Webデータの抽出やデータ収集において、正規表現(Regular Expression, RegExp)は欠かせない基本スキルの一つです。一見難解に見える正規表現ですが、使い方を覚えれば、膨大なデータの中から必要な情報だけを的確に取り出せるようになります。
本記事では、正規表現の基本構文、具体的な使用例、さらに自動生成ツールの活用方法について解説します。処理の自動化や作業効率化のため、実務に役立つ正規表現の使い方を身につけましょう。
正規表現とは
正規表現とは、文字列のパターンを指定して検索や置換を行うための記述方法です。主にテキストデータの検索や抽出、置換などに用いられ、文字列処理の効率を大きく高める手段として活用されています。
はじめに、正規表現のユースケースや注意すべきポイントを解説します。
正規表現を使うユースケース
正規表現は、一定のパターンに従う文字列を抽出・検出する処理に多く使われます。
具体的には以下のようなケースがあります。
- ECサイトの商品ページから価格情報(例:¥1,980)のみを取り出す
- 商品レビュー文から日付(例:2024/12/01)を抽出する
- 電話番号のハイフンを除いた形式で成形する(例:09012345678)
- メールアドレス形式の文字列を検出(例:user@example.com)
- 複数行にまたがる住所情報の末尾にある「丁目」「番地」を抽出
このように、手作業では非効率でミスが起きやすい処理も、正規表現を活用すればルールに沿って自動化でき、精度と作業効率を大きく高めることが可能です。
正規表現を使う際に注意すべきポイント
正規表現は便利な一方で、注意すべき点もあります。
- 抽出結果がイメージとズレることがある
正規表現で指定したつもりのパターンでも、前後の不要な文字が一緒に抽出されてしまうことがあります。例えば「価格:¥1,980」から数値だけを取りたいのに「¥」まで含まれてしまうなど、細かな調整が必要になります。
- 利用する環境によって使える表現が異なる
正規表現の構文や対応機能は、Excel、Webツール、プログラミング言語などで差異があり、同じ表現でも動作しない場合があります。
- メンテナンスが難しい
