「Webスクレイピングを使って、大量の情報をまとめて取得したい!でも、プログラミングは難しそう…」そんな悩みを抱えたことはありませんか?
Webスクレイピングにはさまざまな方法があり、目的やスキルに応じた選択が重要です。プログラムを自作する方法もあれば、専用ツールを活用する方法もあります。また、使用するプログラミング言語やフレームワークによって、実装の難易度や機能性が変わるため、自分に合った方法を選択する必要があります。
今回は、その中でも比較的一般的かつプログラミング初心者にも理解しやすい言語であるPythonを用いた実装方法と、Pythonの知識がなくても実践できる手法をあわせて紹介します。
Pythonとは?
Pythonは、初心者からプロのエンジニアも利用するプログラミング言語です。構文がシンプルで、読みやすく書きやすい言語といわれています。また、豊富なライブラリやフレームワークが用意されており、効率的にプログラミング可能です。Webスクレイピングにおいても例外ではなく、用途に応じたさまざまなライブラリが提供されています。
Webスクレイピングとは?
Webスクレイピングは、Webサイトから情報を自動的に収集する技術です。特定のWebページにアクセスし、必要なデータを抽出して保存するプロセスを効率化できます。これにより、大量のデータを手作業ではなくプログラムによって迅速に取得できるようになります。
PythonのWebスクレイピングで何ができるの?
Pythonを使用したWebスクレイピングを使えば、インターネット上の様々なデータの収集・解析が可能です。ここでは、Pythonを用いたスクレイピングの具体的な用途をいくつか紹介します。
1.株価情報を取得できる
投資家にとって、リアルタイムな株価情報の収集は欠かせない作業です。手作業で複数の証券会社のサイトやニュースサイトをチェックするのは非効率ですが、Webスクレイピングを活用すれば、特定の企業の株価や市場全体の動向を自動で取得・更新できます。
例えば、日経平均株価やS&P500のリアルタイムデータを定期的に取得し、エクセルやデータベースに保存することで、過去の推移を分析しやすくなります。また、特定の株価が一定の値を超えた際に通知を送る 仕組みを構築すれば、チャンスを逃さずに取引の判断が可能になります。
2.ニュース情報を取得できる
最新のニュース記事やトレンド情報を 自動で収集 することで、効率的に情報を把握できます。様々なニュースサイトから関連する記事を抽出し、情報の集約や分析が可能です。
例えば、取引先の最新ニュースや業界のトレンドなどを効率的に収集し、営業活動に利用できます。
3.スクレイピングデータを活用したアプリやシステムの開発
Webスクレイピングで取得したデータを基に、新しいアプリやシステム開発も可能です。例えば、不動産情報をスクレイピングし、エリアごとの価格相場を可視化するアプリを開発すれば、購入希望者や投資家の意思決定をサポートできます。他にも、音楽ライブやスポーツ観戦などのイベント情報を集約したアプリなど、スクレイピングを活用することで、新たなビジネス創出のチャンスが生まれます。
4.ECサイトから商品データを取得できる
ECサイトから商品の価格、評価、在庫状況などの情報を収集できます。このデータは、競合他社の価格戦略を分析するだけでなく、市場の需要予測や販売戦略の最適化にも活用可能です。例えば、在庫状況の推移を追うことで、特定の商品が品薄になった際の需要急増や、供給の偏りを予測することもできます。
5.SNSサイト上の情報を取得できる
SNSサイトからのデータをまとめて収集することも可能です。集めたデータを分析し、マーケティングや市場の動向チェックなどに利用できます。
例えば、SNS上のトレンドを追跡することで、新たな市場ニーズをいち早くキャッチし、競争力のある商品やサービスを開発するためのヒントを得ることが可能です。また、インフルエンサーマーケティングでは、影響力のあるアカウントの投稿内容や拡散力を分析し、効果的な広告戦略を立てることができます。
Webスクレイピングの流れ・手順は?
