以前Twitter(The X)で、競馬に関するあるツイートが話題になりました。それは自作AIに有馬記念を予想させたところ、118万2500円が的中したという内容です。

競馬予想には様々な方法がありますが、AIによる競馬予想は2019年頃から登場し始めました。AIロボットは、過去の膨大なデータに基づいた統計解析によってレース結果を予測しています。
そのため、競馬の統計解析を行うためには、解析するためのデータ群が必要不可欠ということです。統計解析のデータを効率的に集めるために役立つ技術が「Webスクレイピング」です。今回はWebスクレイピングで競馬データの収集方法を紹介します。
スクレイピングとは
Webスクレイピングとは、Webサイトから特定のデータを自動で抽出するコンピュータソフトウェア技術のことです。Webスクレイピングを使えば、インターネット上に存在するWebサイトやデータベースを探り、大量のデータの中から特定のデータのみ抽出できます。
そのため、従来のようにリスト作成のためにWebページから手作業によるコピー&ペーストを行う必要は一切ありません。面倒な手作業を自動化することで、作業時間の大幅な短縮はもちろん、転記ミスなどの防止にもつながります。
24時間抽出してくれるので、自分が寝ている時や他のことをやっている時に休まずデータを抽出し続けてくれます。人間と違って疲れ知らずなので、スピード・正確性を保ち続けます。
抽出したデータはExcelやcsvファイルなどにエクスポートできるため、それらのデータをもとに統計解析などに利用できます。Webスクレイピングについて詳しく知りたい方はこちらの記事もご覧ください。
競馬データをスクレイピングする方法
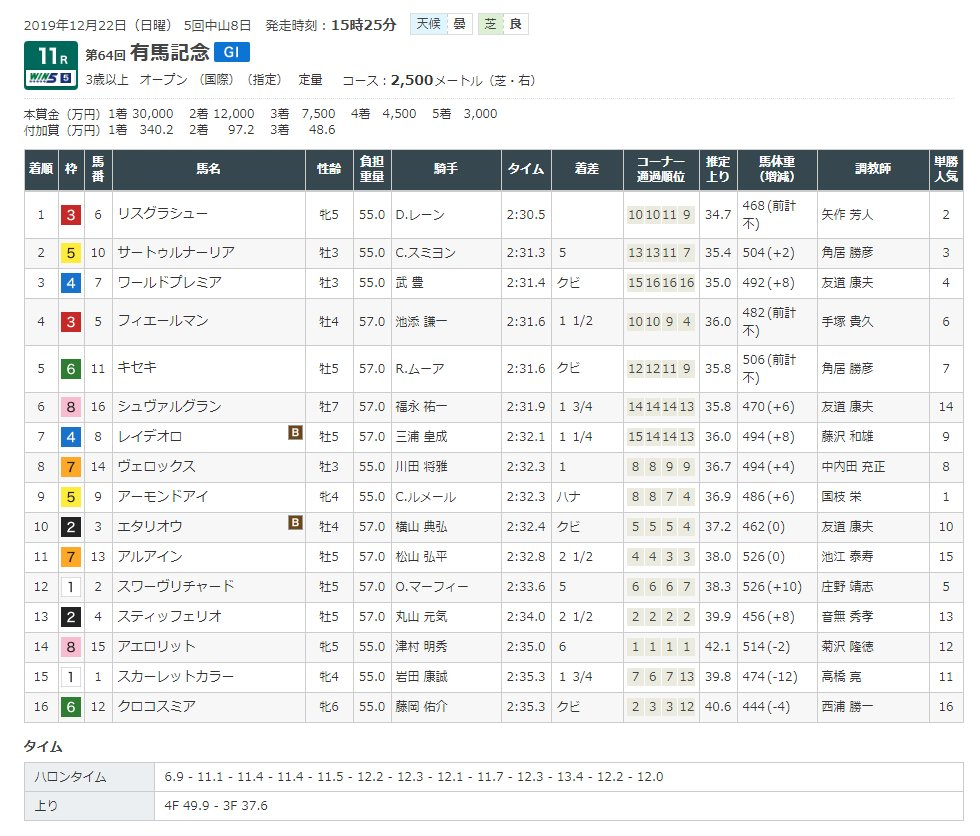
今回はJRA公式サイトのデータソースをスクレイピングします。JRA公式サイトでは、有馬記念はもちろん、過去の様々なレースの成績データを見ることができます。
Octoparseで競馬データをスクレイピングする【Python知識なし】
JRA公式サイトのデータを取得するには、WebスクレイピングツールのOctoparse(オクトパス)を使います。Octoparseは、Python知識なしで誰でも簡単にウェブ上の競馬データをスクレイピングできます。さらに、スクレイピングした競馬レースの結果データをCSVなどの形式で保存できます。
Octoparseを使ったスクレイピングの手順は以下のとおりです。
スクレイピング手順
- 対象のWebページを設定する
- 取得する項目を設定する
- データ抽出を実行する
ここからは、早速2019年の有馬記念のデータを収集してみましょう!
