株取引に欠かせない情報収取、皆さんはどうしていますか?今回は、誰でも簡単にYahoo!ファイナンスの株価情報をスクレイピングする方法をご紹介します。使用するのはWebスクレイピングツールの「Octoparse(オクトパス)」です。
まだOctoparseに登録していない方は、こちらのページからご登録ください。本当に簡単で、プログラミング未経験でも問題ないのでぜひ参考にしてみてください。
Octoparse(オクトパス)とは?ノーコードスクレイピングツール
まずは簡単に、Octoparseについてご紹介します。OctoparseはWeb上にあるさまざまな情報を自動的に取得する技術である、Webスクレイピングを実行するクラウドツールです。
通常、WebスクレイピングはPython(パイソン)などのプログラミング言語を使い、データを収集するプログラムを組む必要があります。しかしOctoparseならプログラムを組む必要はなく、データを取得したいサイトのURLを指定し、ボタンを数回クリックするだけで誰でも簡単にWebスクレイピングを実行できます。
そんなOctoparseを使って株価情報を収集すれば、データ分析にかかる時間を大幅に削減できます。なぜなら、データ分析で最も面倒かつ時間のかかる作業とは情報収集だからです。
また、情報収集のコスト削減にもなります。例えばYahoo!ファイナンスで株価情報を自動スクレイピングするには、有料のVIP倶楽部に入会しなければいけません。月額は2,000円以上なので、決して安くない金額です。
一方、Octoparseの無料プランならWebスクレイピング1回あたり最大1万レコードのデータを取得できます。株価情報を収集したい株主にとって、これほど便利なツールはないかもしれません。
Octoparseを使ってYahoo!ファイナンスの株価情報をスクレイピングする方法
それでは、株価情報をスクレイピングする方法をご紹介します。ちなみにOctoparse WebスクレイピングツールにはYahoo!ファイナンスの株価情報を自動取得するテンプレートが用意されています。ゼロからタスクを作る必要はないので、より簡単に株価情報をスクレイピングできるのが魅力です。
Octoparseを起動したら検索窓に「yahoo」と入力します。
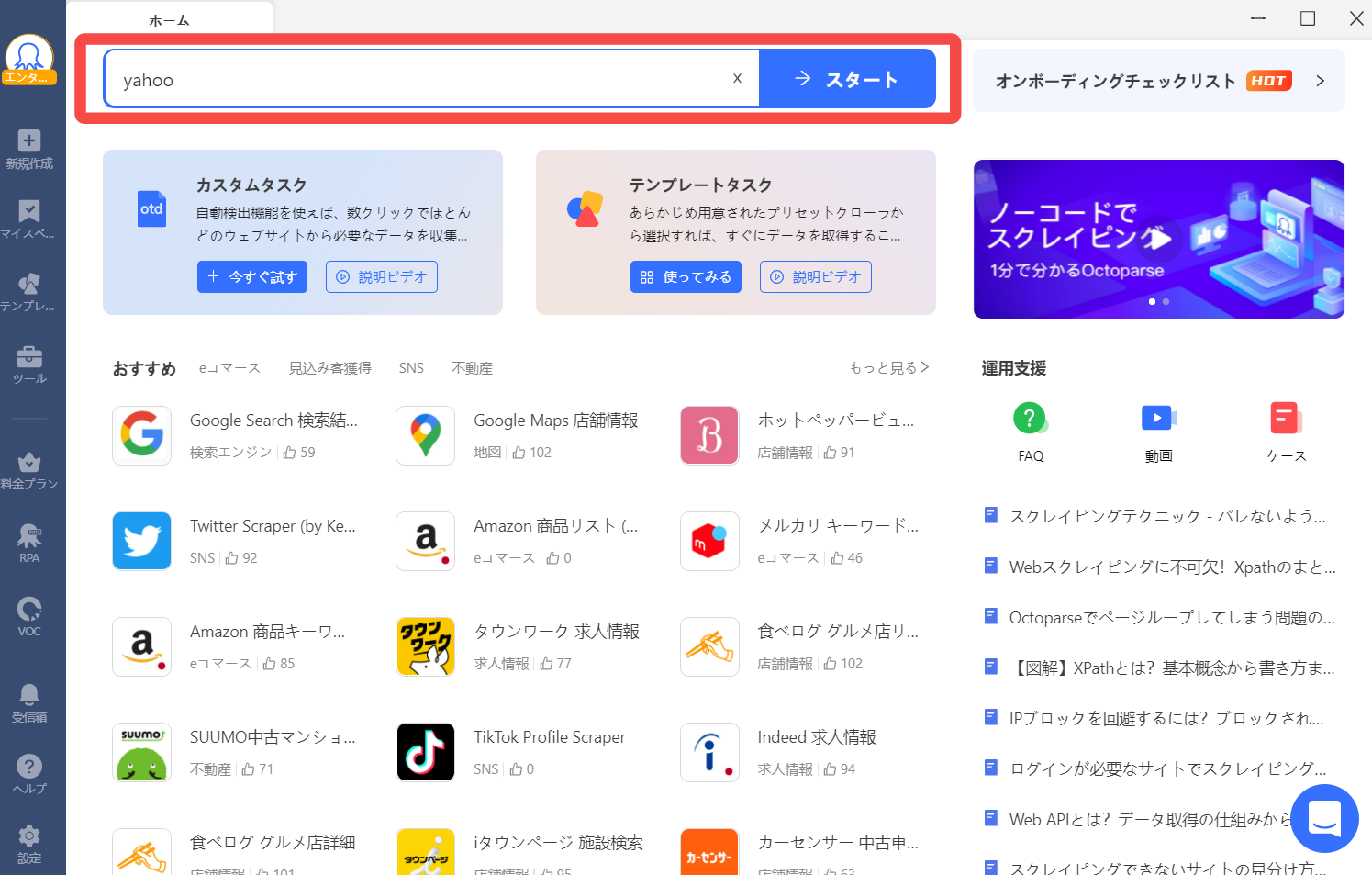
