Webスクレイピングを実行していると、403エラーが表示されて、データの抽出ができないことがあります。403エラーには、さまざまな原因があります。この記事では、Webスクレイピングの初心者の方に向けて、403エラーの原因や403エラーの解決策を解説します。
403エラーとは
「403 Forbidden」とは、そのWebサイトが閲覧禁止の状態であることを示すHTTPステータスコードです。HTTPステータスコードとは、Webブラウザから送信されるリクエストに対して、Webサーバーから返信される処理結果を示す3桁の数字を指します。すなわち、403がHTTPステータスコードになります。
403エラーのさまざまな原因について
403エラーが発生する原因はさまざまです。ほとんどの場合は、管理者側のミスが原因で403エラーが発生します。よくある403エラーの原因としては、以下のようなものがあります。
1・アクセス権限の設定ミス
2・indexファイルが存在しない
3・Webサイトへのアクセスが集中している
4・Webサーバーの正しいディレクトリに、コンテンツがアップロードされていない
5・DNSの設定ミス
ここでは、これらのさまざまな原因について解説します。
1・アクセス権限の設定ミス
Webサイトの管理者が、アクセス権限の設定をミスしているケースがあります。この場合、閲覧許可であるべき設定が閲覧拒否の設定になっています。ファイルやディレクトリのアクセス権のことを、パーミッションといいます。このパーミッションの設定で、読み込み拒否になっているファイルにアクセスすると、403エラーが発生します。また「.htaccess」の記述ミスで、403エラーになる場合もあります。
2・indexファイルが存在しない
Webサイトのトップページのファイル名は「index.html」または「index.php」でなければいけません。indexファイルが存在しない場合は、403エラーが表示されます。
3・Webサイトへのアクセスが集中している
Webサイトに、アクセスが集中していると403エラーの表示がでます。レンタルサーバーでは、サーバー負荷の低減のために、アクセス超過になると403エラーになってしまいます。