ステップ1. 対象のWebページを設定する
Octoparseを起動して、ホーム画面の「新規作成>カスタマイズタスク」をクリックします。
新規タスクの画面が表示されたら、URL入力を「手動で入力」、URLプレビューの枠内に以下のURLを貼り付けます。
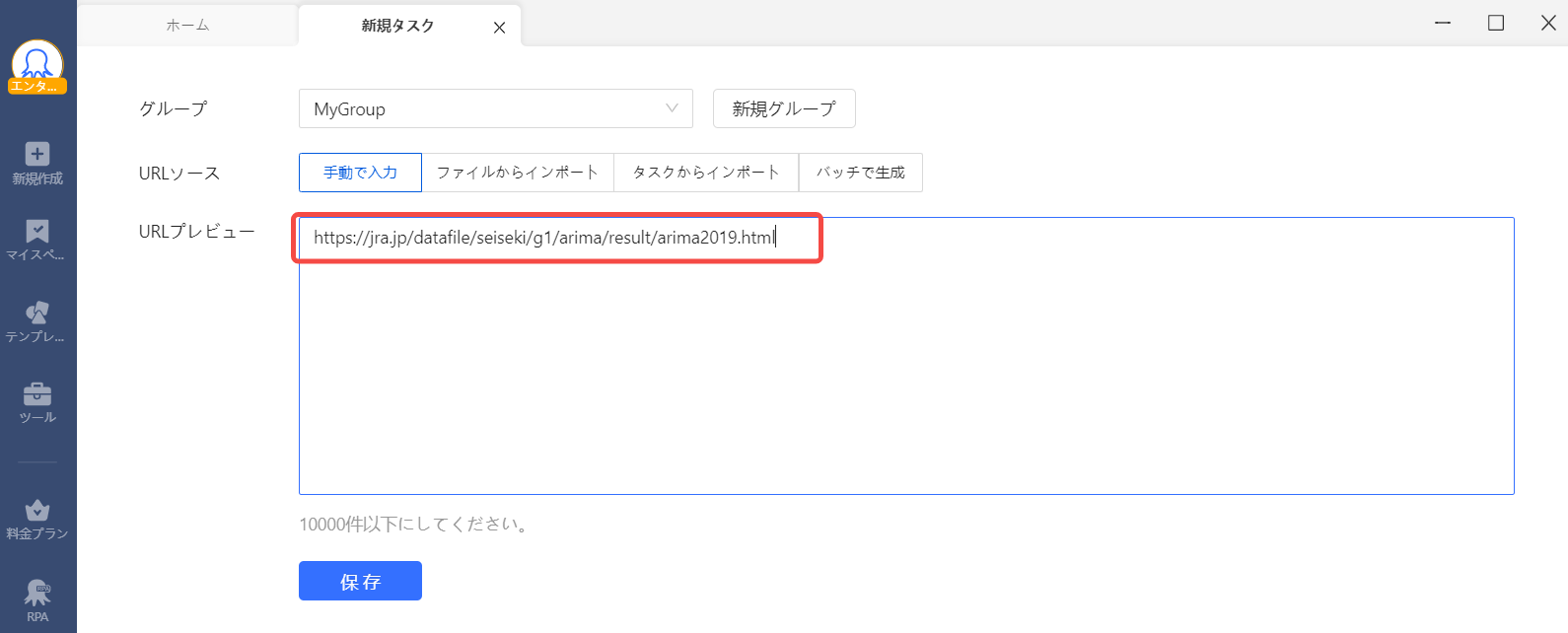
最後に「保存」をクリックします。
ステップ2. 取得する項目を設定する
今回は着順、馬名、騎手、調教師などテーブルにあるデータを全部取得します。
まず着順の「1」をクリックすると、選択されたことを示す緑色に変わります。残りの着順は赤色に変わり、類似した要素として識別されたことを示しています。