正規表現は複雑になりやすく、第三者が読みにくくなる場合があります。なるべく簡潔に、必要であればコメントで補足しておきましょう。
このように、正規表現を使う際は、丁寧に検証・記述することが大切です。
正規表現の記述方法
正規表現を使いこなすためには、記述ルールの理解が重要です。
本章では、よく使われる記述方法や位置指定の方法を解説します。
基本的な正規表現
代表的な記述パターンは次の通りです。
| 文字 | 意味 |
| \d | 数字をマッチ |
| \D | 非数字をマッチ |
| \s | 空白文字 |
| \S | 空白文字以外の1文字 |
| \w | アルファベット、アンダーバー、数字 |
| \W | アルファベット、アンダーバー、数字以外の文字 |
| p{Lower} | 英文の小文字 |
| . | 任意の1文字 にマッチします |
| * | 直前の文字が0回以上繰り返される場合にマッチ |
| + | 直前の文字が1回以上繰り返される場合にマッチ |
| ? | 直前の文字が0回または1回の場合にマッチ |
| {n} | 直前の文字がn回繰り返される場合にマッチ |
| {n,} | 直前の文字がn回以上繰り返される場合にマッチ |
| {n,m} | 直前の文字がn回以上、m回以下 のときにマッチ |
| [] | 角括弧に含まれるいずれか1文字にマッチ |
| [a-z]|[A-Z] [a-zA-Z] | aからz または AからZ |
| [A-Z&&[RFG]] | AからZ 且つ RFGの場合 |
特定の位置に対する正規表現
特定の位置にマッチさせたい場合には、「アンカー」と呼ばれる記号を活用します。
例えば、文字列の先頭や末尾、単語の境界を指定することで、意図した位置から文字抽出が可能です。
| 文字 | 意味 |
| ^ | 行の先頭にマッチ例:^abc は「abc」で始まる行に一致 |
| $ | 行の末尾にマッチ例:abc$ は「abc」で終わる行に一致 |
| \b | 単語の先頭か末尾にマッチ例:\bcat\b は「cat」という単語そのものに一致 |
スクレイピング、データ収集で使える正規表現
スクレイピングやデータ収集で使える正規表現は次の通りです。
