「XPath」とは、Webサイトの特定の部分を効率的に識別し、データを抽出するための言語を指します。この技術は、Webクローラーやスクレイピングツールにおいて中心的な役割を担い、Pythonなどのプログラミング言語やOctoparseのようなツールを使用する際に不可欠です。
XPathの使い方を理解することで、目的のデータを正確かつ迅速に取得することが可能になります。
本記事では、XPathの基本的な概念を初心者にもわかりやすく解説し、実用的な書き方や役立つ関数について詳しくご紹介します。この記事を読むことで、XPathの基礎知識を身につけ、効果的なWebデータ収集のスキルを習得できるでしょう。
Xpathとは
そもそも「XPath」とは何を示すのかわからない方も多いでしょう。ここでは、XPathの基本概念や仕組みをかんたんに紹介します。
XPath (XML Path Language)は、XMLやHTMLドキュメントのツリー構造から特定の要素や属性値を選択するための言語です。これは特にWebページの情報取得において有用で、Webページは通常HTMLで記述されています。
Webデータの取得だけでなく、XMLデータの検索やXMLスキーマの検証など、様々な場面でXPathが活用されています。XMLなどの構造化データを効率的に特定し抽出するための汎用的な手法を提供しています。
ブラウザ(Chrome、Firefoxなど)を使用してWebページのHTMLを表示する際には、F12キーを押すことで対応するHTMLドキュメントに簡単にアクセスでき、XPathを利用して特定のデータを抽出することが可能です。
XPathの仕組み
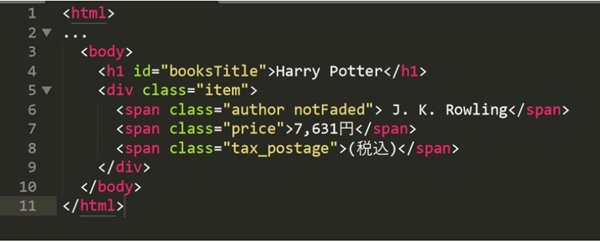
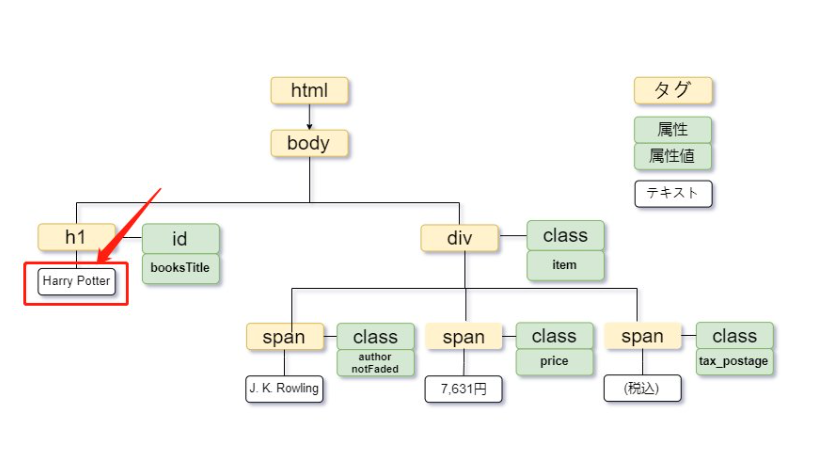
XPathは、XMLやHTMLドキュメントのツリー構造内の要素を指し示すために使用されます。例えば、下記の画像はHTMLドキュメントの一部です。
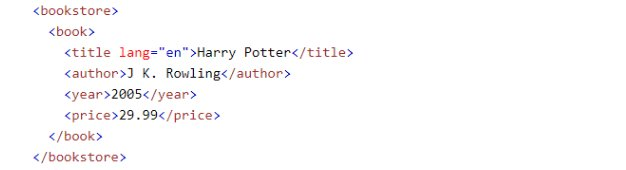
タグは通常、開始タグ(例:<book>)と終了タグ(例:</book>)で囲まれた間にコンテンツを含んでいます。XPathを用いてこれらの要素にアクセスする際には、スラッシュ(/)を使用して各レベルを区切り、特定の要素に到達します。
<例>
<tag>(開始タグ)ここにコンテンツが入ります… </tag>(終了タグ)
この方法は、ファイルシステムにおけるディレクトリのパスを指定する方法に似ています。
例えば、「author」という名前のファイルに到達するためのXPathは、次のようになります。
<例>

また、コンピューター上のすべてのファイルには独自のパスがあるように、Webページ上の要素もパスがあります。そのパスはXPathで記述されています。