4・Webサーバーの正しいディレクトリに、コンテンツがアップロードされていない
Webサーバーの正しいディレクトリに、コンテンツがアップロードされていない場合も403エラーが表示されます。この問題の原因は、FTPクライアントの設定の間違いやディレクトリが不適切の場合などがあります。
5・DNSの設定ミス
DNSの設定が間違っていると、403エラーが表示されます。DNSとは、Domain Name Systemの略でIPアドレスとドメインとを紐づけるシステムです。
Webスクレイピングで403エラーが発生するのはなぜ?
Webスクレイピングで403エラーが発生するのは、いくつかの理由があります。Webスクレイピングを正常に完了させるためにも、403エラーの原因を特定しなくてはなりません。
Webサイトからデータを抽出する際に、403エラーが表示される原因としては、以下の理由が考えられます。
1・アクセス権限もしくは所有権がない
2・Webサーバーがアクセスを拒否している(ブラウザ以外からのリクエストを拒否している)
最近のWebサイトは、スクレイピング対策をしているケースがあります。その場合はWebサーバーが、受け取るリクエストヘッダー内の情報(ユーザーエージェントが含まれる)を分析して、スクレイピングボットと判断した場合にアクセスを拒否します。そのため、Webブラウザからは正常に閲覧できますが、クローラーよりスクレイピングをしようとすると403エラーになってしまいます。
スクレイピング時の403エラーの対処方法
403エラーが表示された際には、原因を特定して適切に対処する必要があります。ここでは、スクレイピング時の403エラーの対処方法について解説します。
1・ユーザーエージェント(デバイス)を切り替える
ユーザーエージェントとは、Webサイトにアクセスするデバイスやブラウザ、バージョン、使用言語などの情報のことです。スクレイピングにおけるユーザーエージェントは、デバイス+ブラウザになります。