Webスクレイピングは、取得したいデータの定義、プログラムの開発、データの保存が基本的な流れです。
ここでは一般的な手順を紹介します。
- 目的の定義:まず、何を目的としてデータを収集するのかを明確にします。例えば、特定の商品の価格情報、特定のトピックに関するニュース記事など、収集したいデータの種類を決定します。
- 対象サイトの選定:収集したいデータが存在するWebサイトを選定します。サイトの構造を理解し、必要な情報がどこにあるかを確認します。
- データの取得:Pythonを使ってWebページにアクセスし、HTMLデータを取得します。Webスクレイピングでは、効率的なデータ収集のため、requests や BeautifulSoup などの専用ライブラリを活用します。
- データの抽出:取得したHTMLから必要なデータを抽出します。HTMLタグに基づいて、必要な情報をフィルタリングし、抽出します。
- データの整形:抽出したデータはそのままではノイズが含まれることが多いため、不要なHTMLタグを削除し、適切な形式に変換する必要があります。例えば、価格データなら「¥10,000」を「10000」に数値変換するなど、データのクリーニングを行います。
- データの保存:最後に、抽出・整形したデータをファイル(CSV、JSONなど)に保存します。他にも、データベースに保存してアプリケーションやシステムとして再利用することも可能です。
PythonでWebスクレイピングするのによく利用されるライブラリ
PythonでWebスクレイピングを行う際には、Webスクレイピング用のライブラリが利用されます。今回は、その中でもよく利用される5つのライブラリを紹介します。
ライブラリとは?