ルート要素(ドキュメントの一番上の要素)から始まり、中にあるすべての要素を経由して目標要素に至るXPathは、絶対XPathと呼ばれます。しかし、絶対XPathは非常に長く複雑になる可能性があります。
<例>
そのため、より短い形式を使用することが一般的で、// を使って絶対パスを省略し、任意のレベルから始めることが可能です。これにより、//author のように単純化して記述できます。
必要な要素を直接指定することで、文書の構造が変わっても柔軟に対応できるため、ぜひ覚えておきましょう。例えば、「author」に到達するには次のように指定できます。
<例>
- 絶対XPath:/bookstore/book/author
- 短いXPath://author
XPathを表示させる方法
XPathを表示させる方法はブラウザによって異なります。ここではブラウザごとGoogleChromeを使ったXPathの表示方法を解説します。
Google ChromeでWebページを表示し、任意のHTML要素を右クリックして[検証]を選ぶことで開発者ツールが開きます。Elementsタブにて、特定の要素を右クリックすると、[Copy]メニューから[Copy XPath]を選択すると、その要素のXPathがクリップボードにコピーされます。
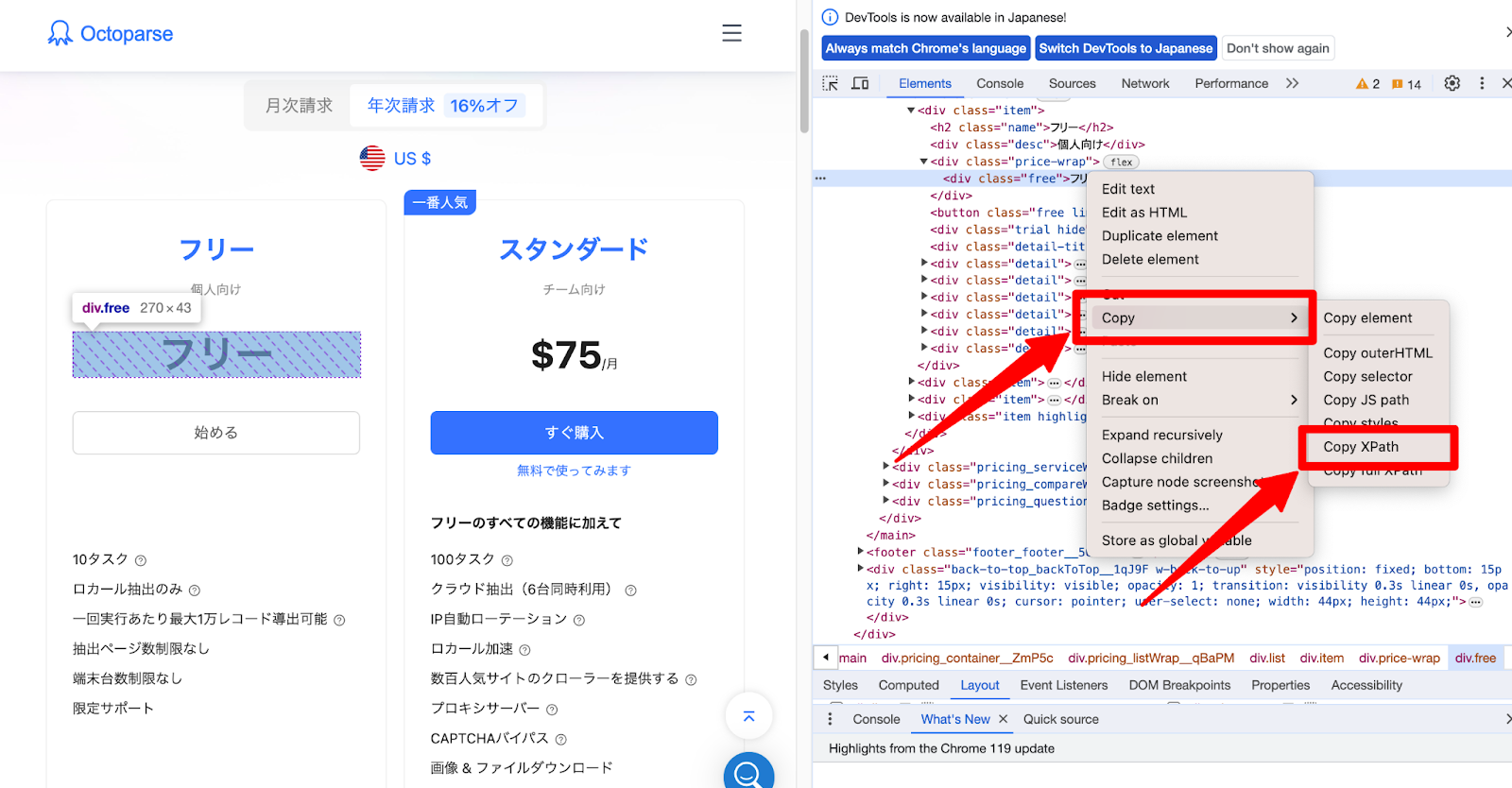
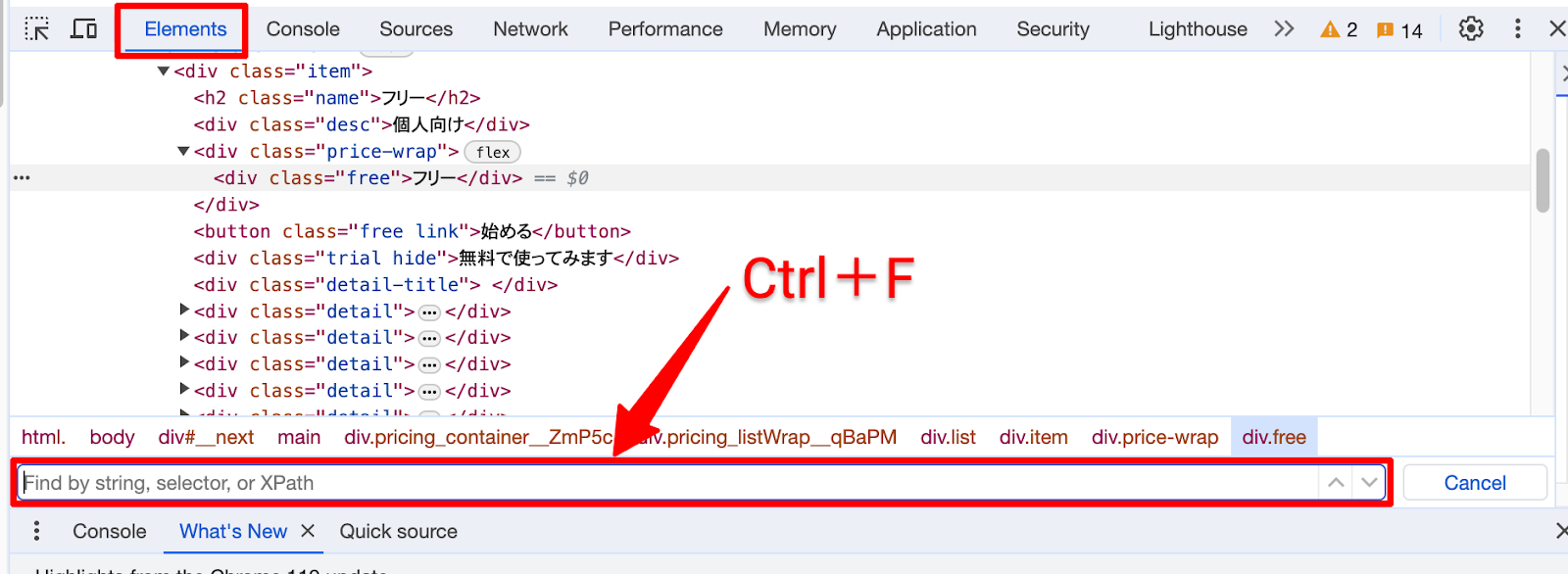
