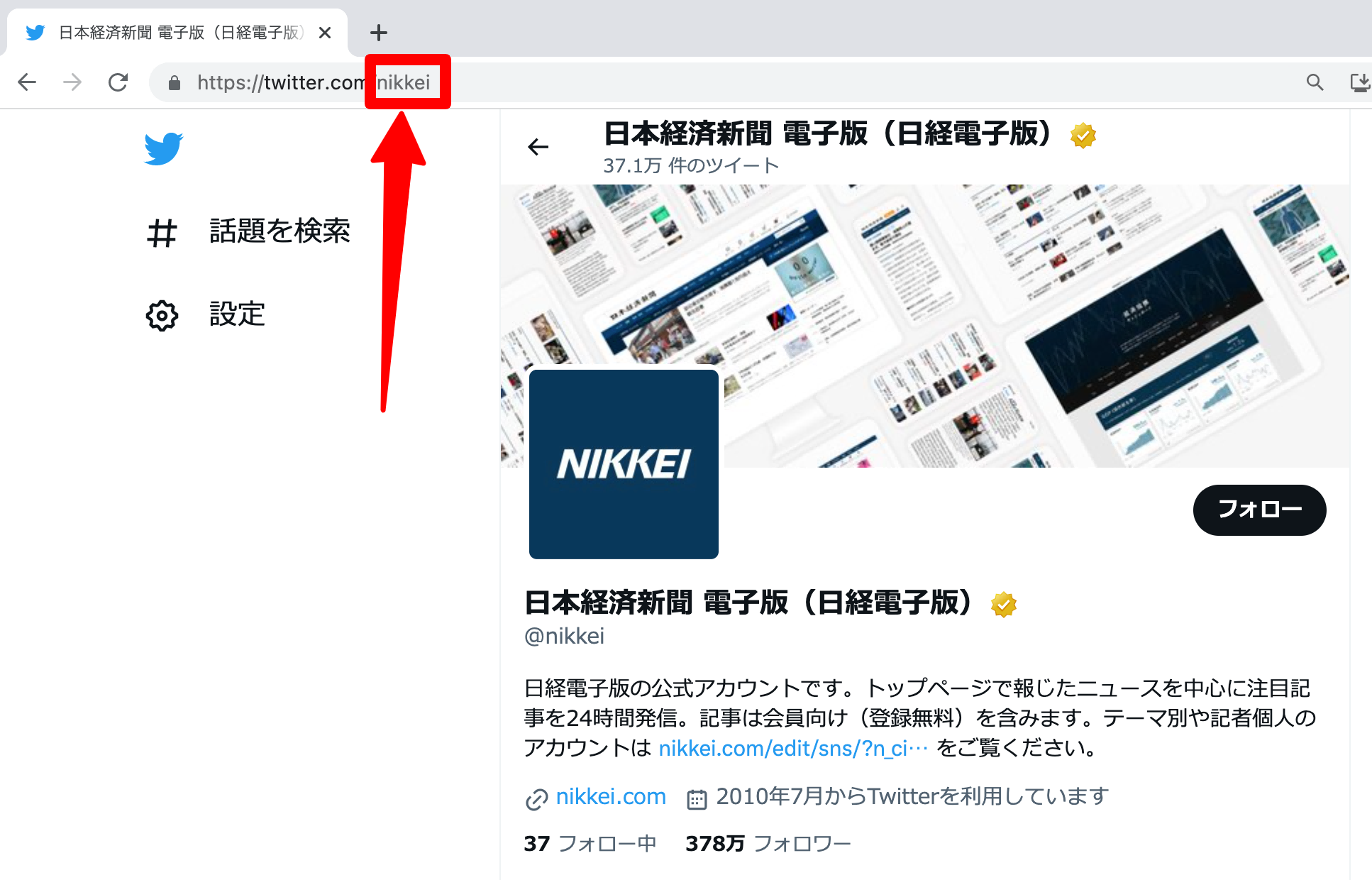
例えば、「日本経済新聞 電子版(日経電子版)」のアカウントの場合は、アカウント名「nikkei」を入力します。
ステップ4:抽出方法をローカル抽出またはクラウド抽出のいずれかから選択します。抽出するデータ量が少なければローカル抽出でも対応可能です。一方、クラウド抽出の場合は抽出スピードが20倍となりますが、有料プランの契約が必要となるため注意しましょう。
ステップ5:タスクを実行開始すると、データ抽出が開始されます。すべてのデータが抽出されるまで、数分程度掛かるため少し待ちましょう。抽出がすべて完了すると管理画面上に抽出されたデータが表示されます。
例えば、日経電子版のツイートデータが次のように抽出されました。
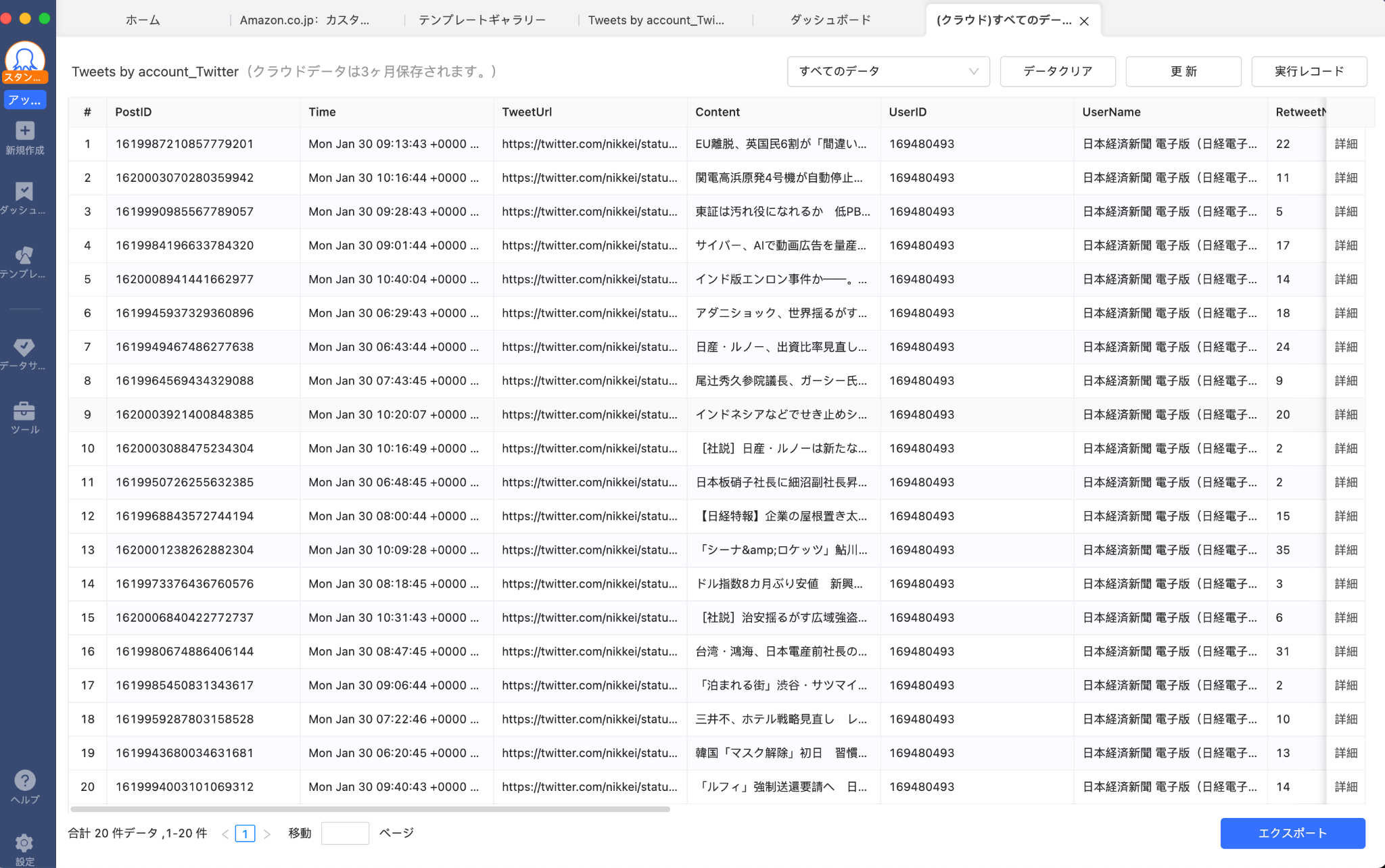
画面右下の「エクスポート」をクリックすると、抽出データを外部ファイル(Excel、CSV、HTML、JSON形式など)にエクスポートできます。
詳しい手順はこちらの記事をご覧ください。
参考:無料でX(Twitter)からデータをスクレイピング・取得する方法を解説!
Octoparseを使用する際の注意点
Webサイトの構造が複雑である場合、テンプレートモードでは思うようなWebスクレイピングを実行できない場合があります。
複雑な構造を持つWebサイト(ログインや検索が必要なサイトなど)の場合は、「カスタマイズモード」を活用しましょう。カスタマイズモードは自由度が高く強力なWebスクレイピングモードです。より柔軟なワークフローを設定できる上、JavaScript、AJAXなど動的なサイトにも対応可能です。
まとめ
この記事では、Webクローラーの概要と、ゼロからWebクローラーを構築する方法を紹介しました。Webクローラーは、膨大なWebサイトの中から欲しい情報を欲しい時に収集する際に役立つ手法です。
データ活用が求められる現代社会において、必要な情報を素早く収集できるかどうかは、ビジネスの成長や意思決定のスピードに直結します。
「プログラミングを今から覚えるのは少し難しそう」と感じる方や、「Webスクレイピングを体験してみたい」と感じた方は、ノーコードWebスクレイピングツールのOctoparse(オクトパス)を活用してみてください。
Octoparseは無料から利用でき、クラウドベースなのでアカウント発行だけですぐに実行できます。Octoparseでは、チュートリアルやサポートも充実しているので、操作に困った場合でも安心して利用できます。データを活用する第一歩として、Webクローラーを使った情報収集を試してみてはいかがでしょうか。