続いて、行毎のデータを一括で取得するには、「操作ヒント」から「選択範囲拡大」ボタンをクリックします。すると、一行目のデータが全選択されます。
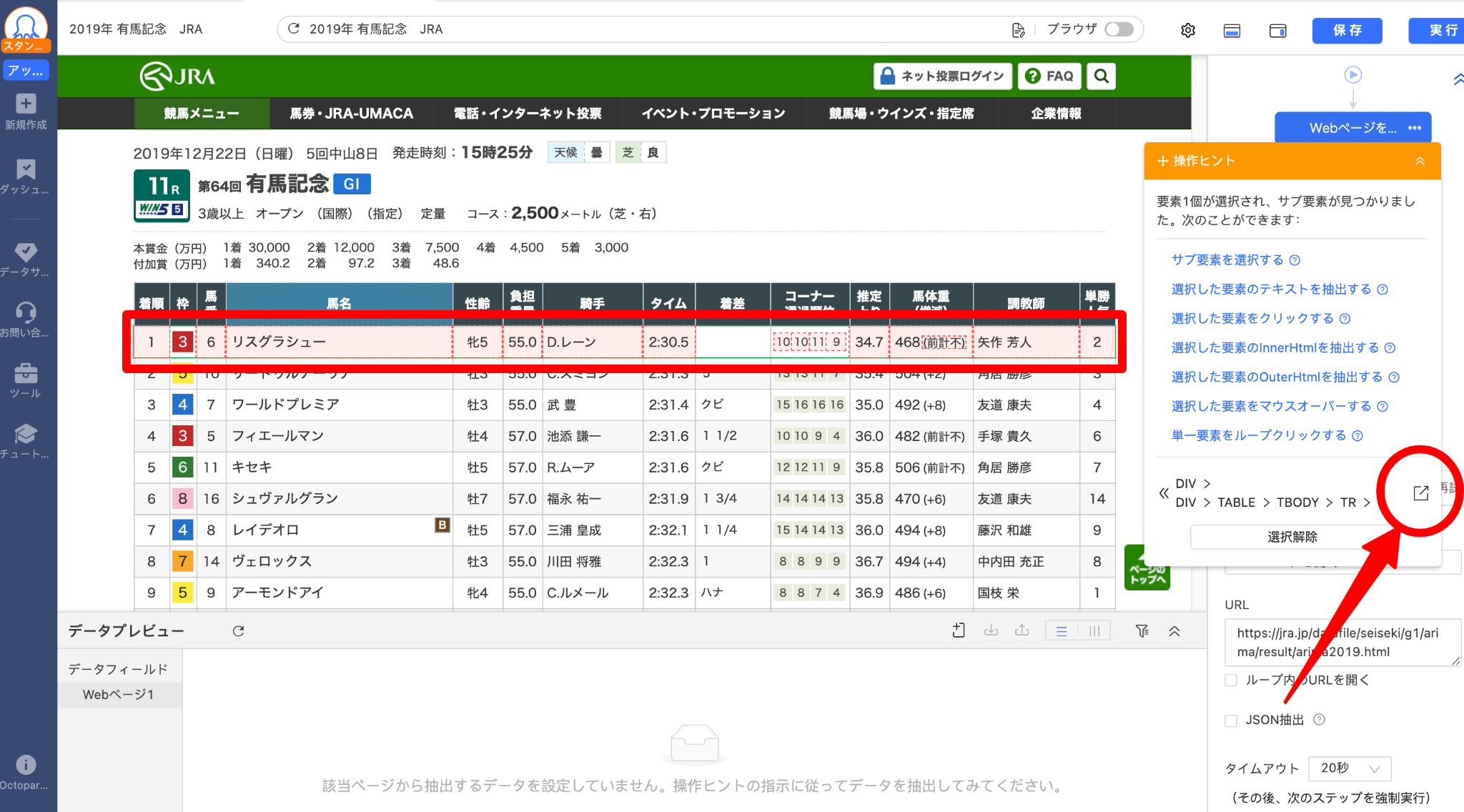
各行にあるデータを細かく取得するため、「操作ヒント」で「サブ要素を選択する」をクリックします。すると各行の要素がすべて選択されます。次に「すべて選択」>「データを抽出する」を順番にクリックすると、Octoparseが対象データを自動的に抽出します。
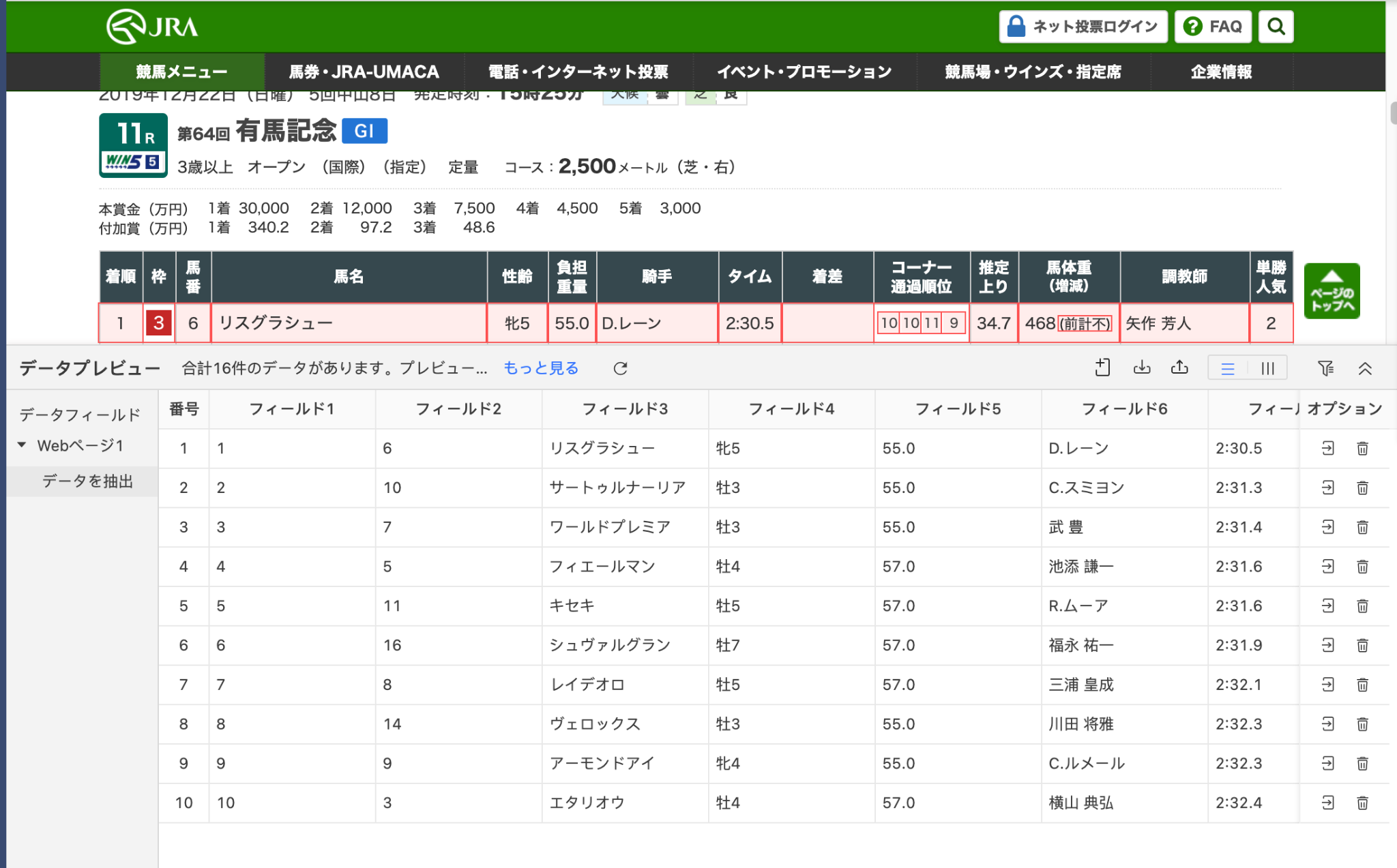
抽出したデータは、以下のようにデータプレビュー内に表示されます。データフィールドを編集し、フィールド名を変更したり、余計なデータを削除したりすることも可能です。