続いてElementsタブで「Ctrl + F」を使用して検索バーを開き、XPathを入力すると、ドキュメント内で対応する要素がハイライトされます。
また、Chromeには「XPath Helper」という拡張機能があり、XPathを入力すると一致するノードがハイライトされます。XPath Helperをインストールすることで、XPathのテストと確認が容易になりますので、ぜひ試してみてください。
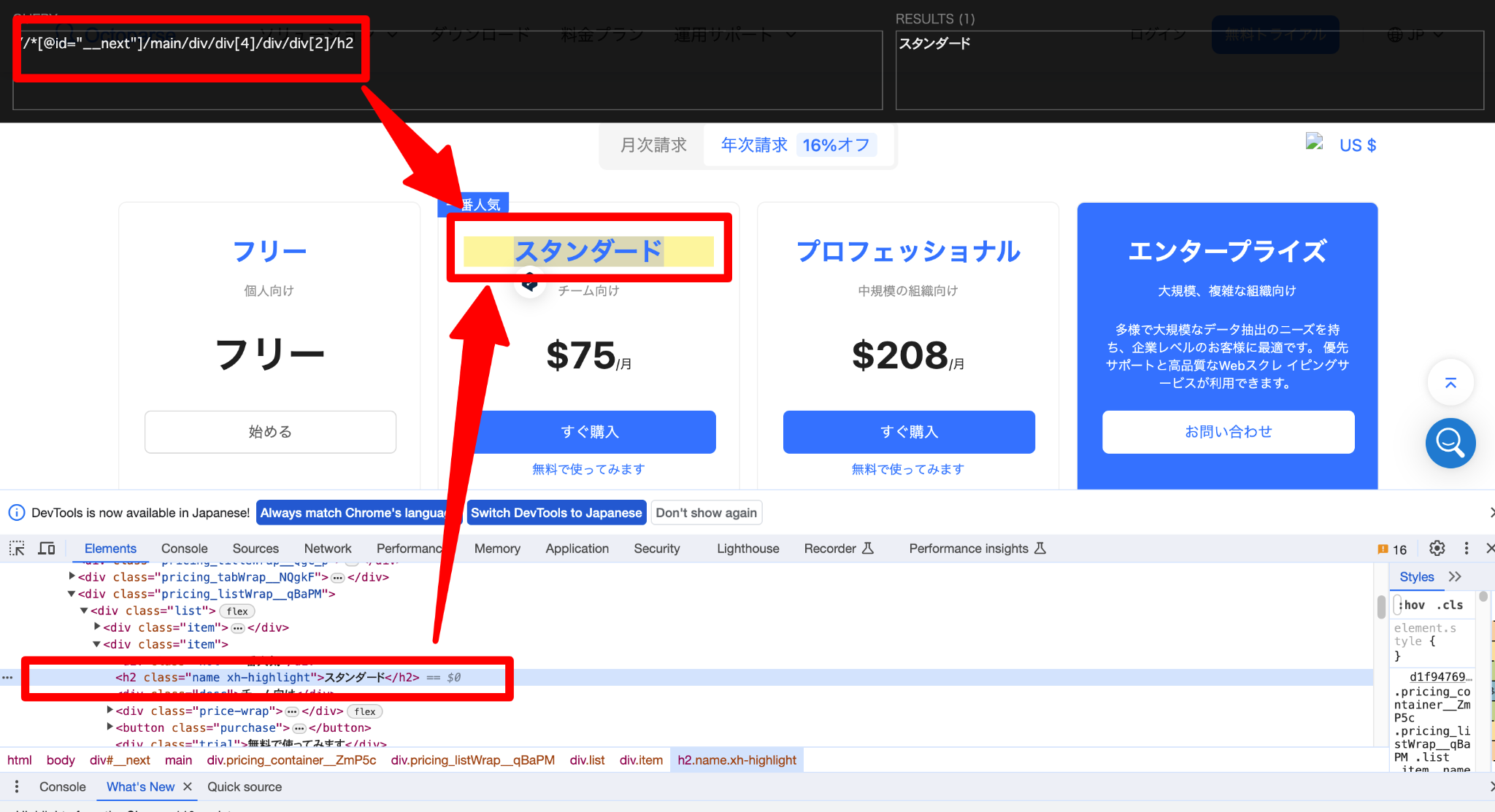
XPathの書き方
ここでは、XPathの書き方として、XPathを使用してHTMLドキュメントからデータを指定し、取得する方法を紹介します。
1.タグ(要素)による指定
HTMLドキュメントには、タグと呼ばれる< >と</ >に囲まれた記号があります。タグは要素の開始と終了を示し、タグ名には様々な種類があります。例えば、<a>はリンク、<p>は段落、<div>はコンテンツのブロックを表します。
//book ではすべての book ノードが、//book/author ではすべてのbookノードの子ノードであるauthorが選択されます。
HTMLドキュメントでは、これらのタグが特定の要素を形成し、色によって区別されることがあります(例: Firefoxでは青色、Chromeでは紫色)。
以下はHTMLでよく用いられるタグの一覧です。さらに詳しく知りたい方は、HTML Living Standard 要素一覧もあわせてご覧ください!