ユーザーエージェントは、Webサイトにアクセスした際に、そのWebサイトのサーバーに送信されます。ユーザーエージェントを受信したサーバーは、ユーザーエージェントの情報をもとに、適切なWebページの情報を返します。
具体的な例では、スマートフォンのブラウザでWebサイトにアクセスした際に、サーバーはユーザーエージェントをもとにして、スマートフォンに適したレイアウトのWebページを返します。
Octoparseのユーザーエージェント機能
Octoparseは、403エラーの対処方法として、ユーザーエージェント機能を備えています。ユーザーエージェントを切り替えることにより、403エラーを回避します。ここでは、Octoparseのユーザーエージェント機能を解説します。
A・内蔵ブラウザ
Octoparseは、主要なユーザーエージェントをあらかじめ搭載した内蔵ブラウザがあります。この内蔵ブラウザを切り替えることで、403エラーの対処が可能です。Octoparseでは、新しいサイトはsafari 15.1、古いサイトはChrome 78.0 for Linuxの使用を推奨しています。
内蔵ブラウザの切り替え方法
a・画面右上の「タスク設定」をクリック
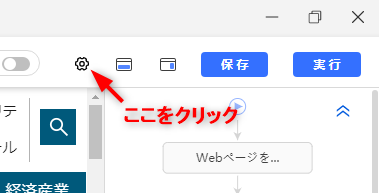
b・「実行設定」→「内蔵ブラウザ」を選択
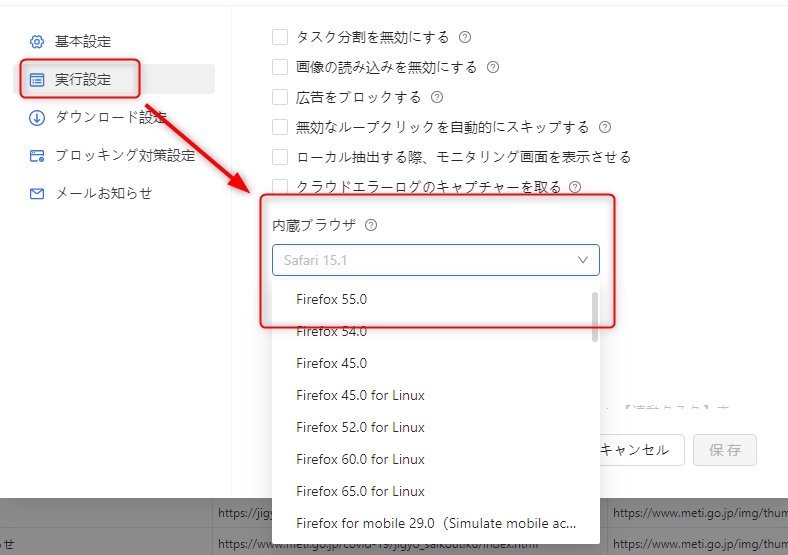
c・主要なブラウザ(モバイル版を含む)だけでなく、Googleのボット(google bot)もあります。

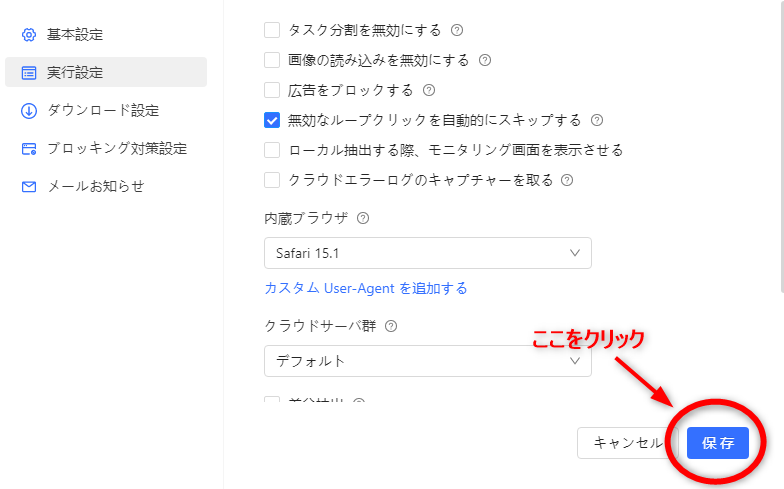
d・内蔵ブラウザを切り替えて、保存ボタンを押します。これで、新しいユーザーエージェントが対象Webサイトのサーバーに送信され、Webページも自動で更新されます。
B・カスタムユーザーエージェント機能
内蔵ブラウザの切り替えを行っても403エラーが表示される場合は、カスタムユーザーエージェント機能の使用をおすすめします。カスタムユーザーエージェント機能であれば、実際に動作している自身のユーザーエージェントであるため、403エラーのリスクを軽減できます。