Yahoo!ファイナンス(海外版)のテンプレートタスクが表示されるので、テンプレートをクリックします。
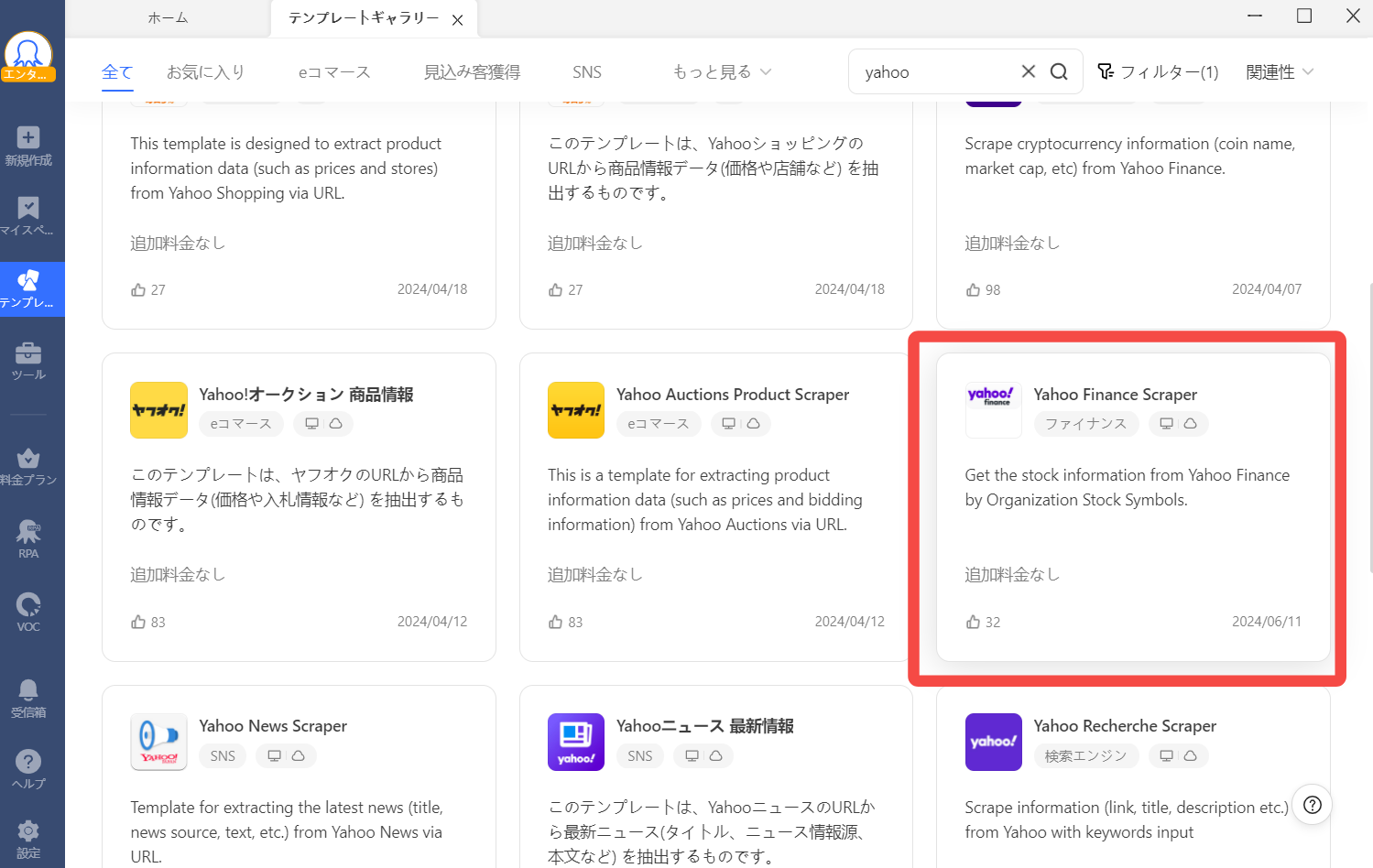
「パラメーター」の部分に、株価情報を収集したい銘柄のコード(4桁の数字)を入力します。ここで注意点があります。
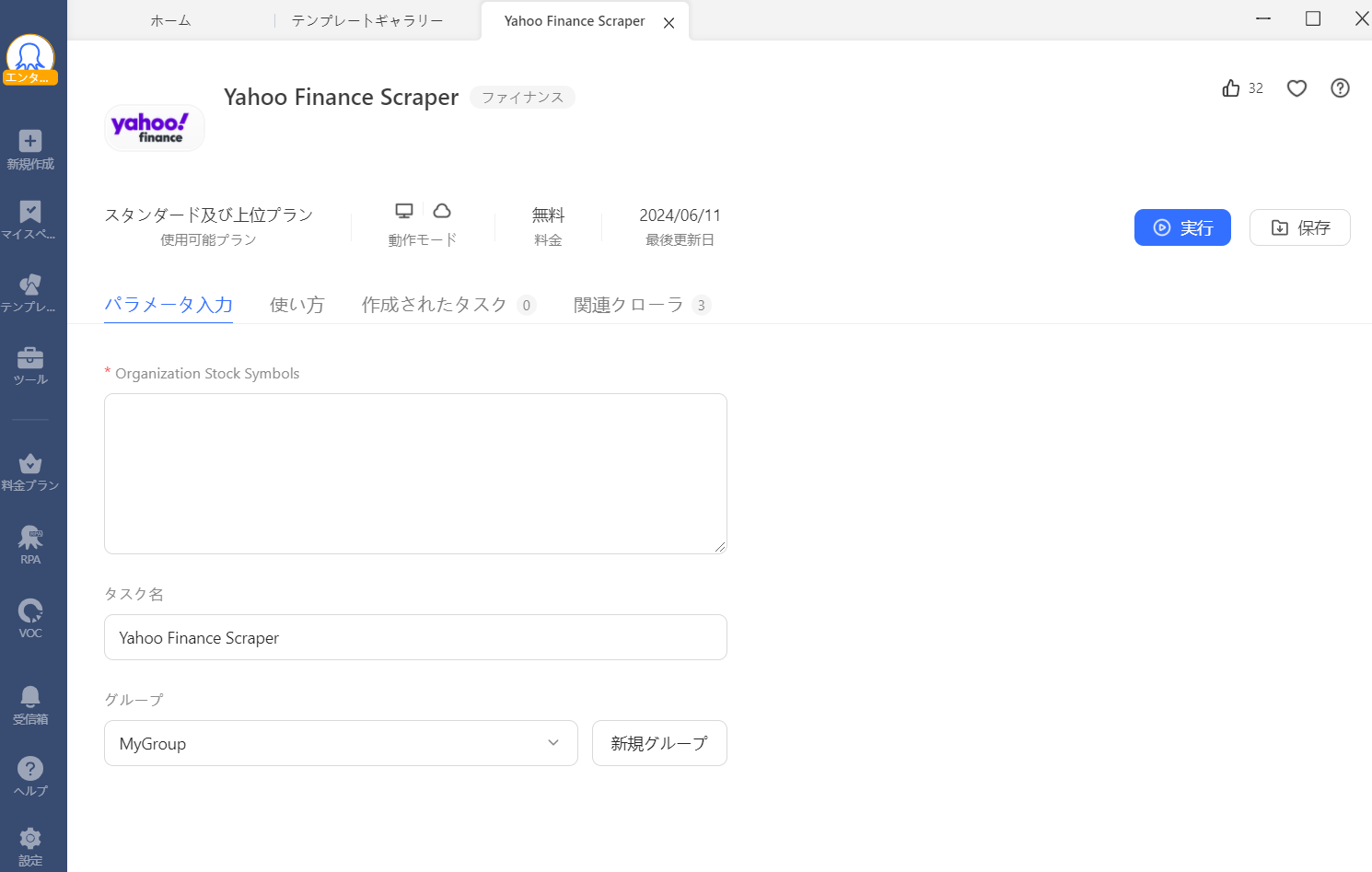
株価情報の収集元は海外版のYahoo!ファイナンスです。コードを数字だけで入力すると、それに該当する海外銘柄の株価情報を収集してしまいます。
そのため、各コードの末尾に「.T」を追加し、入力した銘柄コードが日本の株式市場を対象にしていることを示してください。今回は東証上場銘柄一覧ファイルを使い、コード番号が若い順に100銘柄の株価情報を収集します。
以下はGoogleスプレッドシートを使って銘柄コードの末尾に「.T」を一括追加する方法です(エクセルでも同じ操作で追加できます)。
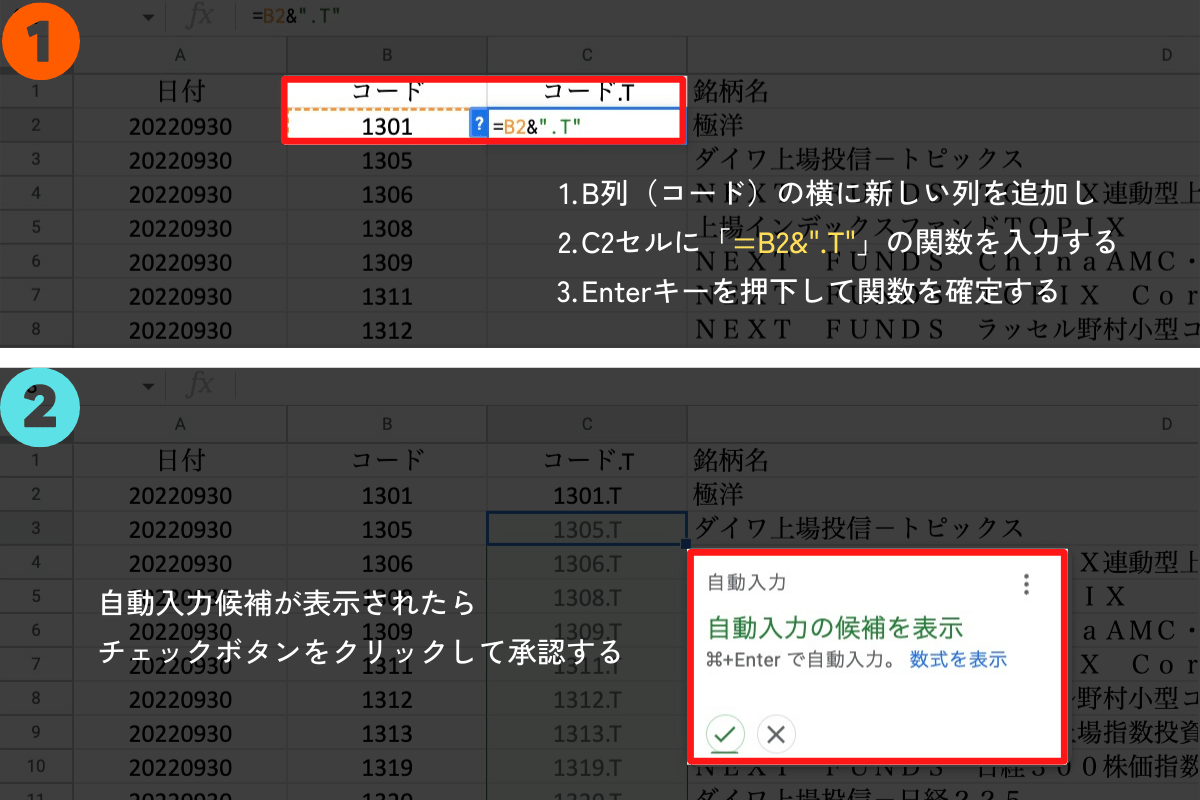
末尾に「.T」を追加した銘柄コードを用意したら、これをテンプレートタスクの「パラメーター」に貼り付けます。それぞれの銘柄コードが改行された状態でOKです。ここまで完了したら「保存して実行」をクリックします。