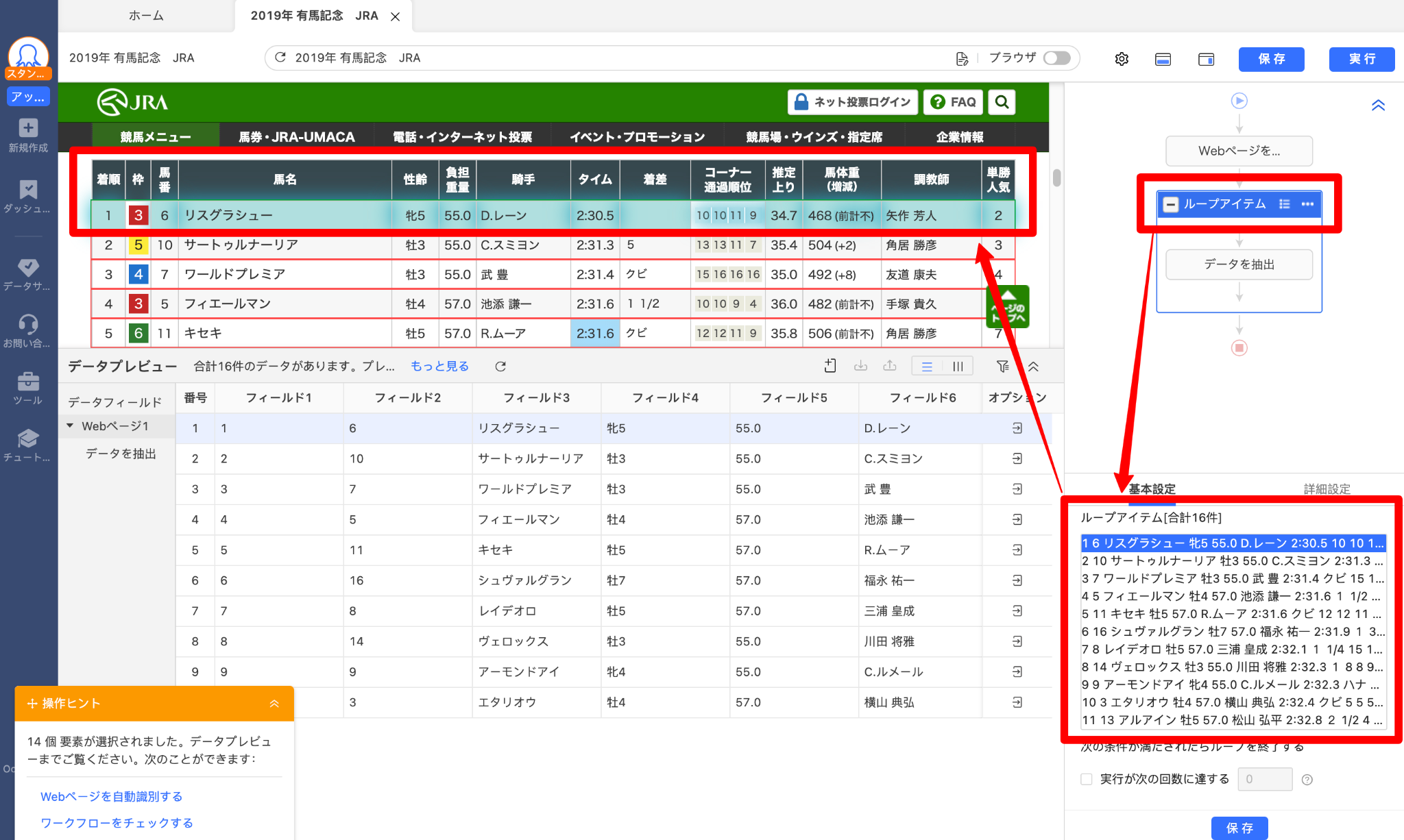
「ループアイテム」をクリックすると、各行のデータが正しく抽出されるかどうか確認できます。しかし、「枠」のデータが取得されません。その理由は、枠の数字が画像なのでデータとして抽出されないためです。
実は、枠の数字は画像のURLに隠されています。画像のURLを取得し、その中から数字を取得します。
一行目の画像URL:https://jra.jp/JRADB/img/waku/3.png
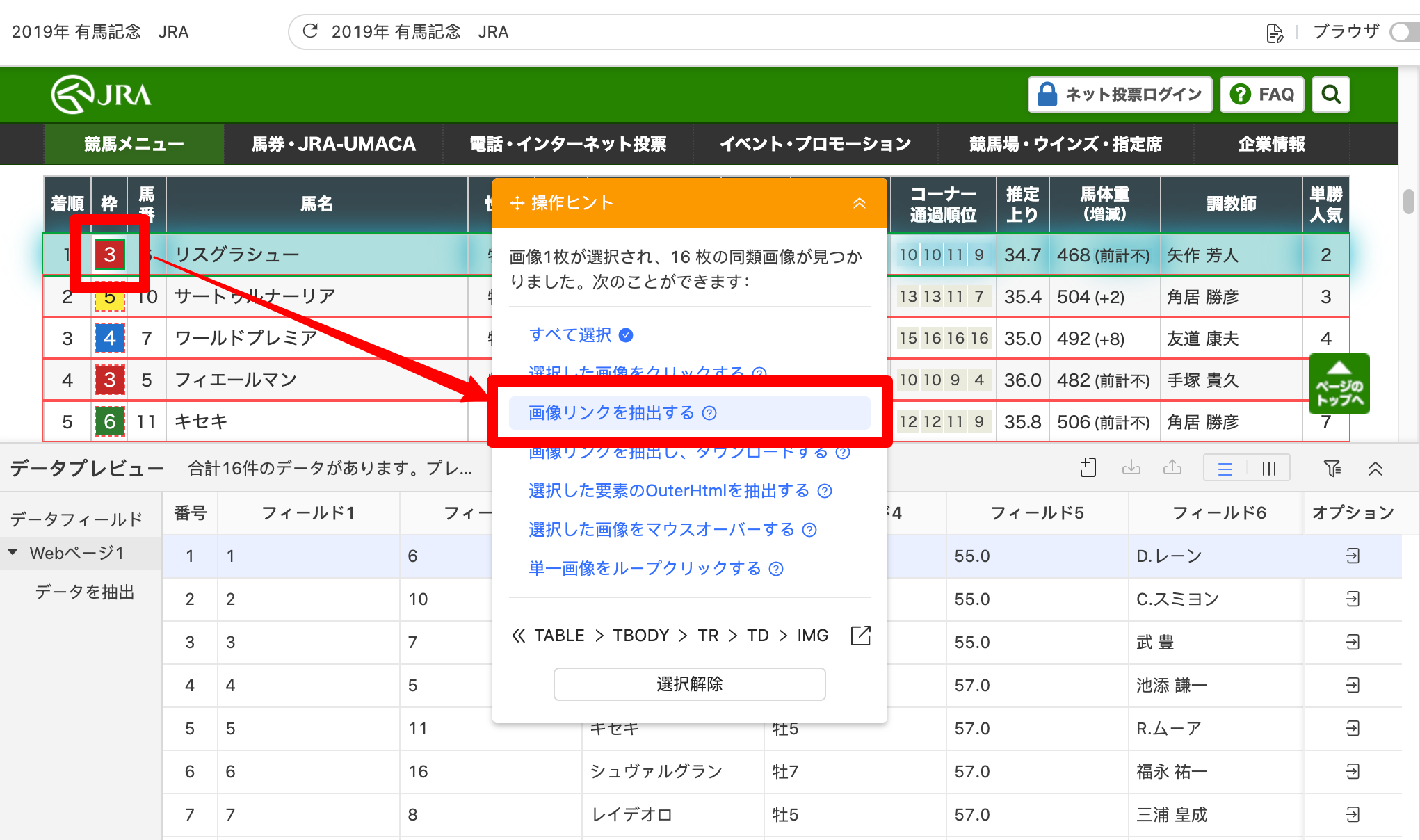
画像URLを取得する手順は、まず枠の画像をクリックします。続いて「操作ヒント>画像リンクを抽出する」をクリックすると、画像URLデータを取得できます。