ここでは、Octoparseのカスタムユーザーエージェント機能で、403エラーを回避する方法を解説します。
ユーザーエージェントを取得する
方法1
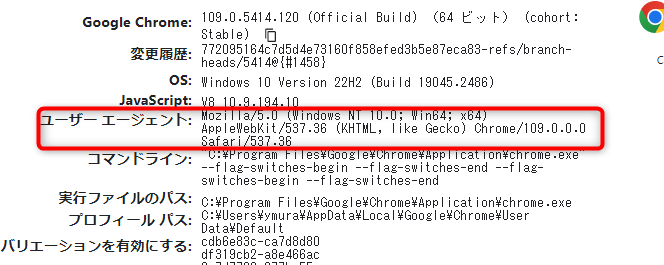
Chromeブラウザを使った例で解説します。最初にアドレスバーに「chrome://version/」と入力します。入力をすると、以下の画像にような情報が表示されます。画像の赤枠にある[ユーザー エージェント]以降の情報をコピーして、Octoparseに貼り付けます。
FirefoxやEdgeなど「chrome://version/」に対応していないブラウザもあります。その場合は、以下の方法その2を使います。方法2は、Chromeにも対応しています。
方法2
a・Webページを右クリックして「検証」を選択します。それにより、コンソールにアクセスができます。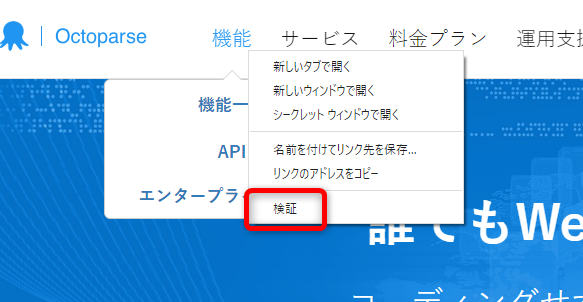
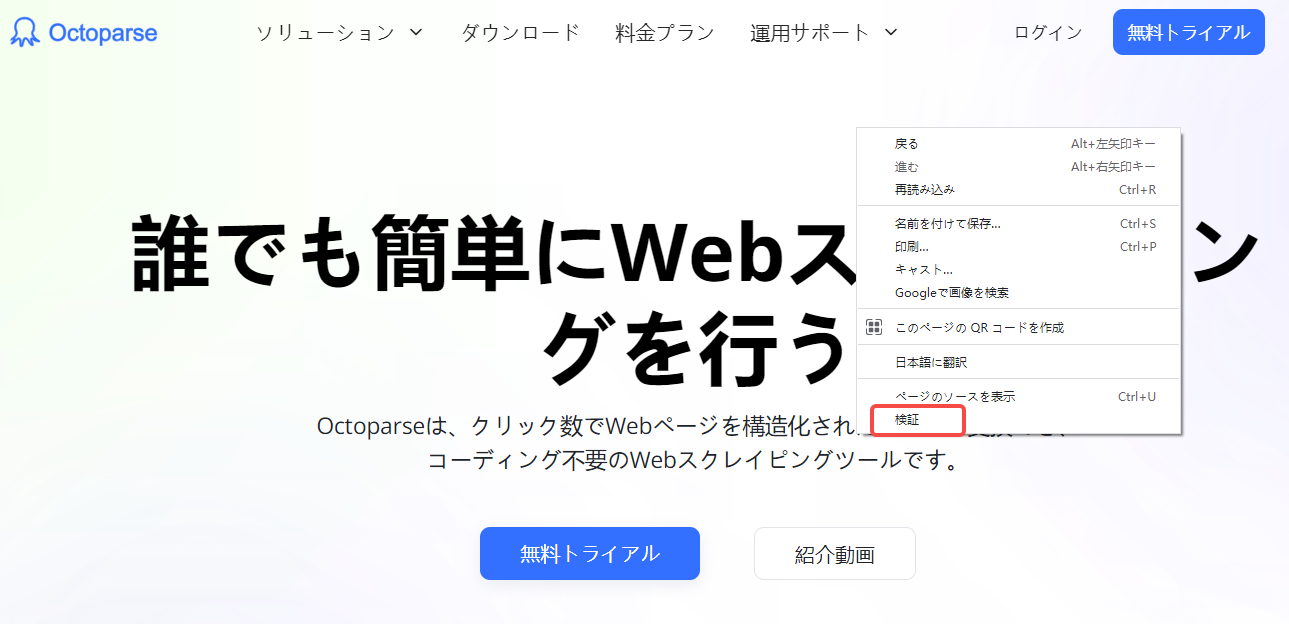
b・次に、Webページを再読み込みします。コンソールの「ネットワーク」タブをクリックすると以下の画面が表示されます。
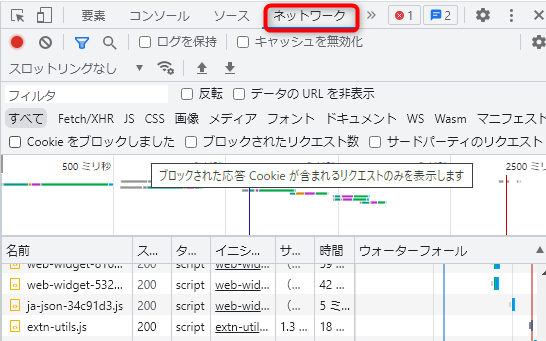
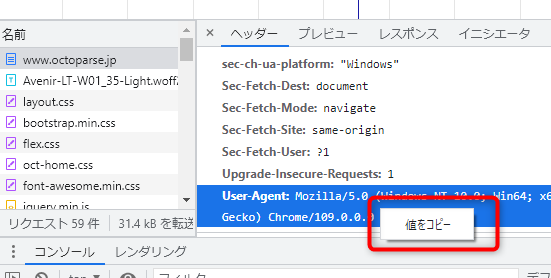
c・「名前」から表示されたリクエストをクリックします。次に右側の「ヘッダー」タブをクリックして、下部のウィンドウにあるUser-Agentを見つけます。
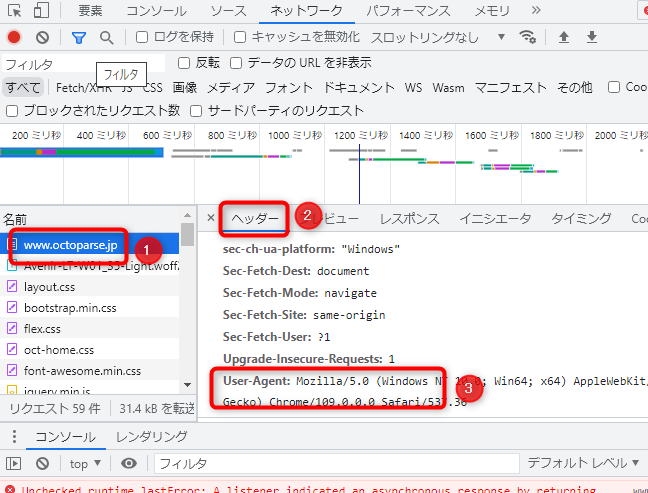
d・User-Agentの行から、ユーザーエージェントの文字列をコピーします。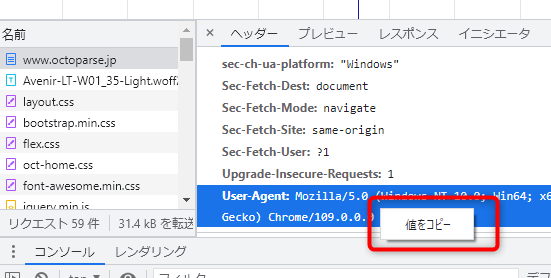
ユーザーエージェントをOctoparseのタスクに適用する
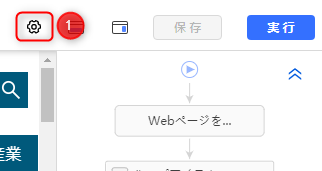
a・「タスク設定」ボタンを押して、設定画面に入ります。