| 意味 | 文字 |
| 全ての数字をマッチする | [0-9]+ |
| 空白文字を削除 | \s+ |
| 日付(YYYY-MM-DD) | \d{4}-\d{2}-\d{2} |
| 日付(YYYY.MM.DD) | 20\d{2}(([^\d]|/s|//|:)?\d{1,2}){5} |
| 日付(YYYY年MM月DD日) | [0-9]{4}年[0-9]{1,2}月[0-9]{2}日[\s\S]*[0-9]{2}:[0-9]{2} |
| 画像 | (?<=<img)(.+?)(?=>) |
| 画像(拡張子あり) | (?<=src=”)(.+?)(\.jpg|\.png|\.gif|\.bmp|\.jpeg) |
| 画像(複数の拡張子対応) | (?<=src=”)(.+?)(\.jpg|\.png|\.gif|\.bmp|\.jpeg|\.JPG|\.PNG|\.GIF|\.BMP|\.GIF) |
| 画像ファイル名抽出(.jpgのみ) | [^/]+\.jpg |
| 画像ファイル名抽出(複数の拡張子対応) | [^/]+(\.jpg|\.png|\.gif|\.bmp|\.jpeg) |
| 画像URL | (http:|https:|//)(.+?)(\.png|\.jpg|\.gif|\.bmp|\.jpeg) |
| 電話番号:000-000-0000 | \d{3,4}-\d{3,4}-\d{3,4} |
| \d{3}-\d{4}-\d{4} | |
| Email:(例えば:sheunszx-001@gmail.com) | ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ |
| 郵便番号 | ^\d{3}-\d{4}$ |
| URL | ^https?://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ |
正規表現の自動生成ツール | Octoparse
正規表現は便利である一方、記述が複雑になりやすく、初心者にとっては習得のハードルが高い場合があります。WebスクレイピングツールであるOctoparseでは、対象の文字列を選択するだけで正規表現パターンを自動生成できるツールを提供しています。