| タグ | 説明 |
| <a> </a> | リンクを設定する |
| <p> </p> | 段落を表す |
| <div> </div> | 特定の範囲をグループ化する |
| <li> </li> | リストの項目を表す |
| <img> </img> | 画像を表示する |
| <table> </table> | 表を作る |
| <tr> </tr> | 表の行を表す |
| <td> </td> | 表の列を表す |
XPathでデータを取得する際には、/を使ってツリー構造に沿って要素を指定します。
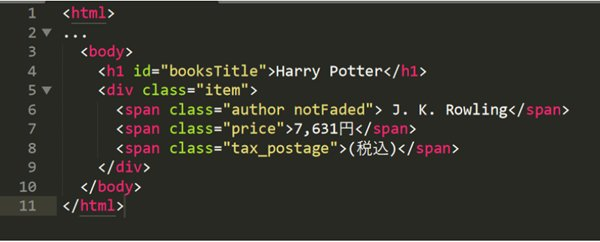
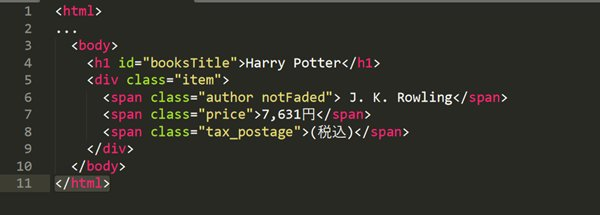
例えば、提供されたHTMLから”Harry Potter”のテキストを取得するには、次のパスを使用します。
さらに、//を用いると、特定のレベルを省略して直接要素を指定することも可能です。
複数の同じタグがある場合には、角括弧[]を使って特定の順番のタグを指定することができます。例えば、価格”7,631円”を取得したい場合、divタグの下の2番目のspanタグを指定するために次のように記述します。
一般的に、タグでXPathを書く構文は以下のようになります。
- 特定のタグを指定する: //タグ名
- 子孫タグを指定する://タグ名/タグ名
- 特定の順番のタグを指定する://タグ名[順番]
2.属性による指定
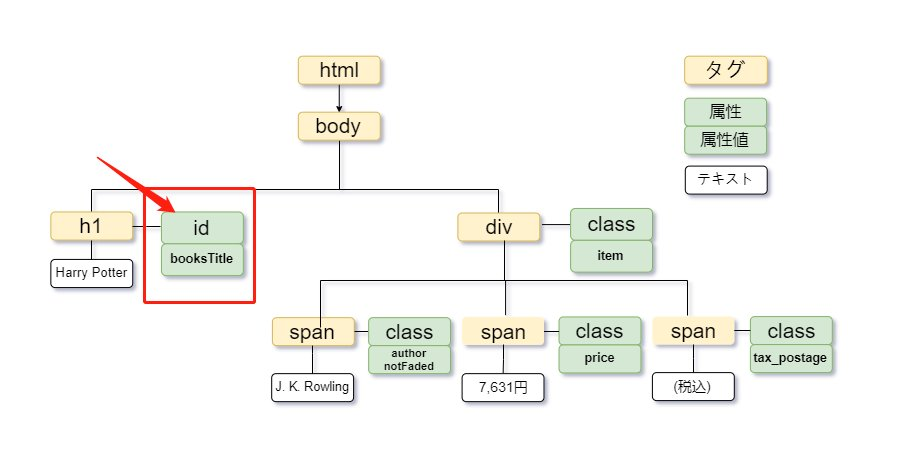
属性は、タグ内で定義され、タグに関する追加情報を提供するために使われます。属性を用いることで、要素に対して特定のスタイルや識別子を与えることができます。例えば、id=”booksTitle”という属性は、要素に一意の識別子を割り当てています。属性は一つのタグに複数設定することも可能です。
<タグ名 属性名=”属性値”>
一般的な属性としては、href(リンク先のURL)、title(ツールチップに表示されるテキスト)、style(インラインスタイル情報)、src(画像のソース)、id(要素の一意の識別子)、class(スタイルシートのクラス名)などがあります。
XPathでは、属性を「@」記号を使って指定します。たとえば、”Harry Potter”というテキストを含む要素を持つid属性を持つh1タグを取得するには、次のように記述します。
したがって、属性を使って特定のタグを指定する場合の一般的なXPathの構文は次のとおりです。
//タグ名[@属性名=”属性値”]
また、特定の属性値を持つどのようなタグも選択したい場合には、以下のように記述します。
//*[@属性名=”属性値”]
3.テキストによる指定