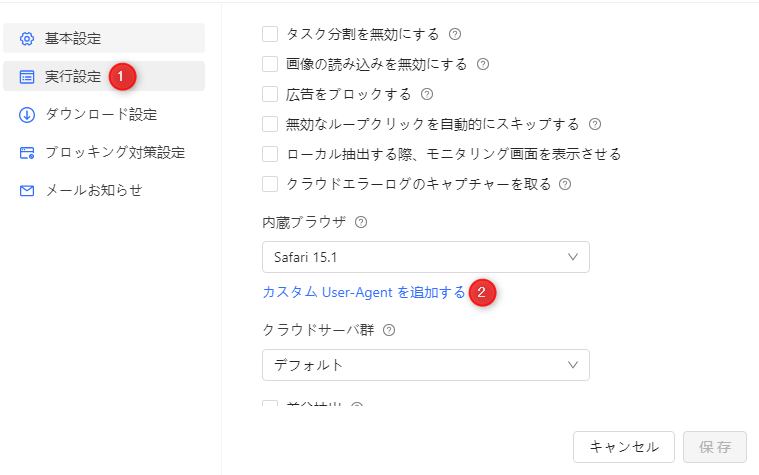
b・「実行設定」→「カスタムUser-Agentを追加する」をクリック。
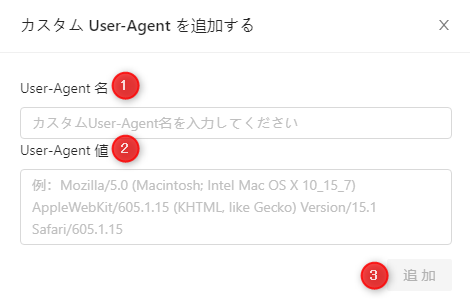
c・「User-Agent名」は任意の名前を入力します。「User-Agent値」は、コピーしたユーザーエージェント値を貼り付けます。その後「追加」をクリックして保存します。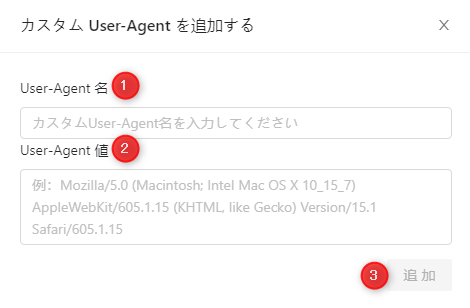
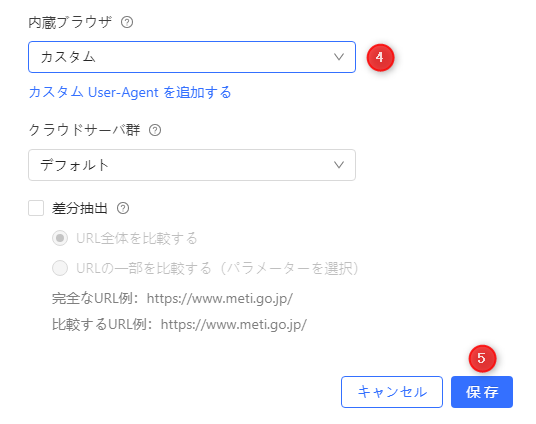
d・内蔵ブラウザから、先ほど任意の名前を付けたカスタムUser-Agentを選択します。その後、保存をクリックします。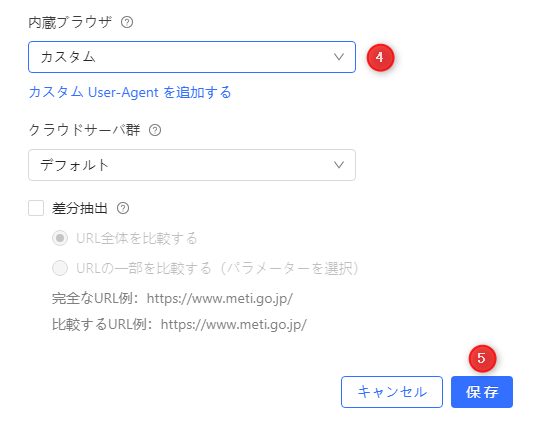
ブラウザの変更
ブラウザの情報はユーザーエージェントに含まれているため、スクレイピングするWebサイトのサーバーにブラウザの情報が伝えられます。同じユーザーエージェントで、頻繁にWebサイトをスクレイピングすると、Webスクレイピングボットとして検出されてしまいます。その結果、スクレイピング対策として403エラーが表示されます。そのため、403エラーを避けるには、ブラウザの変更が必要です。
内蔵ブラウザのブラウザ(ユーザーエージェント)自動切り替え機能
スクレイピング対策による403エラーを回避するために、Octoparseの内蔵ブラウザには、ブラウザ(ユーザーエージェント)自動切り替え機能があります。
内蔵ブラウザの自動切り替えの設定方法
a・「タスク設定」ボタンを押して、設定画面に入ります。
b・「ブロッキング対策設定」→「ブラウザの自動切り替え」→チェックボックスをオンにする。
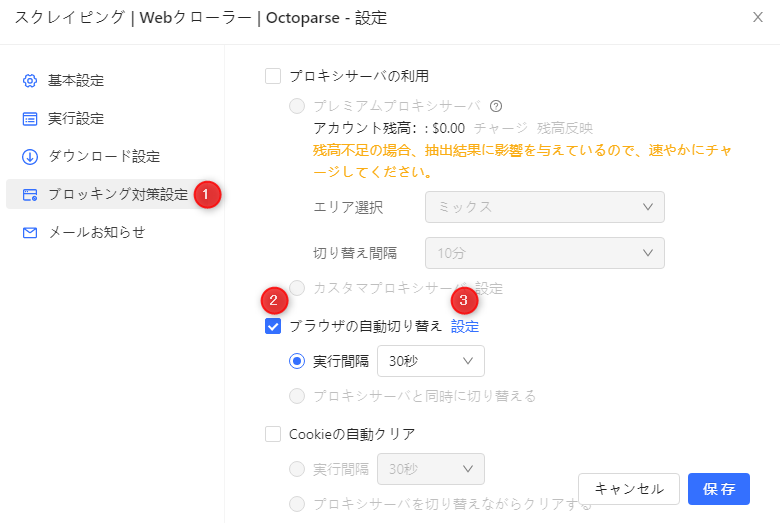
c・「設定」をクリックして、ブラウザリストから必要なブラウザを設定します。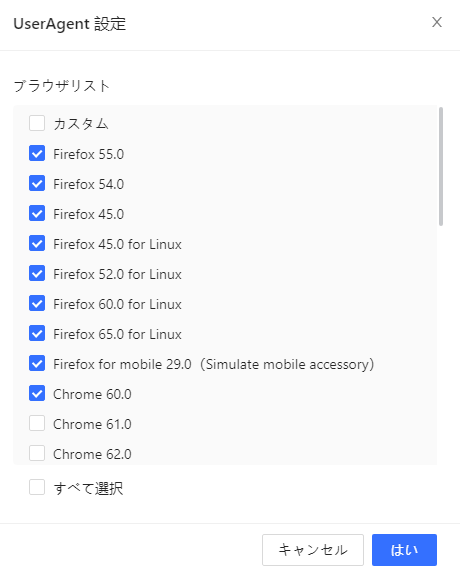
