Webページから知りたい情報を手軽に収集したいと思ったことはありませんか?なにか調べ物をしていて大量のWebページを見る必要がある時や、とっても情報量が多いWebページを端から端まで見たい時などが該当します。そんな時は、手動で頑張るのではなく、プログラムにパパっとやってもらいましょう。ということでこの記事では、Pythonを使ってHTMLページからテキストやURLを取得する方法をご紹介いたします。サンプルコード付きなので、どなたでも簡単にお試しいただけますよ!ぜひ最後までご覧ください。
PythonでHTMLソースを取得する方法(サンプルコード付き)
ということで、まずはPythonを使ったHTMLソースの抽出方法をご紹介します。今回は以下の2種類のライブラリを使用した方法です。
Beautiful SoupでHTMLを取得する方法
1.まずはお使いのPCにBeautiful Soupをインストールします。Windowsはコマンドプロンプトで、Macの場合はターミナルを起動して下記のコマンドを打ち込みます。
Windowsの場合 : pip install beautifulsoup4
Macの場合 : pip3 install beautifulsoup4
2.インストールが終わったら、以下のサンプルコードを適当なテキストファイルにコピペし、◯◯.pyという名前で保存します。拡張子を”.py”とする点に注意しましょう。
3.ファイルが作成できたら、後は実行するだけです。例えばwindowsの場合は、下記の様にして実行します。
- コマンドプロンプトを起動し、先程作成したファイルがあるディレクトリまで移動します。
- 「Python ◯◯.py」と入力することで、ファイルを実行することができます(◯◯はファイル名)。
SeleniumでHTMLを取得する方法
1.はじめに、Seleniumのインストールを行います。例えばWindowsの場合は、コマンドプロンプトを起動して、下記のコマンドを実行します。
2.つづいて、SeleniumがWebブラウザにアクセスするために使用するWebDriverを下記サイトよりダウンロードします。WebブラウザはGoogle Chromeが推奨されていますので、WebDriverもChrome用のものを使用します。
3.後は先程同様にテキストファイルに下記のサンプルコードを入力し、拡張子を”.py“として保存するだけです。実行方法も先程同様です。
PythonでHTMLからテキストを取得する方法(サンプルコード付き)
ではつづいて、取得したHTMLから任意のテキストを抽出する方法をご紹介します。今回は、先程ご紹介したBeautifulsoupを使用した方法について解説します。
やり方はとっても簡単。Beautifulsoupの取得対象に”text”を指定するだけです。さらにここでは余計なテキストの取得をフィルタリングするために、HTMLの”H2”に絞ってテキストの取得を行っています。
PythonでHTMLからURLを取得する方法(サンプルコード付き)
最後のサンプルコード紹介では、HTMLからURL情報を抜き出す方法をご紹介いたします。今回もBeautifulsoupを活用した方法になります。
今回もやり方は非常に簡単で、HTMLで取得したテキスト一覧から、URLが記載されている部分のみを抜き出すだけです。「URL付きテキスト(URL)」という形式で出力されるので、わかりやすいですよ。
Python知識なしでWeb上のHTML、テキスト、URLなどを抽出する方法はあるのか?
ここまでの記事やサンプルコードを見て、これは難しそうだと感じた方もいらっしゃるかもしれません。ですがご安心ください。今回ご紹介するOctoparseというツールを使用すれば、誰でも簡単にWebページからHTMLやテキストを取得することができるようになります!Octoparseウェブスクレイピングツールなら数クリックでWebページの情報を抽出できるので、コードを書く必要なく、直感的な操作で必要な情報を収集することができるようになるんです。
Octoparseの特徴:
- 直感的な操作で誰でも簡単にスクレイピングができる
- 様々なWebサイトに対応しており、ページの取得制限がない
- 色々な出力形式に対応している
- 日本語対応なので安心!