HTMLドキュメントでは、タグに囲まれた部分にテキストが含まれています。Webページからデータを取得する際、ページ内の特定のテキストコンテンツを直接指定して取得することがよくあります。
XPathでは、テキストノードを指定するためにtext()関数を使用します。例えば、「Harry Potter」というテキストを含むh1タグを特定したい場合、次のXPathを使用します。
一般的なテキスト指定のためのXPathの構文は以下の通りです。
//タグ名[text()="取得するテキスト"]
また、特定のテキストを含むあらゆる要素を取得したい場合には、次のように記述します。
//*[text()="取得するテキスト"]
4.タグ関係で指定する
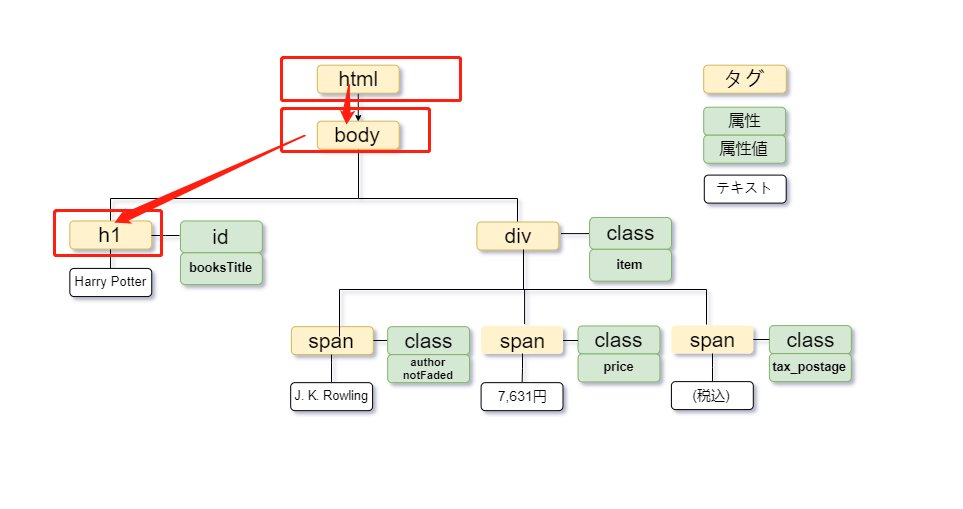
HTMLのツリー構造では、要素は親子や兄弟という関係性を持ちます。親要素は一つまたは複数の子要素を含み、子要素はその親要素の開始タグと終了タグの間に位置します。同じ親を共有する要素は兄弟要素です。
例えば、<body>要素は<h1>と<div>の親要素であり、これらは<body>の子要素です。<div>はさらに2つの<span>要素の親であり、これらの<span>要素は<body>の子孫要素です。<h1>と<div>は同じ<body>要素を共有する兄弟要素です。
XPathを用いて、これらの親子や兄弟の関係に基づいて要素を指定することができます。例えば、「7,631円」を取得するには、次のように記述します。
<div>の子要素を指定する場合:
<body>の子孫要素として指定する場合:
<span class=”author notFaded”>の直後の兄弟要素を指定する場合:
<span class=”tax_postage”>の直前の兄弟要素を指定する場合:
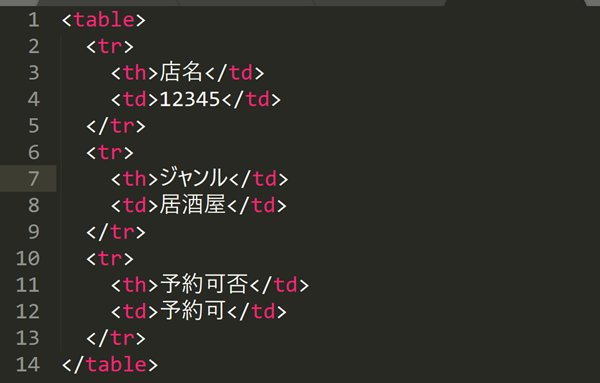
このHTMLをページに変更すると、以下のようなテーブルの形になります。
| 店名 | 12345 |
| ジャンル | 居酒屋 |
| 予約可否 | 予約可 |
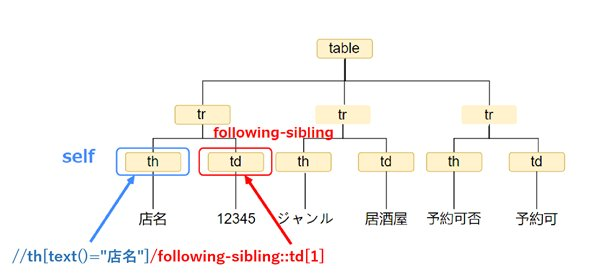
この例では、店名の『12345』を取得します。ただし、<td>要素が複数あり、//td[1]では対応できなくなります。したがって、テーブルの行を順に取得する際にはfollowing-sibling::が有効です。
例えば、「店名」の直後の<td>要素のテキストを取得するには以下のように記述します。
親子や兄弟関係に基づくXPathの抽象的な構文は以下の通りです。
| 親要素 | //基点要素のタグ名/.. |
| 子要素 | //基点要素のタグ名/子要素のタグ名 |
| 子孫要素 | //基点要素のタグ名//子孫要素のタグ名 |