抽出した画像URLから数字を取得するには、2つの方法があります。1つはExcelの「切り替える」機能です。もう1つはOctoparseのデータ再フォーマット機能です。どちらも簡単ですので、今回は説明を省略します。
ステップ3. データ抽出を実行する
これで、スクレイピングのワークフローが完成しました。ワークフローを保存し、「実行」をクリックします。
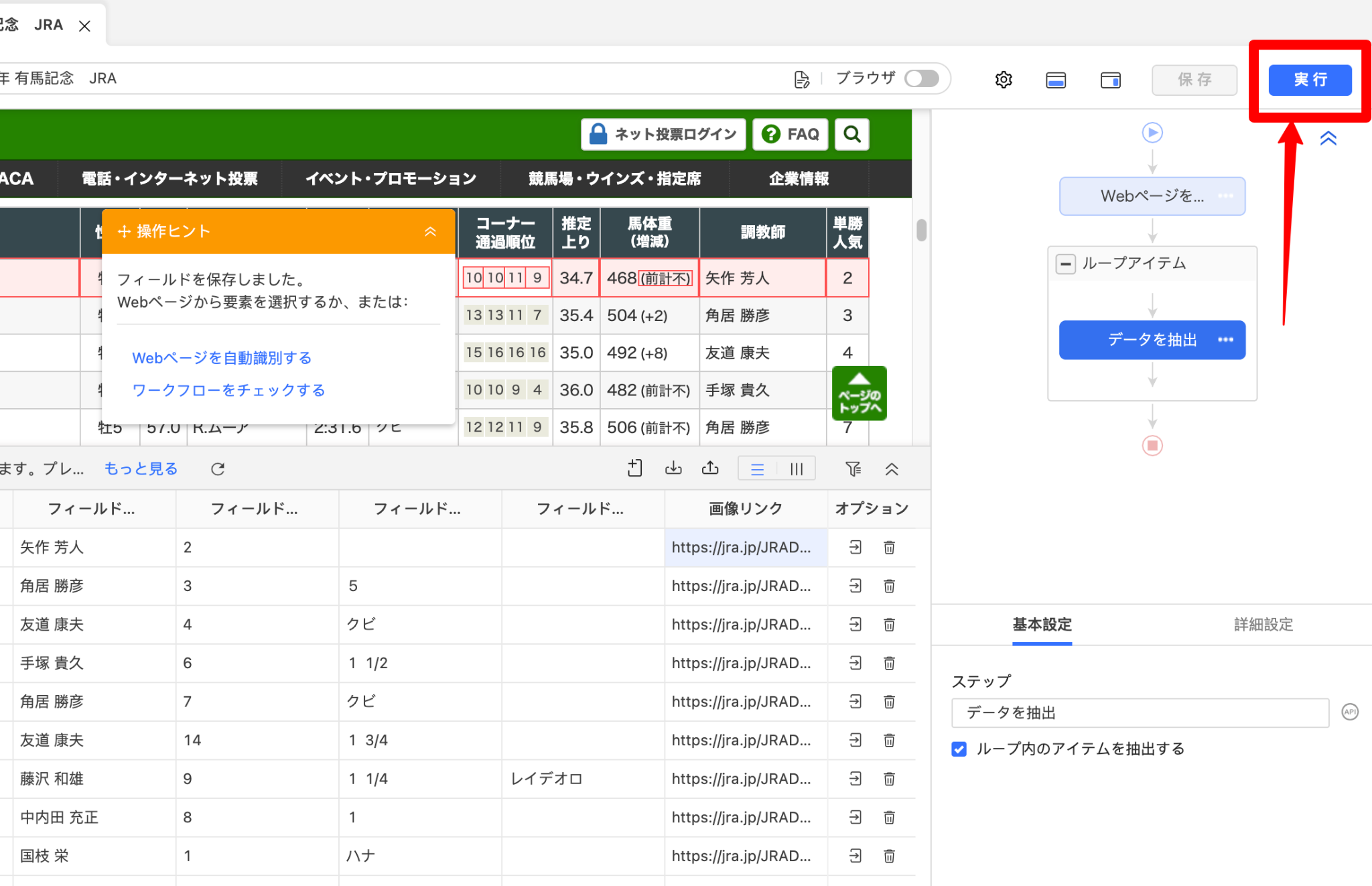
タスク実行で、ローカル抽出またはクラウド抽出のいずれかを選択すれば、あとは自動的にスクレイピングが開始します。
クラウド抽出は有料プランの契約が必要ですが、今回は16行分のデータとしかないため、ローカル抽出で十分でしょう。