ライブラリとは、特定の機能を提供するためのコードの集まりです。Webスクレイピングに特化したライブラリは、HTMLの取得、解析、データの抽出などを簡単に実装できるように設計されています。
以下は、今回紹介する5つのライブラリの比較表です。比較表の次に、各ライブラリの特徴を簡単に紹介します。
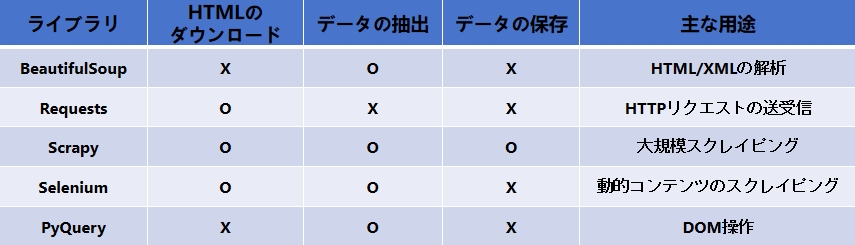
1. BeautifulSoup
BeautifulSoupは、HTMLとXMLの解析に特化したライブラリです。シンプルで分かりやすい構文を提供しており、初心者でも扱いやすいのが特徴です。主に、取得したHTMLを解析し、特定のタグの内容を抽出する際に使用されます。
2. Requests
Requestsライブラリは、PythonでHTTPリクエストを簡単に扱うためのツールです。このライブラリを使用すると、Webサーバーに対してGETやPOSTなどのリクエストを送信し、そのレスポンスを取得できます。主にWebページの内容を取得する際に使用されます。
3. Scrapy
Scrapyは、より高度なWebスクレイピングとクローリングに特化したフレームワークです。大規模なスクレイピングに適しており、データの取得、処理、保存までを一貫して管理できます。非同期処理により高速に動作し、複数のページから同時にデータを取得できます。ただし、高度な機能を備えている分、初心者にはやや扱いが難しい点もあります。
4. Selenium
Seleniumは、Webブラウザ操作の自動化に使用されるツールです。特に、JavaScriptで動的に生成されるコンテンツを含むWebサイトのスクレイピングに適しています。ブラウザを自動操作し、ユーザーのアクションを模倣してページの内容を取得が可能です。
5. PyQuery