ここからは、Octoparse正規表現ジェネレーターについてご紹介します。
1. Octoparse正規表現ジェネレーターとは?
Octoparse正規表現ジェネレーターは、収集したい文字列を入力・設定することで、該当する正規表現を自動生成できるツールです。正規表現の記述に不慣れな場合は、Octoparseの正規表現作成・生成ツールを活用することで、効率的にパターンを作成できます。
2. 正規表現ジェネレーターの画面構成と各機能
ここでは、Octoparse正規表現ジェネレーターの画面や機能についてご紹介します。
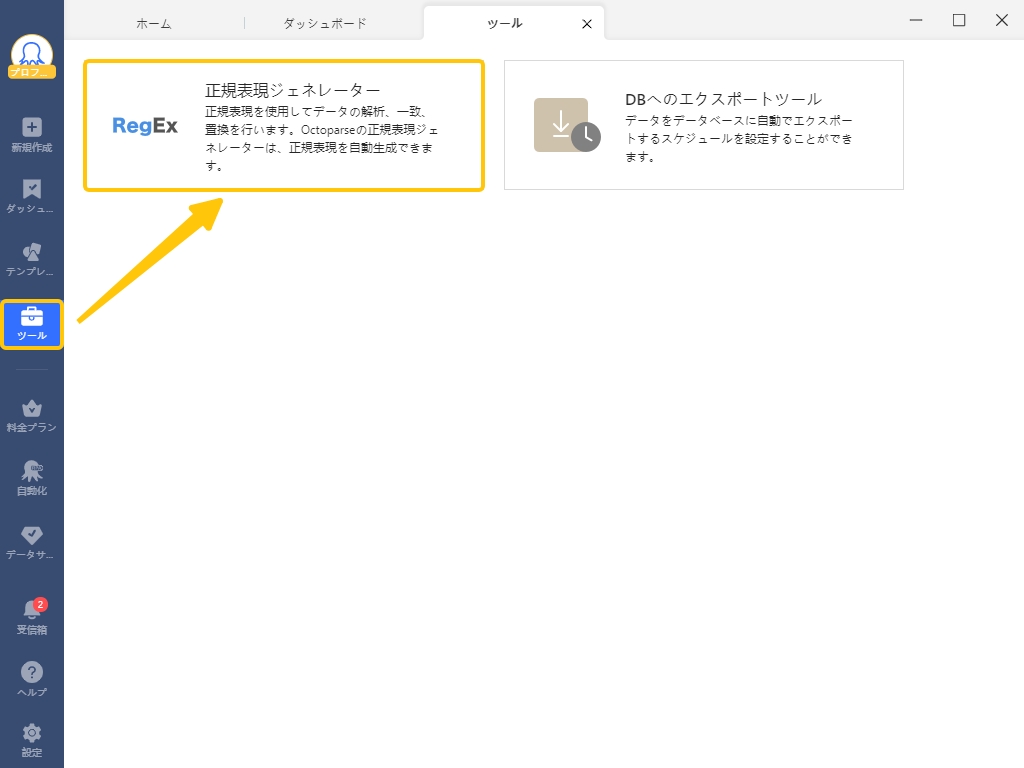
- 正規表現ジェネレーターの起動
- サイドバーメニューの下の「ツール」より正規表現ジェネレータを表示することができます。
- 正規表現ジェネレータの画面構成
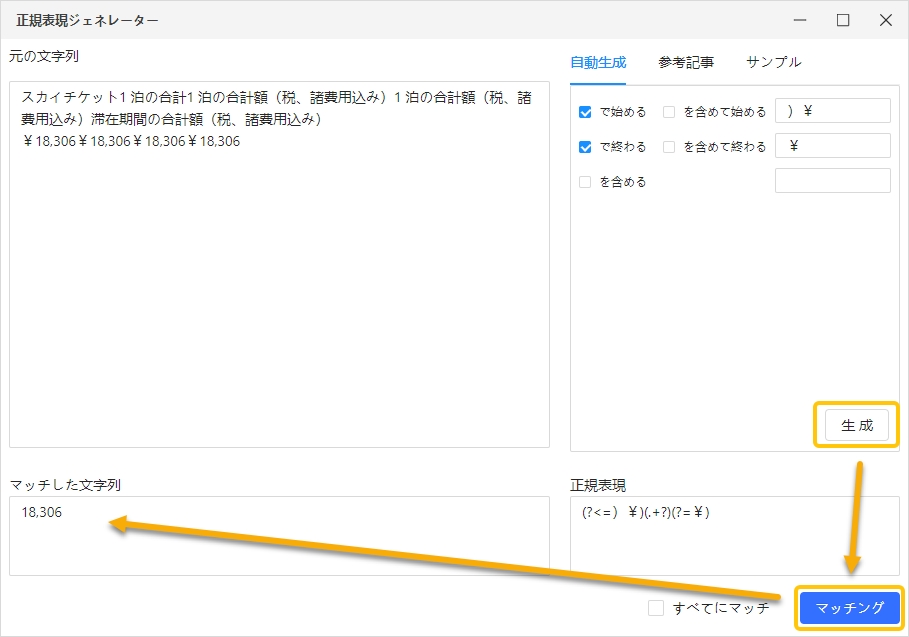
- 正規表現ジェネレーターのメインインターフェースは、4つのエリアで構成されています。
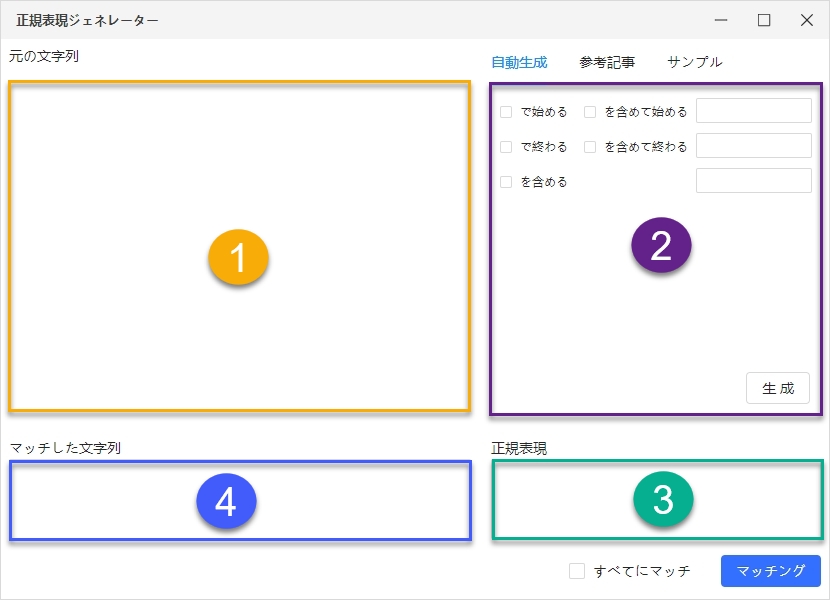
①元の文字列
「データを再フォーマット」オプション内から正規表現ジェネレーターを起動した場合は、抽出済みのテキスト文字列が自動的に表示されます。一方、サイドバーメニューからジェネレーターを開いた場合は、ソーステキスト欄に対象の文字列の入力または貼り付けを行います。
②自動生成/参考記事/サンプル
「自動生成」タブでは、各種オプションをチェック形式で選択でき、抽出したい文字列の条件を入力することで、正規表現を自動的に作成できます。
また、「参考記事」タブからは、W3Schoolsによる正規表現のチュートリアルにアクセスでき、基本的な構文や使い方を確認できます。「サンプル」タブでは、具体的なコード例が一覧で表示され、実際の用途に近い形式を参考にすることが可能です。
③正規表現
②の「生成」クリック後、本エリアに正規表現の構文が自動的に出力されます。特定のテキストだけでなく、すべての文字列にマッチさせたい場合は、「すべてにマッチ」のオプションを有効にします。