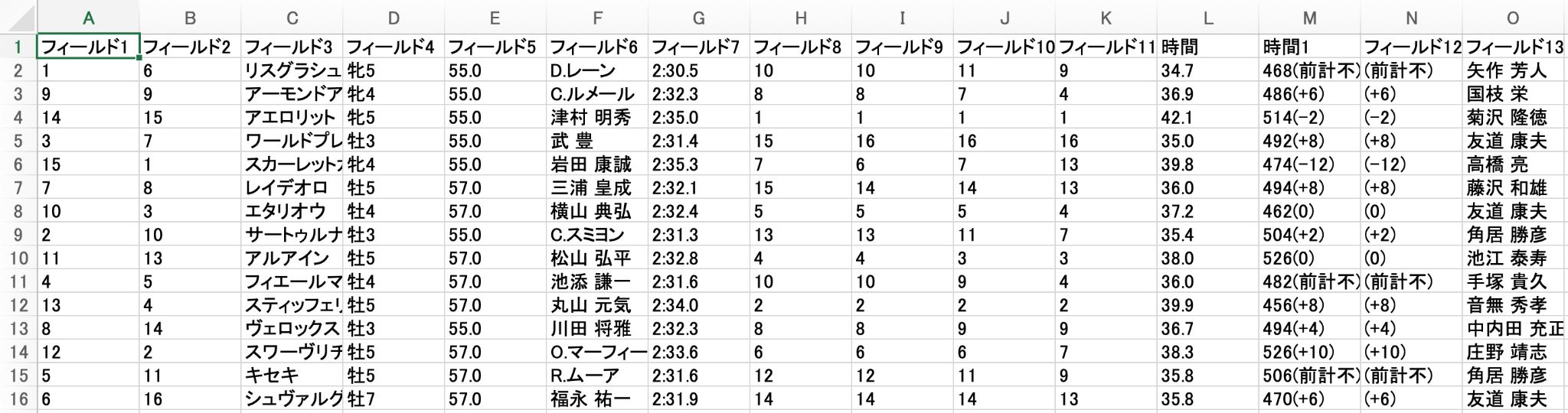
データをエクスポートすると以下のようにデータが抽出されています。エクスポートはExcel、CSV、HTML、JSON、その他データベースなどあらゆる形態に利用できます。
Pythonで競馬のデータをスクレイピングする
競馬のデータをスクレイピングするには、Pythonのいくつかのライブラリを使用することが一般的です。以下に、競馬のデータをスクレイピングするための基本的な手順を示します。
1.ライブラリをインストールする:
Pythonのrequestsライブラリを使用してウェブページのデータをダウンロードし、BeautifulSoupライブラリを使用してデータを解析します。これらのライブラリをインストールするには、次のコマンドを使用します。