PyQueryは、jQueryのような文法でHTMLを操作できるライブラリです。直感的で使いやすいインターフェースを提供し、DOM要素の選択や操作を簡単に行うことができます。このライブラリは、WebページのDOM構造を扱う際に特に便利です。
※ DOM(Document Object Model)構造とは、WebページのHTMLをツリー状に表現したもので、各タグの階層関係を明確にしたものです。
【サンプルコード】Webスクレイピングの実施
ここからは、それぞれのライブラリを利用して実際にコンテンツを取得する方法をサンプルコードとともに紹介します。今回は、サンプル用のサイトとしてhttps://example.com/からコンテンツを取得してみます。
RequestsでHTMLを取得する方法
まず、Requestsを利用してHTMLを取得する方法です。HTMLを取得するのみであれば、以下のサンプルコードのようにrequests.get()にコンテンツを取得したいサイトのURLを渡します。
本コードを実行することで、対象WebサイトのHTMLを取得できます。
BeautifulSoupでスクレイピングする方法
次に、BeautifulSoupの利用方法です。BeautifulSoupはデータの解析が主な機能であるため、Requestsライブラリを使って取得したHTMLを分解して、必要な要素だけ取り出すことができます。以下のサンプルコードを実行すると、指定したサイトのタイトルを取得します。
Scrapyでスクレイピングする方法
Scrapyでのスクレイピングは、スパイダーと呼ばれる特別なクラスを作成します。このスパイダーで、スクレイプをしたいサイトを指定した後に必要な要素を取り出します。指定したサイトからタイトルを抽出する場合のサンプルコードは以下のとおりです。
Seleniumでスクレイピングする方法