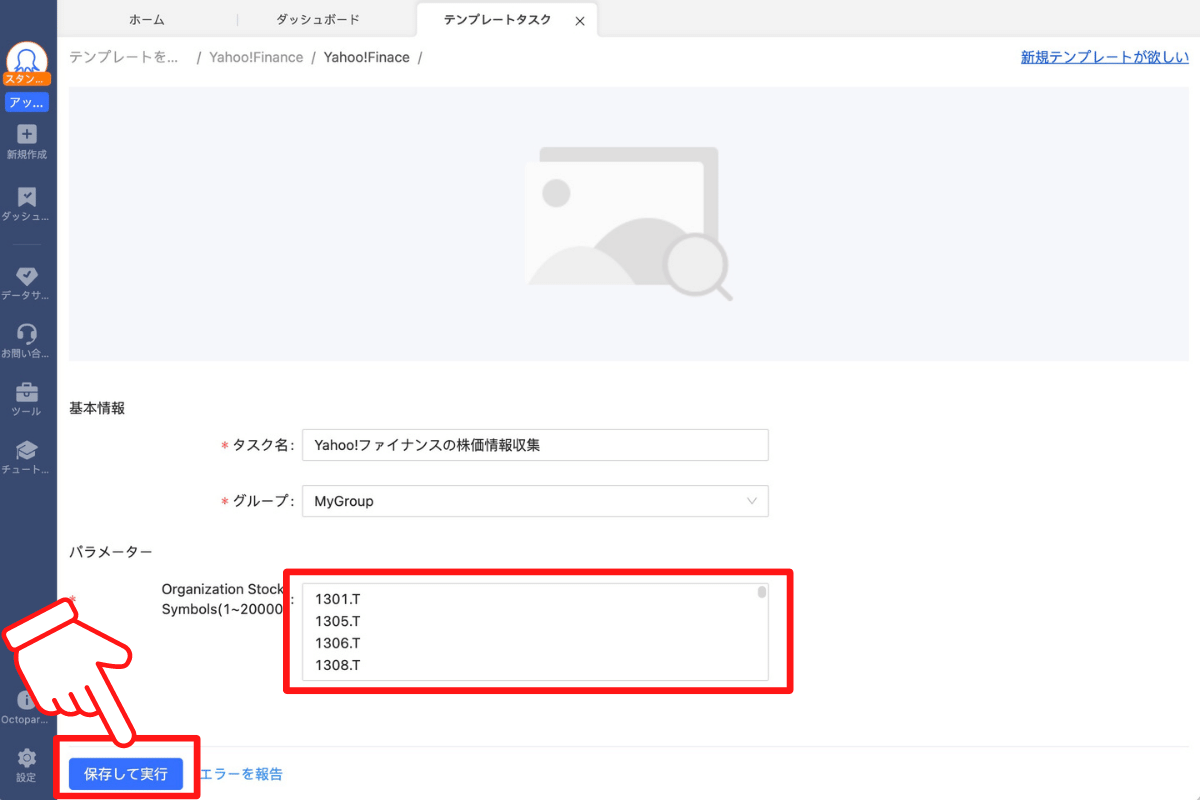
次に表示される画面では、タスクの実行方法を「ローカル抽出」または「クラウド抽出」から選択できます。データ量が多いため今回はクラウド抽出を選択しました。ちなみにクラウド抽出は有料プランの限定機能となります。無料プランの場合はローカル抽出を選択してください。
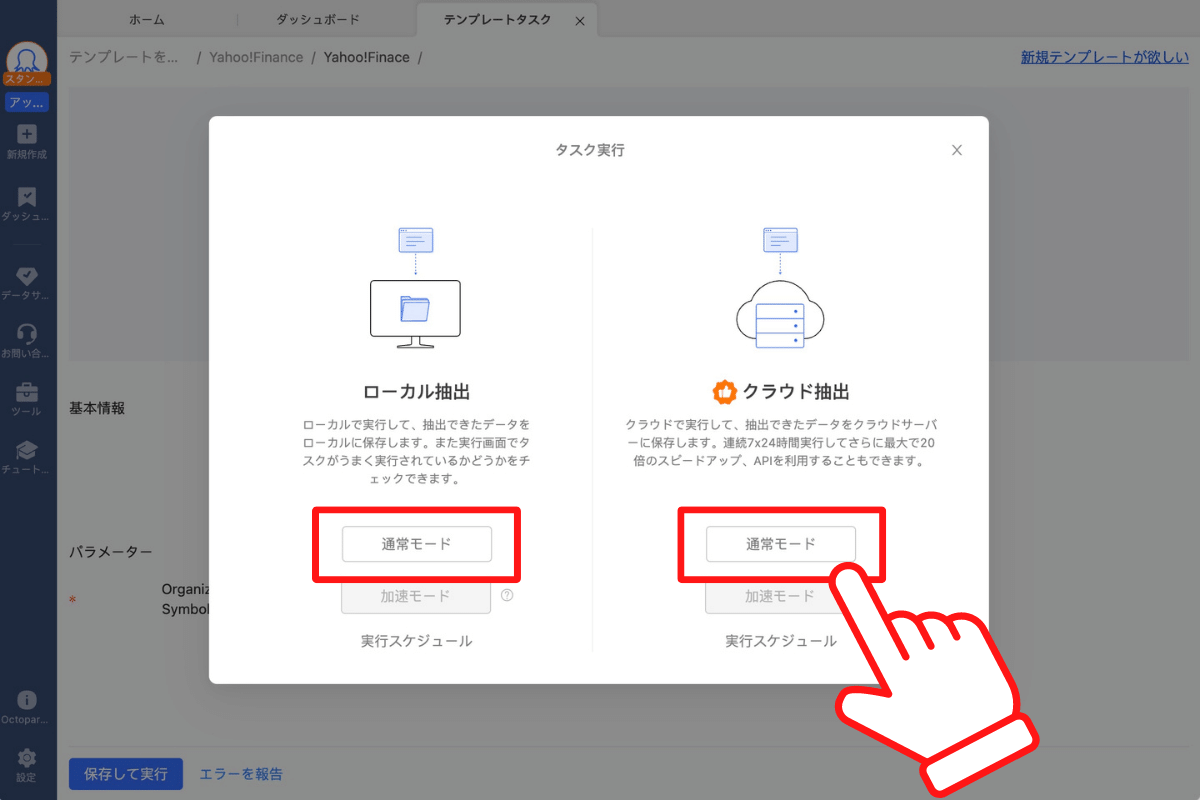
これでYahoo!ファイナンスから株価情報を収集するタスクが実行されました!あとはタスクが完了するのを待つだけです。実行画面ではタスクの実行状況を確認できます。
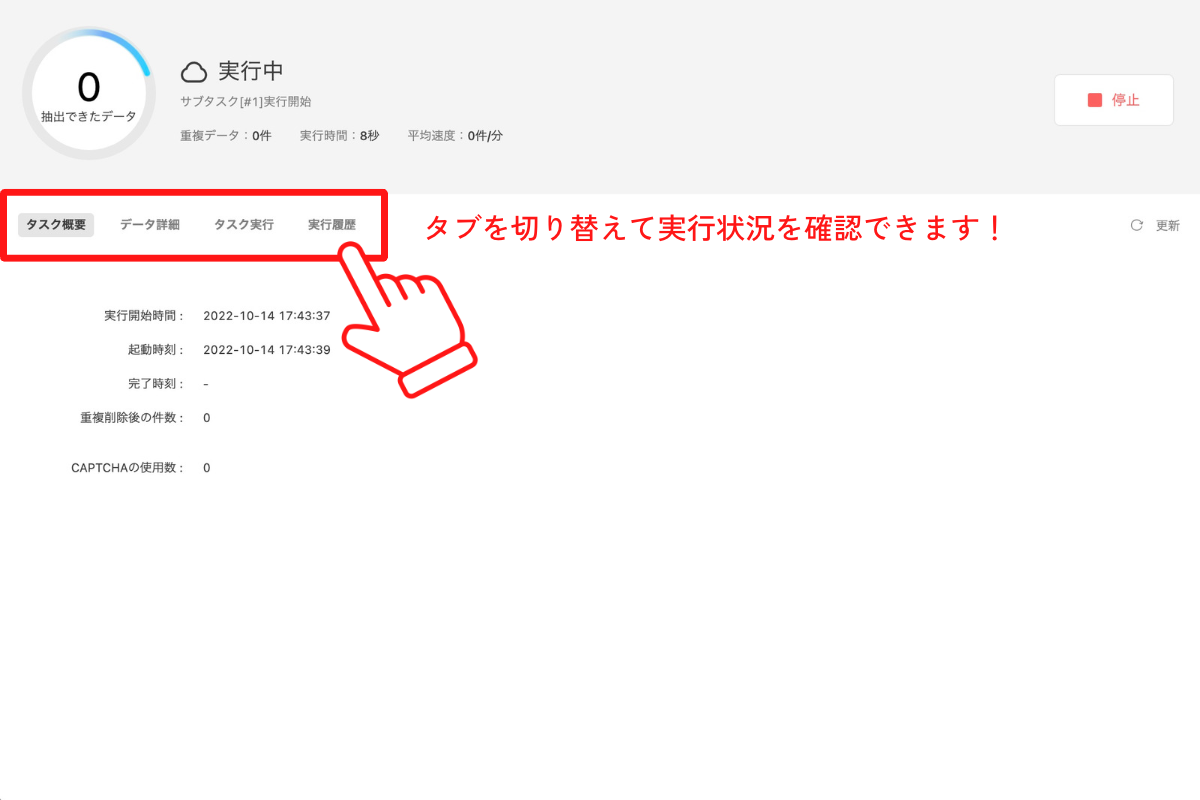
タスクの実行が完了したら、任意のフォーマットでデータをエクスポートしましょう!
Yahoo!ファイナンスの株価情報をPythonでスクレイピング方法
それでは、Octoparseを使ってYahoo!ファイナンスの株価情報をスクレイピングする方法がどれくらい便利で素晴らしいことかを実感していただくために、Pythonを使ったWebスクレイピングの方法をご紹介します。