Octoparseの使い方:
【抽出開始】
1.まずはOctoparseの公式サイトにアクセスし無料登録した後、ダウンロードを実施します。
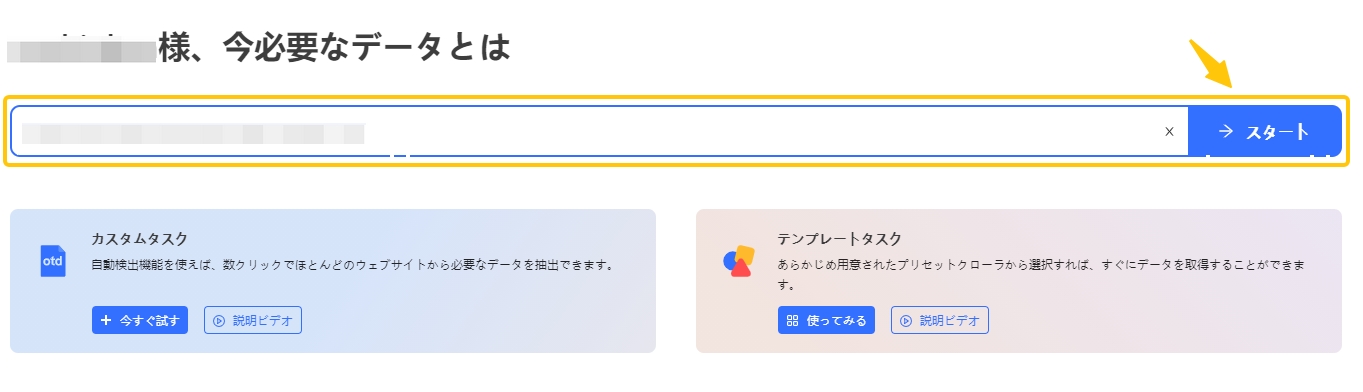
2.ツールを起動し、スクレイピングしたいWebページのURLを画面中央の検索欄に入力します。入力したら、「スタート」をクリックします。
【HTMLの抽出】
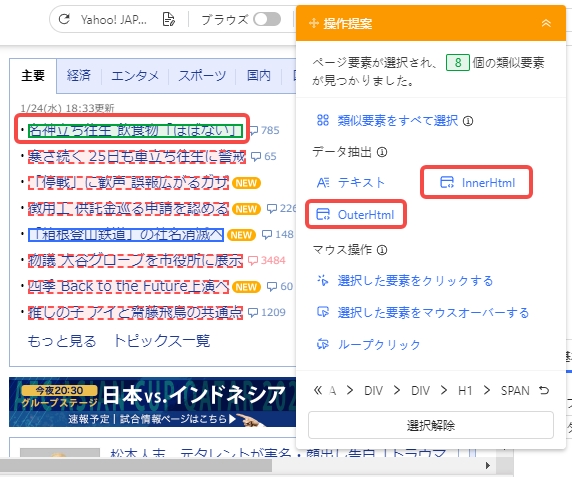
1.Octoparseの画面上にて、抽出したいテキストや画像をクリックします。選択された領域は緑色で表示されます。
2.ポップアップメニューより、「InnerHTML」または「OuterHTML」をクリックします。
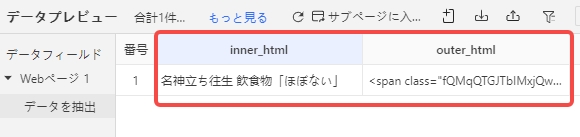
3.画面下部に選択箇所のHTML情報が表示されます。
【テキストの抽出】
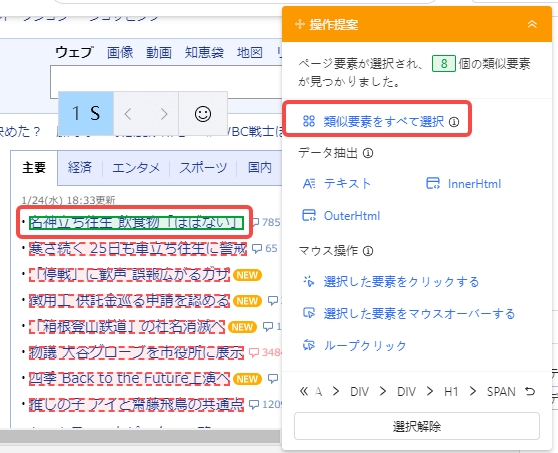
1.Octoparseの画面上にて、抽出したいテキストをクリックします。選択された領域は緑色で表示されます。
2.別の行のテキストを続けて選択することで、同じWebページ上の全ての類似要素を選択することができます。
3.ポップアップメニューより、「テキスト」をクリックします。