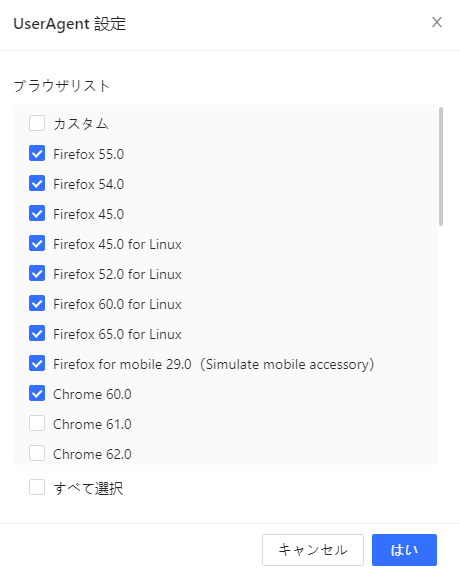
Octoparseが「PCからWebサイトにアクセス」と設定するには、「すべて選択」のチェックボックスをオンにして、「Chrome / Firefox / Safari for mobile」のチェックボックスはオフにします。Octoparseが「モバイル経由でWebサイトにアクセス」と設定するには、「Chrome / Firefox / Safari for mobile」のチェックボックスのみをオンにします。
※選択したブラウザが、全てのWebサイトで動作するわけではありません。
d・「保存」をクリックして変更を保存します。
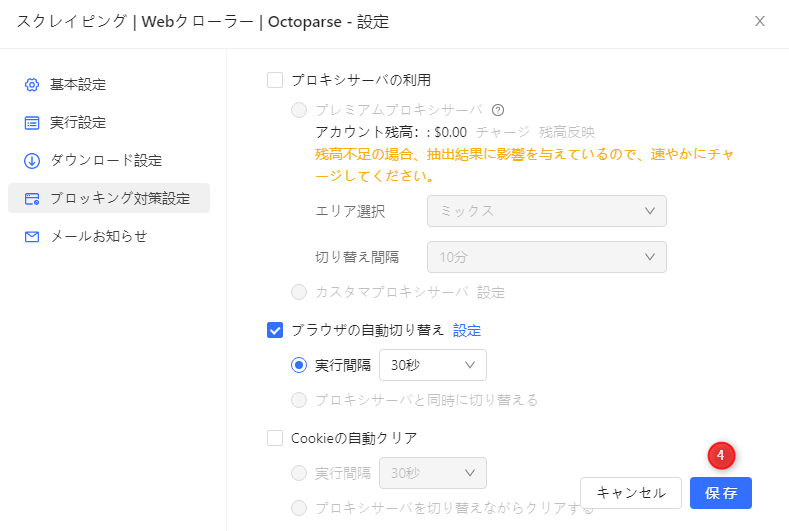
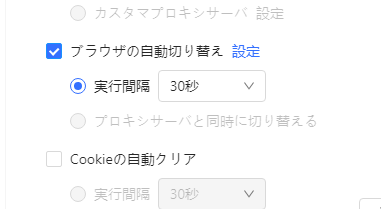
e・「実行間隔」のチェックボックスをオンにして、ブラウザを切り替える時間を設定します。
再試行機能の設定
スクレイピングの際に、Webページが正常に読み込まれないケースがあります。Webページが正常に読み込まれないと、スクレイピングに支障が出てしまいます。Octoparseは、その問題を回避するために、Webページの読み込み再試行の機能があります。
A・ワークフローの「Webページを開く」もしくは「アイテムをクリック」をクリックし、再試行タブを選択します。
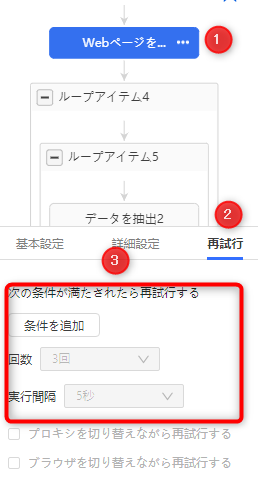
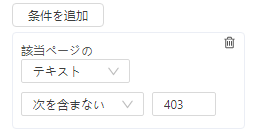
B・「条件を追加」をクリックすることで、再試行の条件を指定することも可能です。
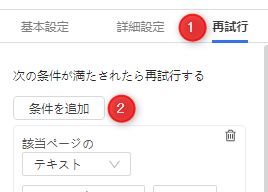
b.1 「URL /コンテンツ/要素(XPath)」オプションと「次を含む/次を含まない」オプションの設定