④マッチした文字列
③の「マッチング」ボタンをクリックすると、抽出された文字列を確認できます。
3. 正規表現ジェネレーターを使った抽出手順
Octoparseの正規表現ジェネレーターは、3つのステップで簡単に利用できます。
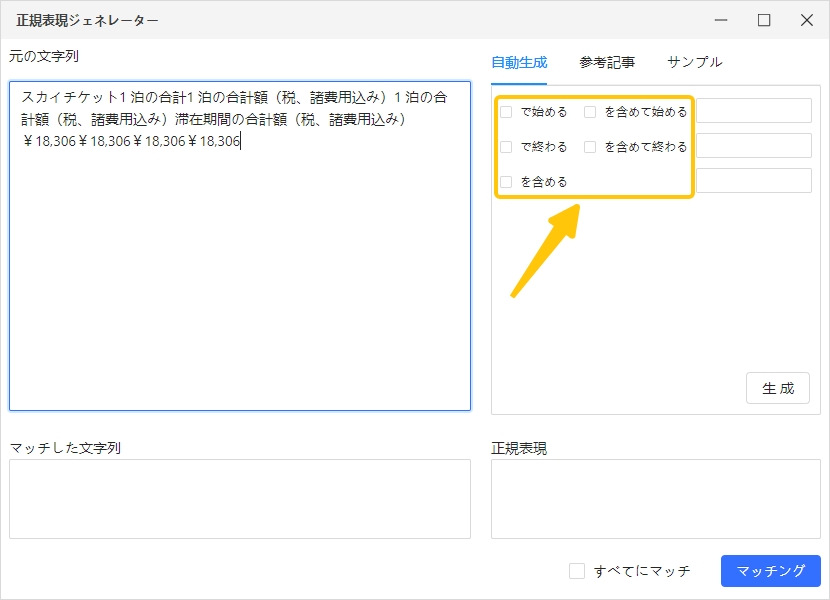
今回は、以下の文章から、「18,306」という文字列だけを抽出するケースを考えます。
| スカイチケット1 泊の合計1 泊の合計額(税、諸費用込み)1 泊の合計額(税、諸費用込み)滞在期間の合計額(税、諸費用込み)¥18,306¥18,306¥18,306¥18,306 |
ステップ1:「元の文字列」へ文章をコピー&ペースト
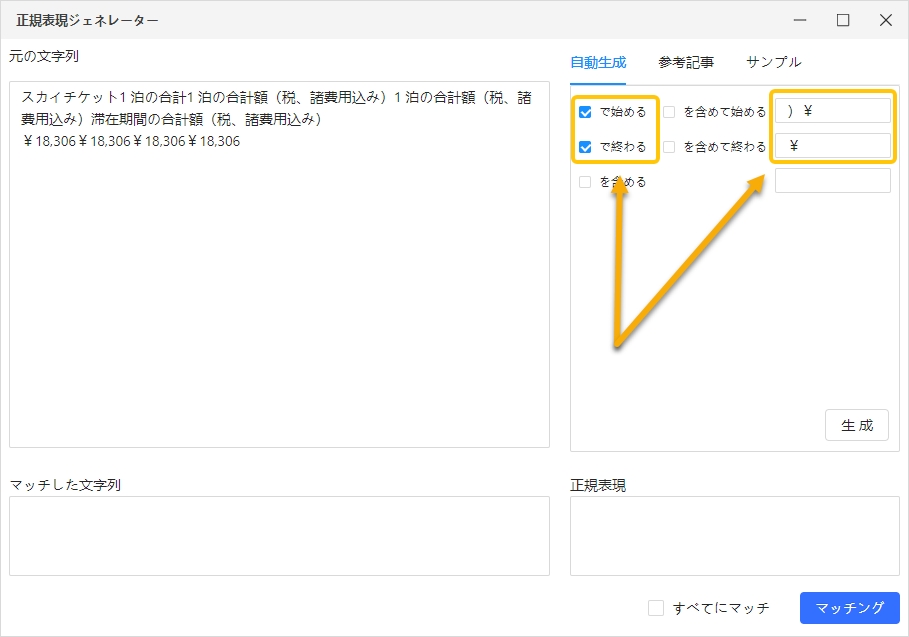
ステップ2:抽出条件を指定する
ここでは「18,306」を抽出しますので、「で始める」ボックスに「)¥」を、「で終わる」ボックスに「¥」を入力します。
ステップ3:正規表現を生成する
「生成」をクリックすると、正規表現の構文が自動で表示されます。最後に「マッチング」を押して、実際に一致した文字列が左側に表示されれば、意図した抽出が正しく行われたことが確認できます。
まとめ
本記事では、データ抽出でよく使われる正規表現の基本パターンと、正規表現を自動生成できるOctoparseの正規表現ジェネレータをついて紹介しました。Octoparseの正規表現ジェネレーターは、正規表現に不慣れな方でも簡単に文字列の抽出ルールを作成できます。
また、Octoparseはプログラミングの知識がなくても使えるスクレイピングツールとしても有用です。データ収集やスクレイピング業務を行う際は、ぜひ活用を検討してみてください。

ウェブサイトのデータを、Excel、CSV、Google Sheets、お好みのデータベースに直接変換。
自動検出機能搭載で、プログラミング不要の簡単データ抽出。
人気サイト向けテンプレート完備。クリック数回でデータ取得可能。
IPプロキシと高度なAPIで、ブロック対策も万全。
クラウドサービスで、いつでも好きな時にスクレイピングをスケジュール。