| より後の兄弟要素 | //基点要素のタグ名/following-sibling::より後の兄弟要素のタグ名 |
| より前の兄弟要素 | //基点要素のタグ名/preceding-sibling::より前の兄弟要素のタグ名 |
もし上記の構文で複数に合致する場合に、[N]を付けてN番目のタグを指定することができます。
XPathによく使う関数
この部分では、より正しくデータを指定するには、XPathによく使う関数を紹介します。
1. contains() :特定の文字列が含まれる要素を指定する
contains() 関数: この関数は属性値やテキストに特定の文字列が含まれているかどうかを判定するのに使用されます。
contains(@attr, ‘value’)とすれば、attrという属性値に’value’という文字列が含まれるノードを選択できます。
contains(@class, ‘XXX’) :属性値に特定の文字列が含まれている要素を指定します。
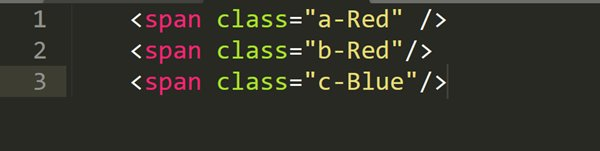
例えば、クラス属性に”Red”を含むすべてのspan要素を選択するには、以下の式を用います。
つまり、このXPathは、classにRedを含むspan要素を取得するという意味になります。
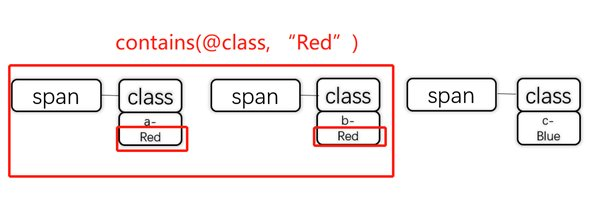
contains(text(),”XXX”) :テキストに特定の文字列が含まれる要素を指定します。
例えば、このHTMLから『Rowling』という文字を含んでいる要素を指定したい場合は、次のように書きます。
以上のように、contains()関数を使うことで、属性値やテキストに特定の文字列が含まれているノードを柔軟に抽出することができます。
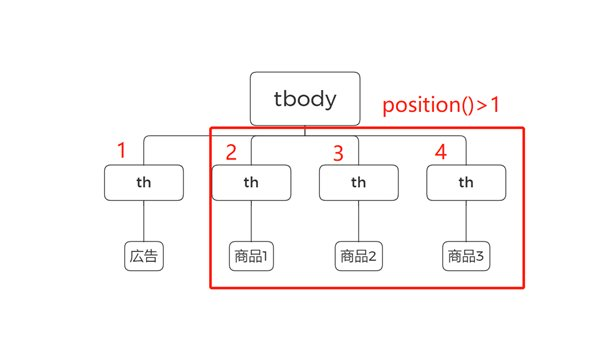
2. position():特定位置の要素を指定する
position() 関数: 要素の順序を指定する際に用います。position()=NはN番目の要素を選択し、position()>NはN番目を超えるすべての要素を選択します。
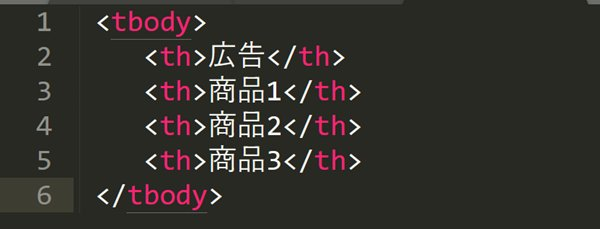
例えば、”広告”を除くすべてのth要素を選択するには、を使用します。
position()=を使う場合は、次のように書きます。
『広告』以外の要素を取得する場合、『広告』は1番目のth要素であるため、次のように書きます。
3. and/not/or:複数の条件が含まれている要素を指定する
論理関数 and、not、or:これらの関数は複数の条件を組み合わせて要素を選択する場合に便利です。
and関数
and は複数の条件を全て満たす要素を選択します。