読み込みを失敗すると、ブラウザに「500 Internal Server Error」や「Too many requests」などのようなメッセージが表示されます。これらのメッセージの特定の文字列を、テキストボックスに再試行の条件として入力が可能です。特定の文字列を入力して「次を含む」を選択します。Octoparseが文字列を検出した場合は、読み込みの再試行を行います。
XPath(要素や属性を指定して、情報を取得する簡潔な言語)を条件にすることも可能です。正常に読み込まれたときのXPathをテキストボックスに入力し、「次を含まない」を選択します。それにより、条件のXPathが検出されない場合は、読み込みの再試行が行われます。
また「条件を追加」をクリックすることで、複数の条件設定も可能です。
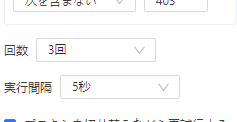
b.2 「回数」と「実行間隔」の設定
再試行の無制限の繰り返しを避けるために、再試行の最大回数の設定が必要です。設定することで最大回数の値に達すると、再試行が停止されます。
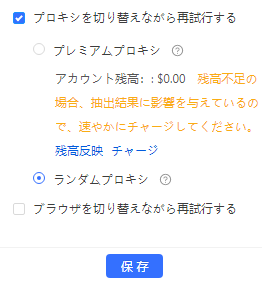
b.3 「プロキシを切り替えながら再試行する」の設定
短時間のWebサイトへのアクセスを繰り返すことで、スクレイピング対策として403エラーが表示されるリスクが高まります。それを避けるために、プロキシを切り替えながら再試行が可能です。
IPローテーションを使う
Webサイトにはスクレイピング対策として、頻繁に同一IPからのスクレイピングがあるとWebスクレイピングボットとして認識され、403エラーを表示することがあります。その対策として、複数のIPを使用しアクセスするIPローテーションがあります。
ここでは、OctoparseのIPローテーション機能を用いた403エラーの対処方法について解説します。
1・カスタムプロキシサーバ
無料または有料のプロキシサーバーを持っている方は、Octoparseのカスタマイズモードから「ローカル抽出」が利用できます。「ローカル抽出」は、ローカルコンピューターからのみ追加可能です。
2・Octoparseのクラウドサーバを利用する