ステップ1. BeautifulSoupライブラリをインストールする
pip install bs4
pip install requests
pip install pandas
ステップ2. モジュールをインストールする
#重要なモジュール
import requests
from bs4 import BeautifulSoup
import pandas as pd
ステップ3. WebページのURLを取得する
#レスポンシブURLを取得する
my_url = “https://finance.yahoo.com/news”
response = requests.get(my_url)
#例外処理
print(“response.ok :{},response.status_code: {}”.format(response.ok,response.status_code))
print(“Preview of response.text : “, response.text[:500])
ステップ4. WebページのHTMLデータを取得する
#WebページをダウンロードしてBSドキュメントを返すユーティリティ関数
def get_page(url):
response = requests.get(url)
if not response.ok:
print(‘Status code:’, response.status_code)
raise Exception(‘Failed to load page {}’.format(url))
page_content = response.text
doc = BeautifulSoup(page_content, ‘html.parser’)
return doc
#機能呼び出し
doc = get_page(my_url)
ステップ5. データを抽出して保存する
#必要な情報を抽出する
a_tags = doc.find_all(‘a’, {‘class’: “js-content-viewer”})
print(len(a_tags))
#出力(a_tags[1])
news_list = []
#トップ10のヘッドラインを出力
for i in range(1,len(a_tags)+1):
news = a_tags[i-1].text
news_list.append(news)
print(“Headline “+str(i)+ “:” + news)
news_df = pd.DataFrame(news_list)
news_df.to_csv(‘Market_News’)
以上のPythonコードは、Yahoo!からトップ10のニュースを取得するWebスクレイピングを実行できます。
といっても、プログラミング未経験の方には何をどうすればいいかわかりませんよね。しかも、上記のコマンドを実行する前にPythonの実行環境を整えなければいけません。
日々忙しい株主にとって、Webスクレイピングで株価情報を収集するためにPythonを学習する時間は、非常に効率の悪いことです。しかしOctoparseなら登録からわずか数十分~数時間で、数百・数千の株価情報を取得できます(取得する株価情報の量によって変動します)。
まとめ
Octoparseにはスケジュール設定機能があるため、決まった日時にタスクを自動的に実行できます。繰り返し設定も可能なので、定期的な情報収集にも向いています。これまで株価情報収集に苦労されていた方は、Octoparseによる高速な情報収集をぜひご体感ください。