Seleniumは、プログラムからWebブラウザを自動で操作できるライブラリです。
プログラムを実行すると、実際にブラウザが起動してデータの収集を行います。そのため、プログラムを実行する端末にブラウザ(Chromeなど)をインストールしておく必要があります。
以下はhttps://example.comのタイトルを取得する場合のサンプルコードです。今回は’title’というタグの名前を指定していますが、クラス名やID名など複数の方法でエレメントを指定することができます。
PyQueryでスクレイピングする方法
最後に、PyQueryを利用したスクレイピングのサンプルコードです。PyQueryはライブラリ単体でサイトへアクセスし、HTML取得と分析を実施することができます。以下のサンプルコードではhttps://example.comのタイトル部分を取得して表示しています。
Python知識なしでWebスクレイピングする方法【簡単!】
ここまで、Pythonを使ってスクレイピングする方法を紹介してきました。しかし、技術の進歩により、現在ではPythonの知識がなくてもWebスクレイピングを実行できるサービスが数多く提供されています。ここでは、初心者や非エンジニアでも簡単にスクレイピングを実装できるツール「Octoparse」を紹介します。
Octoparse Webスクレイピングツールを利用する
Octoparseは、プログラミング知識がなくても使えるWebスクレイピングツールです。直感的なインターフェースを備えており、クリック操作だけで簡単にデータの取得・抽出が可能です。また、自動検出機能を搭載しているため、指定したWebページの構造を解析し、
必要なデータを素早く抽出できます。
最後に、Octoparseを使ったスクレイピング方法をご紹介します。
スクレイピング手順:
今回は、Octoparseのブログ記事(https://www.octoparse.jp/blog)のタイトルを取得してみましょう。
操作手順:
1. インストールしたOctoparseを起動します。

2. 左側のメニューバーから、新規タスクを作成します。
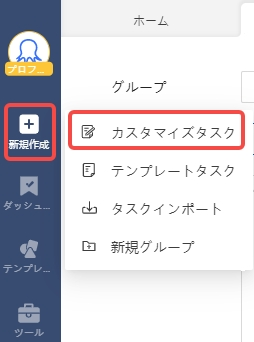
3. 収集したいWebページのURLを入力します。
今回は、「https://www.octoparse.jp/blog」と入力し、保存します。
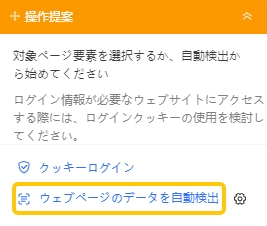
4.自動検出機能を使って、Web上のデータを自動的に検出します。
5. 自動検出結果を確認し、期待していた情報が取得できているか確認します。
今回のページでは、キーワード・URL・タイトル・著者名・詳細・更新日などが取得できています。
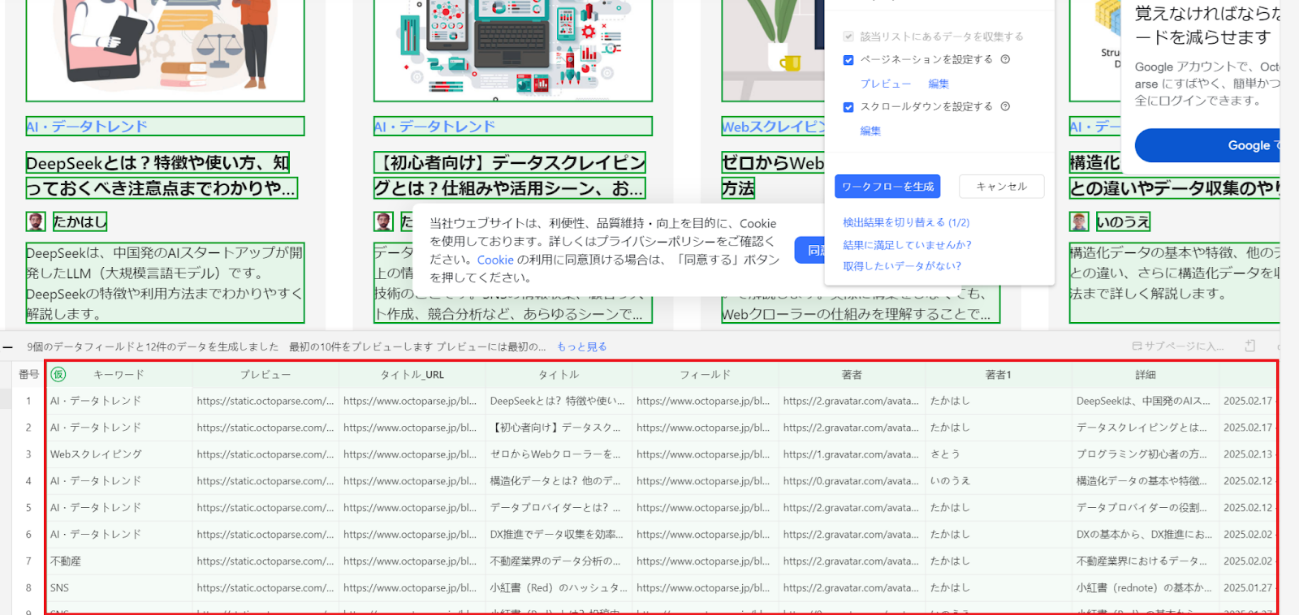
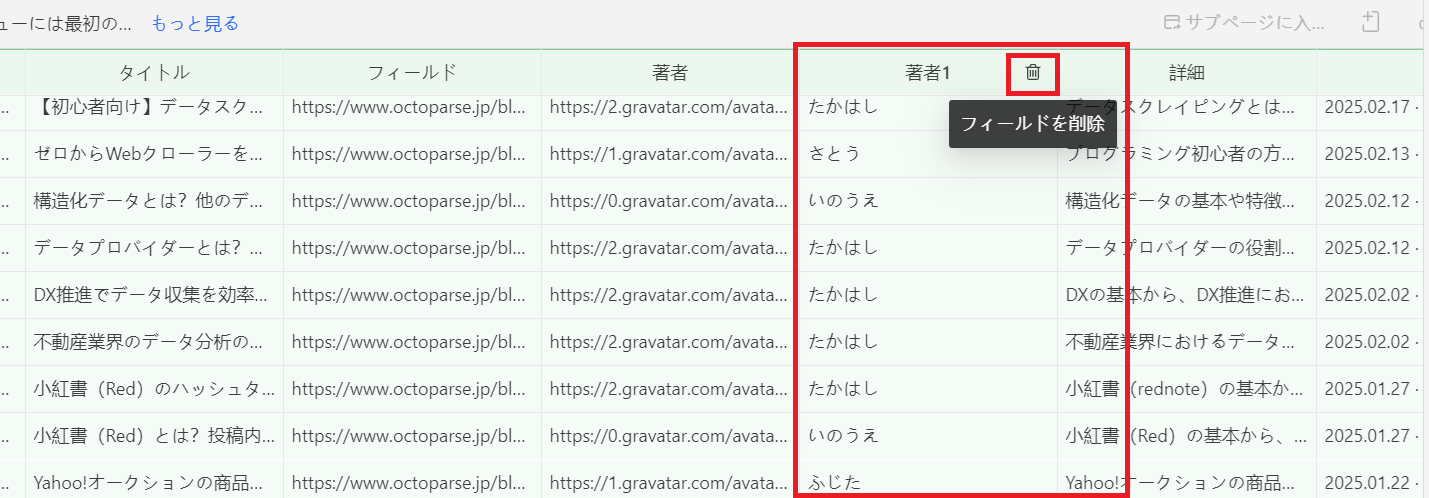
6. 抽出されたデータを確認し、必要に応じて調整します。
不要なデータがある場合は「フィールドを削除」することで除去できます。
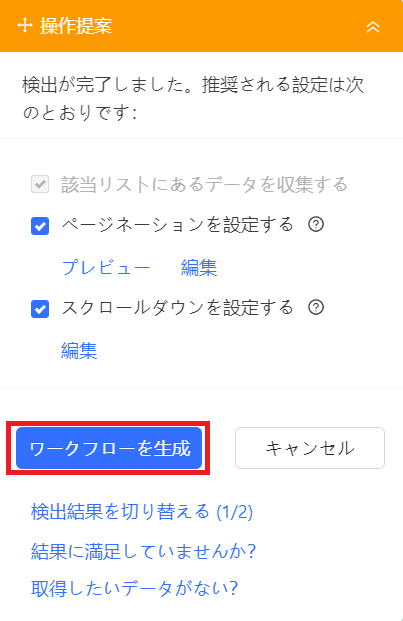
7. データの調整完了後、「ワークフローを生成」をクリックします。
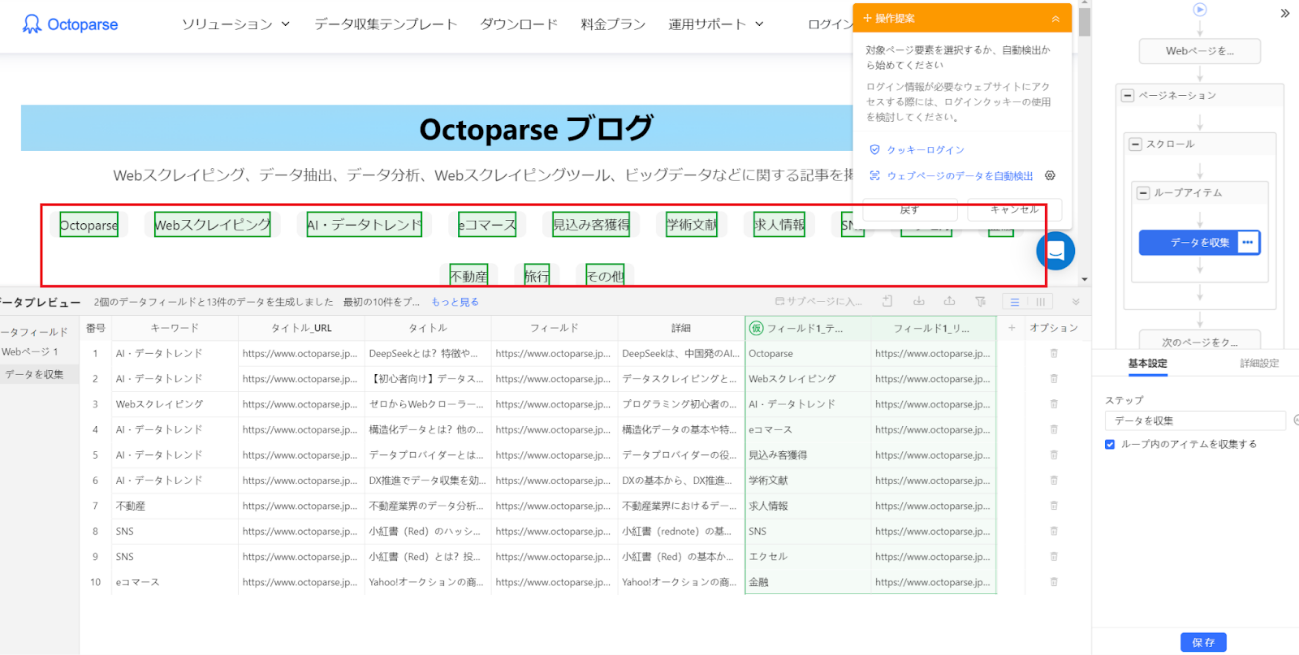
8. 自動検出で取得しきれなかったデータは、手動で設定が可能です。
9. 最終調整が完了したら、右上の「実行」をクリックします。
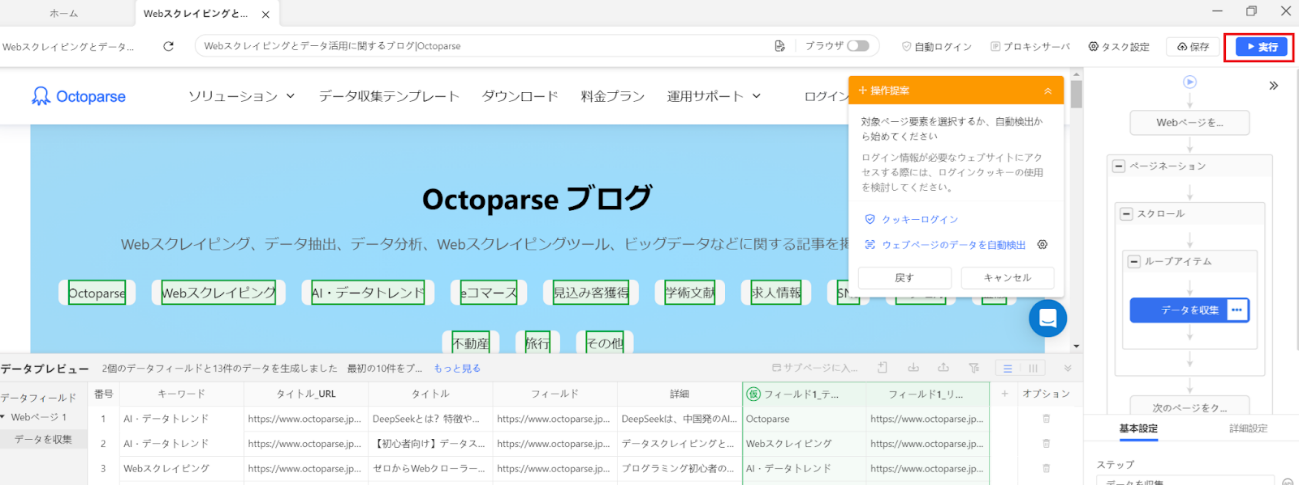
10. ローカル・クラウド抽出が選択できます。