2.ウェブページを取得する:
requestsライブラリを使用して競馬のデータが掲載されているウェブページのHTMLをダウンロードします。
3.データを解析する:
BeautifulSoupライブラリを使用してダウンロードしたHTMLデータを解析します。解析には、ウェブページのHTML構造を調査し、必要なデータが含まれている要素や属性を特定する必要があります。
4.データを抽出する:
BeautifulSoupを使用して、必要なデータを抽出します。たとえば、テーブル内のデータを抽出する場合は、find_allメソッドやCSSセレクタを使用して対象の要素を取得します。
5.データを保存するか処理する:
抽出したデータを必要に応じて保存したり、さらなる処理を行ったりすることができます。たとえば、CSVファイルにデータを保存する場合は、csvモジュールを使用します。
まとめ
今回は、WebスクレイピングツールOctoparseを使って過去の競馬レース結果をスクレイピングする方法を解説しました。紹介した方法を使えば、競馬のデータベース自由に取得できます。競馬の順位データは、ほぼテーブルで表示されるため、テーブルのスクレイピング方法をマスターすれば誰でも簡単に取得できますね。
Octoparseは初心者向けの「ユーザーガイド」を作成し、テストサイトを使って、スクレイピングのやり方を紹介しています。テーブルのスクレイピングデモもありますので、ぜひ参考にしてみてください。