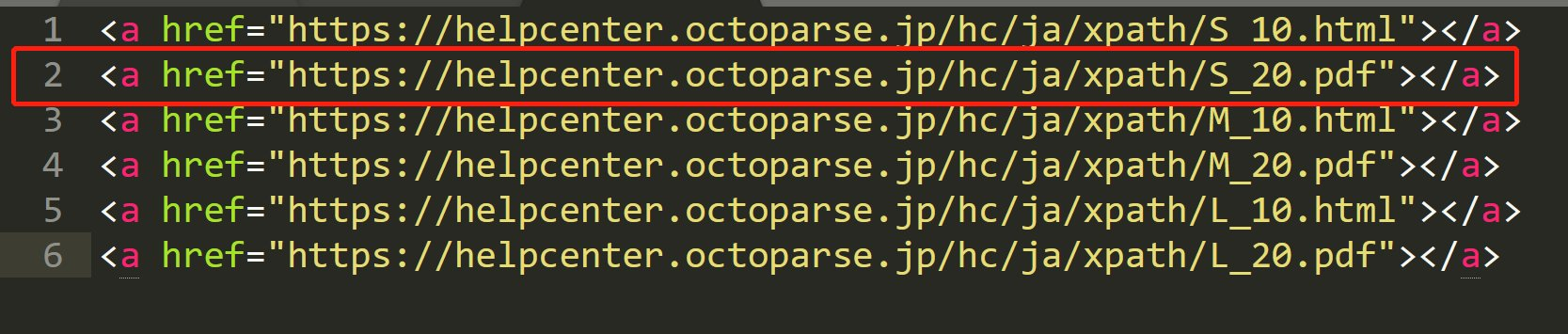
このHTMLから、『S_20』と『pdf』を含むhrefを取得したい場合は、次のように書きます。
not関数
not は特定の条件を満たさない要素を選択します。
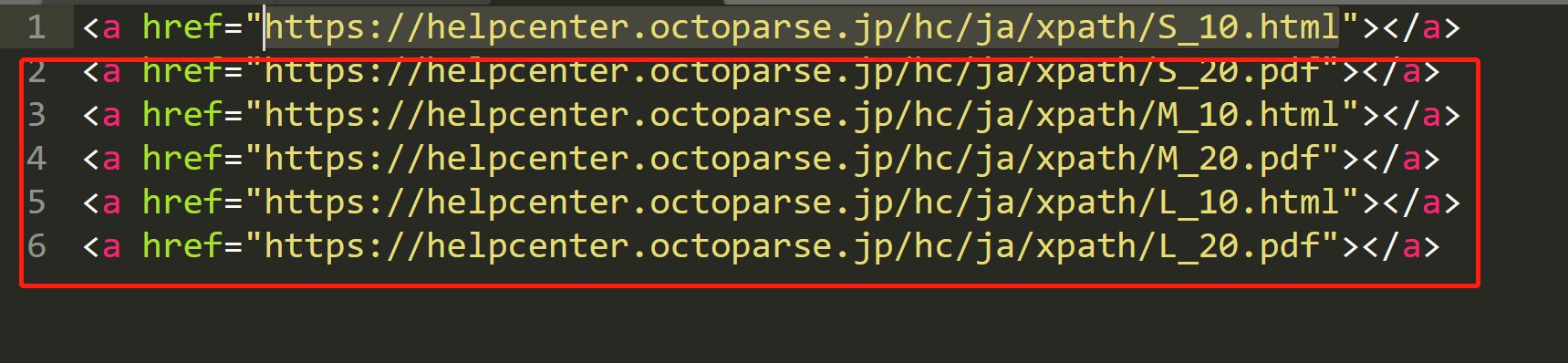
このHTMLから『S_10.html』を含まないhref属性を持つ要素を取得したい場合は、次のように書きます。
or関数
or はいずれかの条件を満たす要素を選択します。

このHTMLから、MかLを含むhrefを取得したい場合は、次のように書きます。
また、MかL以外のhrefを取得したい場合は、notとorを組み合わせると、次のようになります。
その他の一般的な関数
上記以外にも便利な関数があります。
- string(node) ノードをテキスト化
- concat(str1, str2…) 文字列を結合
- normalize-space(str) 連続する空白を1つのスペースに置き換え
- starts-with(str1, str2) str1がstr2で始まるかチェック
これらの関数を組み合わせることで、非常に精巧なXPathクエリを作成することができます。もしXPathの構文・関数をもっと詳しく知りたい方は、この記事をあわせてご覧ください。
XPathを使ってデータ取得する際の注意点
実際にXPathを使ってデータ取得する際は、以下の点にも留意が必要です。
- XML名前空間への対応 ((node[namespace-uri()=’https://example.com’ and local-name()=’book’]など)”)
- パスの曖昧さ回避 (一意に特定できる//div[@id=’content’]//h1など)
- ページの動的レンダリングへの配慮、完全な読み込みを待つ
- クロール規制に抵触しないための工夫(アクセス間隔の調整など)
まとめ
以上でXPathの基本についての紹介を終えます。XPathはWebスクレイピングにおいて強力なツールであり、習得すればデータ収集の作業を大幅に簡単にすることができます。
正規表現と組み合わせることで、さらに精度の高いデータ取得が可能となります。Webクローラーの開発に興味がある方は、ぜひXPathの学習を進めてみてください。

ウェブサイトのデータを、Excel、CSV、Google Sheets、お好みのデータベースに直接変換。
自動検出機能搭載で、プログラミング不要の簡単データ抽出。
人気サイト向けテンプレート完備。クリック数回でデータ取得可能。
IPプロキシと高度なAPIで、ブロック対策も万全。
クラウドサービスで、いつでも好きな時にスクレイピングをスケジュール。