- ローカル抽出:自分のPCとIPアドレスを利用してスクレイピングを実施します。スクレイピング中はPCの停止ができません。また、スクレイピング中はPCに負荷が掛かる場合があります。
- クラウド抽出:Octoparseのサーバーを利用してスクレイピングを実施します。自分のPCを使用しないため、PCを停止しても処理が止まることはありません。
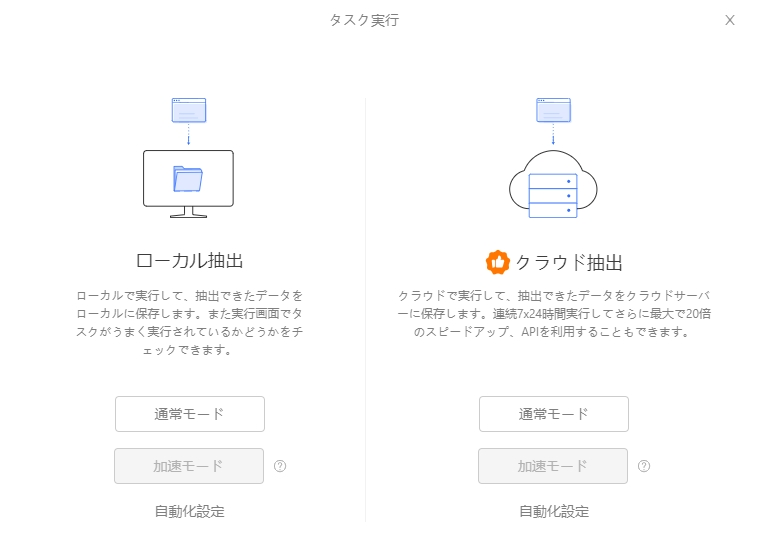
11. 抽出したデータをCSV、Excel、または他のフォーマットでエクスポートします。
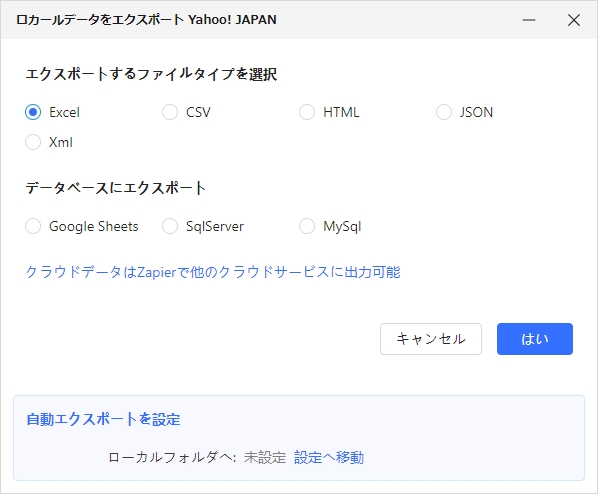
12. Excelで取得できたデータがこちらです。
Webページの1ページ目だけでなく、最後のページまで取得ができています。

今回の手順では、わずか10〜15クリックで280記事以上の記事タイトルの取得ができました。
また、このワークフローを保存しておけば、再実行により差分の記事(最新記事)のみを追加で取得することも可能です。
Pythonでスクレイピングを実装するよりも、手軽・効率的にデータを取得できることが分かると思います。
まとめ
Webスクレイピングは、必要な情報収集を高速で実施できる優れた機能ですが、Pythonなどのプログラミング言語の知識がなければ難しいと感じることもあります。しかし、Octoparseのようなコーディング不要なスクレイピングツールを使用することで、誰でも簡単に高品質なデータを収集することが可能になります。プログラミング知識がないけれど、Webスクレイピングを試してみたい、実装してみたい場合は、Octoparseのようなツールを利用して、効率的なWebスクレイピングを手軽に実現してみてはいかがでしょうか。