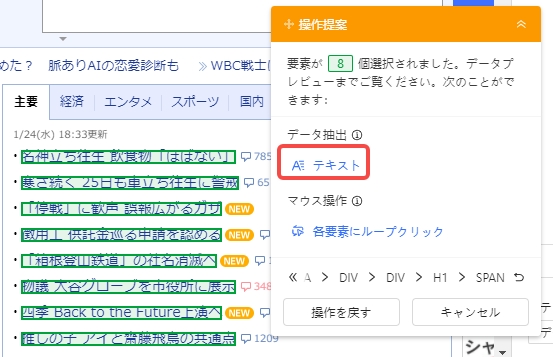
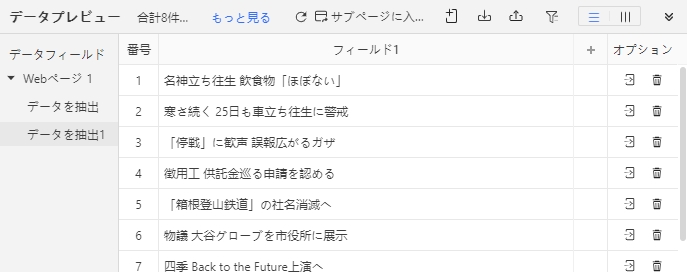
4.画面下部に選択箇所のテキスト情報が表示されます。
【URLの抽出】
1.Octoparseの画面上にて、抽出したいテキストリンクや画像をクリックします。選択された領域は緑色で表示されます。
2.別の行のリンクを続けて選択することで、同じWebページ上の全ての類似要素を選択することができます。
3.ポップアップメニューより、「リンク」をクリックします。
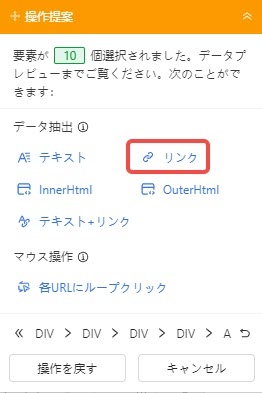
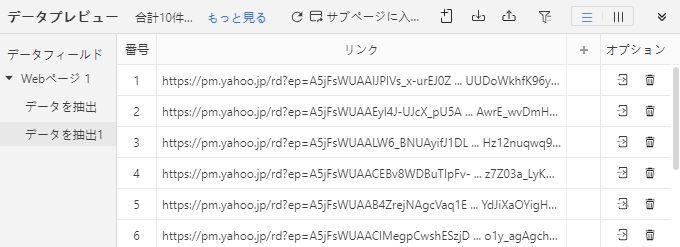
4.画面下部に選択箇所のリンク情報が表示されます。
まとめ
ということでこの記事ではPythonでHTMLからテキストやURLなどを取得する方法についてご紹介いたしました。人力でやろうとすると非常に大変ですが、Pythonによるプログラミングを使用することで、とっても簡単にWebページの情報を取得できることがお分かりいただけたかと思います!「プログラムは書きたくない!」という方でも、Octoparseなら誰でも簡単にWebページのデータが取得できるので、この機会にぜひ活用してみるのは如何でしょうか?