Octoparseのクラウドサービスは、それぞれ唯一のIPアドレスを持つ数千のクラウドサーバーから構成されています。また、IPアドレスプール(割り当てを固定的に行わないアドレスの範囲)も常に更新しています。
カスタマイズモードから「クラウド抽出」を利用した場合、6~20のクラウドサーバーがランダムに割り当てられます。そして、さまざまなIPを転換しながらスクレイピングを実行します。これにより、スクレイピングするWebサイトからのスクレイピング対策による403エラーの可能性を最小限に抑えます。
3・プレミアムプロキシサーバ
抽出データ量が多い場合やスクレイピング対策が強いWebサイトであれば、Octoparseのプレミアムプロキシサーバを利用を推奨します。
他にも知っておきたいエラーコード一覧
ここでは、403エラー以外の知っておきたいエラーコードを紹介します。
401 Unauthorized
認証エラー。パスワードが必要なWebサイトに、送信したパスワードが間違っている。または、Webサイトの閲覧権限がない。
404 Not Found
Webサイトが見つからないときに表示されるエラー。Webサイトが削除またはURLが変わっているなどが当てはまります。
408 Request Timeout
リクエストの送信時間が、規定の制限時間内に終了しなかったときに表示されるエラー。
500 Internal Server Error
WebWebサーバ側がリクエストを実行できないときに表示されるエラー。閉鎖されたWebサイトの場合でも、表示されることがあります。
503 Service Unavailable
Webサーバにアクセス集中など大きな負荷がかかっている場合に、表示されるエラー。メンテナンス中など、一時的にリクエストを実行できない場合にも表示されます。
まとめ
この記事では、Webスクレイピングの初心者の方に向けて、403エラーの原因や403エラーの解決方法などを解説しました。Octoparseは、Webスクレイピング初心者の方でも安心して403エラーに対処できるように、さまざまな機能を備えています。この記事を参考にして、OctoparseでWebスクレイピングにチャレンジしてみてはいかがでしょうか。




